cassandra-stressツール
Cassandraクラスターの基本的なベンチマークおよび負荷テスト用のJavaベースのストレス・テスト・ユーティリティ。
cassandra-stressツールは、Cassandraクラスターの基本的なベンチマークおよび負荷テスト用のJavaベースのストレス・テスト・ユーティリティです。
cassandra-stressツールは、CQLテーブルとクエリーにクラスターおよびストレス・テストを追加するための効果的なツールです。cassandra-stressを使用することで以下のことが可能です。- スキーマの動作をすばやく確認する。
- データベースのスケール動作を理解する。
- データ・モデルと設定を最適化する。
- 実稼働キャパシティを確認する。
cassandra-stressツールは、さまざまなコンパクション・ストラテジ、キャッシュ設定、タイプの特定のスキーマを定義するためのYAMLベースのプロファイルもサポートします。サンプル・ファイルは以下の場所にあります。 - パッケージおよびInstaller-Servicesのインストール: /usr/share/docs/cassandra/examples
- tarボールおよびInstaller-No Servicesのインストール: install_location/tools/
YAMLファイルを使用せずに起動した場合、cassandra-stressは、keyspace1というキースペースを作成し、テストしているテーブル・タイプに応じて、standard1またはcounter1というテーブルを作成します。これらの要素は、ストレス・テストを最初に実行したときに自動的に作成され、その後の実行で再利用されます。keyspace1は、DROP KEYSPACEを使用して削除することができます。デフォルトのキースペースとテーブル名を変更するには、YAMLファイルを使用する必要があります。
- パッケージおよびInstaller-Servicesのインストール:
cassandra-stress command [options]
- tarボールおよびInstaller-No Servicesのインストール:
cd install_location/resources/cassandra/tools && bin/cassandra-stress command [options]
cassandra-stressオプション
| コマンド | 説明 |
|---|---|
| counter_read | カウンターの複数同時読み取り。まずcounter_writeテストでクラスターにデータを追加する必要があります。 |
| counter_write | カウンターの複数同時更新。 |
| help | ヘルプを表示します。cassandra-stress helpオプションのヘルプを表示します。 |
| legacy | レガシー・サポート・モード。 |
| mixed | 比率と分散が構成可能なインターリーブ基本コマンド。まずwriteテストでクラスターにデータを追加する必要があります。 |
| ディストリビューション定義の出力を検査します。 | |
| read | 複数の同時読み取り。まずwriteテストでクラスターにデータを追加する必要があります。 |
| user | 比率と分散が構成可能なインターリーブ・ユーザー提供クエリー。 |
| write | クラスターへの複数の同時書き込み。 |
$ cassandra-stress help option
helpコマンドを入力する際は、以下に示すように、オプション名の前にハイフンを入力するようにしてください。
Cassandra-stress sub-options
| サブオプション | 説明 |
|---|---|
| -col | サイズ、カウント分散、データ・ジェネレーター、名前、コンパレーターなどのカラム詳細情報。 使用法: -col names=? [slice] [super=?][comparator=?][timestamp=?][size=DIST(?)] or -col [n=DIST(?)][slice] [super=?][comparator=?][timestamp=?][size=DIST(?)] |
| -errors | ストレス・テスト時に発生したエラーの対処方法。 使用法: -errors [retries=N] [ignore] [skip-read-validation]
|
| -graph | cassandra-stressテストのグラフの結果。複数のテストをまとめてグラフ化できます。 使用法: -graph file=? [revision=?][title=?][op=?] |
| -insert | パーティション更新をバッチ化および分割するさまざまな方法に関する特定のオプションを挿入します。 使用法: -insert [revisit=DIST(?)][visits=DIST(?)] partitions=DIST(?)[batchtype=?] select-ratio=DIST(?) row-population-ratio=DIST(?) |
| -log | 進行状況および使用間隔のログを記録しておく場所。 使用法: -log [level=?][no-summary] [file=?][interval=?] |
| -mode | Thriftまたはオプション付きCQL 使用法: -mode thrift [smart] [user=?][password=?] or -mode native [unprepared] cql3 [compression=?][port=?][user=?][password=?][auth-provider=?][maxPending=?][connectionsPerHost=?] or -mode simplenative [prepared] cql3 [port=?] |
| -node | 接続先のノード。 使用法: -node [whitelist] [file=?] |
| -pop | 母集団分散およびパーティション間の訪問順序。 使用法: -pop seq=? [no-wrap] [read-lookback=DIST(?)][contents=?] or -pop [dist=DIST(?)][contents=?] |
| -port | Cassandraノードを接続するポートを指定します。ポートは、Cassandraネイティブ・プロトコル、Thriftプロトコル、または統計を取得するためのJMXポートについて指定できます。 使用法: -port [native=?][thrift=?][jmx=?] |
| -rate | 以下のオプションを使用してレートを設定します。
|
| -sample | レイテンシー測定時に収集するサンプルの数を指定します。 使用法: -sample [history=?][live=?][report=?] |
| -schema | レプリケーション設定、圧縮、コンパクションなど。 使用法: -schema [replication(?)][keyspace=?][compaction(?)][compression=?] |
| -sendto | このコマンドの送信先となるストレス・サーバーを指定します。 使用法: -sendToDaemon <host> |
| -transport | カスタム・トランスポート・ファクトリ。 使用法: -transport [factory=?][truststore=?][truststore-password=?][ssl-protocol=?][ssl-alg=?][store-type=?][ssl-ciphers=?] |
追加のコマンドライン・パラメーターを使用して、cassandra-stressの実行方法を変更できます。
追加のcassandra-stressパラメーター
| コマンド | 説明 |
|---|---|
| cl=? | cassandra-stress時に使用する整合性レベルを設定します。ONE、QUORUM、LOCAL_QUORUM、EACH_QUORUM、ALL、ANYのオプションがあります。デフォルトはLOCAL_ONEです。 |
| clustering=DIST(?) | 同じ種類の操作の分散クラスター実行。 |
| duration=? | 実行する時間を秒、分、または時間で指定します。 |
| err<? | 平均の標準誤差を指定します。この値に到達すると、cassandra-stressは終了します。デフォルトは0.02です。 |
| n>? | 不確定収束を受け入れる前に実行する最小実行回数を指定します。 |
| n<? | 不確定収束を受け入れる前に実行する最大実行回数を指定します。 |
| n=? | 実行する操作回数を指定します。 |
| no-warmup | プロセスをウォームアップせずにコールド・スタートを実行します。 |
| ops(?) | 実行する操作とそれぞれの頻度(userオプション使用時のみ)。 |
| profile=? | cassandra-stressとともに使用するYAMLファイルを指定します。(userオプション使用時のみ)。 |
| truncate=? | cassandra-stress時に作成されたテーブルを切り詰めます。オプションは、never、once、またはalwaysです。デフォルトはneverです。 |
単純な読み取りおよび書き込みの例
# Insert (write) one million rows $ cassandra-stress write n=1000000 -rate threads=50 # Read two hundred thousand rows.$ cassandra-stress read n=200000 -rate threads=50 # Read rows for a duration of 3 minutes.$ cassandra-stress read duration=3m -rate threads=50 # Read 200,000 rows without a warmup of 50,000 rows first.$ cassandra-stress read n=200000 no-warmup -rate threads=50
スキーマ・ヘルプの表示
$ cassandra-stress help -schema
replication([strategy=?][factor=?][<option 1..N>=?]): Define the replication strategy and any parameters
strategy=? (default=org.apache.cassandra.locator.SimpleStrategy) The replication strategy to use
factor=? (default=1) The number of replicas
keyspace=? (default=keyspace1) The keyspace name to use
compaction([strategy=?][<option 1..N>=?]): Define the compaction strategy and any parameters
strategy=? The compaction strategy to use
compression=? Specify the compression to use for SSTable, default:no compressionデータベースにデータを追加する
一般的には、cassandra-stressで作成した基本スキーマをCQLで編集します。
#Load one row with default schema $ cassandra-stress write n=1 cl=one -mode native cql3 -log file=create_schema.log #Modify schema in CQL $ cqlsh #Run a real write workload $ cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -log file=load_1M_rows.log
レプリケーション・ストラテジを変更する
レプリケーション・ストラテジをNetworkTopologyStrategyに変更して、existingという名前の1つのノードをターゲットにします。
$ cassandra-stress write n=500000 no-warmup -node existing -schema "replication(strategy=NetworkTopologyStrategy, existing=2)"
混在ワークロードを実行する
混在ワークロードを実行するときは、丸かっこ、不等号などの記号をエスケープさせる必要があります。この例では、1/4が書き込みで3/4が読み取りのワークロードを呼び出します。
$ cassandra-stress mixed ratio\(write=1,read=3\) n=100000 cl=ONE -pop dist=UNIFORM\(1..1000000\) -schema keyspace="keyspace1" -mode native cql3 -rate threads\>=16 threads\<=256 -log file=~/mixed_autorate_50r50w_1M.log
この例で以下のことに注目してください。
ratioパラメーターでは、バックスラッシュを使用して丸かっこをエスケープさせる必要があります。- 読み取りフェーズで使用される
nの値は、書き込みフェーズで使用される値とは異なります。書き込みフェーズでは、n個のレコードが書き込まれます。しかし、読み取りフェーズでは、nが大きすぎると、単純なテストですべてのレコードを読み取るのが不便になります。一般的に、クラスターの永続的な格納システムを検証するときには、nは大きくする必要はありません。-pop dist=UNIFORM\(1..1000000\)セクションは、n=100,000回の操作のうち、1と1,000,000の間で均等に分散しているキーを選択するという意味です。ノードあたりDRAMに入りきらない量のデータを指定したい場合にこれを使用します。 rateセクションでは、不等号記号をエスケープさせています。エスケープさせないと、シェルはその記号をIOリダイレクトに使用しようとします。つまり、シェルは存在しない=256というファイルからデータを読み取って、=16というファイルを作成しようとします。rateセクションは、cassandra-stressに自動的に異なる数のクライアント・スレッドをテストし、16未満または256を超えるクライアント・スレッドをテストしないように指示してします。
単一ノード用の標準的な混在する読み取り/書き込みワークロード・キースペース
CREATE KEYSPACE "keyspace1" WITH replication = {
'class': 'SimpleStrategy',
'replication_factor': '1'
};
USE "keyspace1";
CREATE TABLE "standard1" (
key blob,
"C0" blob,
"C1" blob,
"C2" blob,
"C3" blob,
"C4" blob,
PRIMARY KEY (key)
) WITH
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.000000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.100000 AND
replicate_on_write='true' AND
default_time_to_live=0 AND
speculative_retry='99.0PERCENTILE' AND
memtable_flush_period_in_ms=0 AND
compaction={'class': 'SizeTieredCompactionStrategy'} AND
compression={'class': 'LZ4Compressor'};異なるノード上の複数のcassandra-stressインスタンスに負荷を分散させる
この例では、1つのcassandra-stress負荷ジェネレーター・ノードがクラスターを飽和させない程度の大きさの負荷でクラスターに読み込む方法を示します。この例では、$NODESは10.0.0.1, 10.0.0.2のようにIPアドレスのリストをコンマで区切った値を持つ変数です。
#On Node1 $ cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1..1000000 -log file=~/node1_load.log -node $NODES #On Node2 $ cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1000001..2000000 -log file=~/node2_load.log -node $NODES
認証を使用してcassandra-stressを実行する
以下の例では、-modeオプションを使用してユーザー名とパスワードを指定する方法を示します。
$ cassandra-stress -mode native cql3 user=cassandra password=cassandra no-warmup cl=QUORUM
認証およびSSL暗号化を使用してcassandra-stressを実行する
以下の例では、-modeオプションを使用してユーザー名とパスワードを指定する方法と、SSLパラメーターに-transportationオプションを使用する方法を示しています。
$ cassandra-stress write n=100k cl=ONE no-warmup -mode native cql3 user=cassandra password=cassandra -transport truststore=/usr/local/lib/dsc-cassandra/conf/server-truststore.jks truststore-password=truststorePass factory=org.apache.cassandra.thrift.SSLTransportFactory keystore=/usr/local/lib/dsc-cassandra/conf/server-keystore.jks keystore-password=myKeyPass
cassandra-stressを実行する前に構成しておく必要があります。上記の例では、自己署名CA証明書を使用しています。truncateオプションを使用してcassandra-stressを実行する
このオプションは、modeオプションの前に挿入する必要があります。それ以外の場合、cassandra-stressツールは指定されたとおりにtruncateを適用しません。
以下の例は、truncateコマンドを示しています。
$ cassandra-stress write n=100000000 cl=QUORUM truncate=always -schema keyspace=keyspace-rate threads=200 -log file=write_$NOW.log
YAMLファイルを使用してcassandra-stressを実行する
cqlstress-example.yamlという名前のYAMLファイルを使用します。キースペース名と定義は、YAMLファイルの最初のエントリーです。keyspace: perftesting
keyspace_definition:
CREATE KEYSPACE perftesting WITH replication = { 'class': 'SimpleStrategy', 'replication_factor': 3};
table: users
table_definition:
CREATE TABLE users (
username text,
first_name text,
last_name text,
password text,
email text,
last_access timeuuid,
PRIMARY KEY(username)
);extra_definitionsセクションでは、テーブルにセカンダリ・インデックスまたはマテリアライズド・ビューを追加できます。
extra_definitions:
- CREATE MATERIALIZED VIEW perftesting.users_by_first_name AS SELECT * FROM perftesting.users WHERE first_name IS NOT NULL and username IS NOT NULL PRIMARY KEY (first_name, username);
- CREATE MATERIALIZED VIEW perftesting.users_by_first_name2 AS SELECT * FROM perftesting.users WHERE first_name IS NOT NULL and username IS NOT NULL PRIMARY KEY (first_name, username);
- CREATE MATERIALIZED VIEW perftesting.users_by_first_name3 AS SELECT * FROM perftesting.users WHERE first_name IS NOT NULL and username IS NOT NULL PRIMARY KEY (first_name, username);
columnspec:
- name: username
size: uniform(10..30)
- name: first_name
size: fixed(16)
- name: last_name
size: uniform(1..32)
- name: password
size: fixed(80) # sha-512
- name: email
size: uniform(16..50)
- name: startdate
cluster: uniform(20...40)
- name: description
size: gaussian(100...500)
partitions値は、テストで上記のカラム定義を使用し、各バッチのパーティションに固定数の行を挿入するように指示します。insert:
partitions: fixed(10)
batchtype: UNLOGGEDqueries:
read1:
cql: select * from users where username = ? and startdate = ?
fields: samerow # samerow or multirow (select arguments from the same row, or randomly from all rows in the partition)cqlstress-example.yamlからcassandra-stressテストを実行する方法を示しています。$ cassandra-stress user profile=tools/cqlstress-example.yaml n=1000000 ops\(insert=3,read1=1\) no-warmup cl=QUORUM
- userオプションは、
profileパラメーターとoptパラメーターに必須です。 - profileパラメーターの値は.yamlファイルのパスとファイル名です。
- この例では、
-nは、実行されるバッチの数を指定します。 opsに指定された値は、実行する操作とそれぞれの回数を指定します。これらの値は、insert行をデータベースに挿入するようコマンドに指示し、read1クエリーを実行します。回数については、1つのバッチにつき挿入またはクエリーがそれぞれカウントされ、
opsの値が実行される各タイプの回数を決定します。バッチの総数が1,000,000で、opsがクエリーごとに挿入を3回実行するように指示しているため、挿入数は750,000になり、read1クエリー数は250,000になります。ops値を指定する場合は、バックスラッシュによるエスケープを使用してください。
詳細については、「改良版Cassandra 2.1ストレス・ツール:あらゆるスキーマをベンチマーク – パート1」を参照してください。
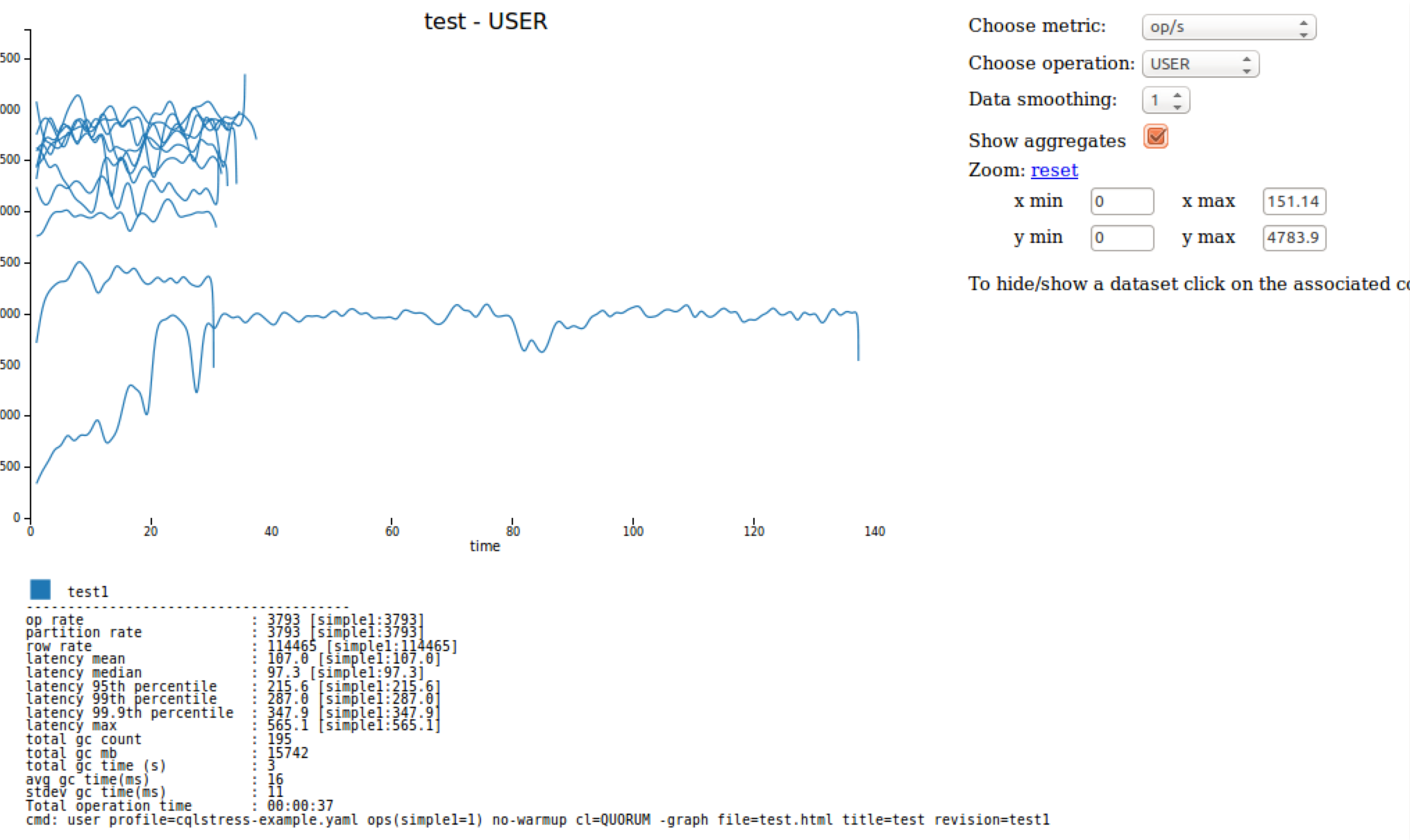
-graphオプションの使用
-graphオプションを指定すると、cassandra-stressテストの視覚的なフィードバックが生成されます。最終的なHTMLファイルを作成するには、ファイルに名前を付ける必要があります。titleとrevisionは任意ですが、同一の出力で複数のストレス・テストをグラフ化する場合は、revisionを使用する必要があります。$ cassandra-stress user profile=tools/cqlstress-example.yaml ops\(insert=1\) -graph file=test.html title=test revision=test1
Webブラウザーを使用して、対話型グラフを表示できます。