Calculating tokens
How to calculate tokens when using single-token architecture.
This topic contains information when using single-token architecture. You do not need to calculate tokens when using virtual nodes (vnodes).
When you start a DataStax Enterprise cluster, you must choose how the data is divided across the nodes in the cluster. A partitioner determines what each node stores by row. A token is a partitioner-dependent element of the cluster. Each node in a cluster is assigned a token and that token determines the node's position in the ring and what data the node is responsible for in the cluster. The tokens assigned to your nodes need to be distributed throughout the entire possible range of tokens. Each node is responsible for the region of the ring between itself (inclusive) and its predecessor (exclusive). As a simple example, if the range of possible tokens is 0 to 100 and there are 4 nodes, the tokens for the nodes would be: 0, 25, 50, 75. This approach ensures that each node is responsible for an equal range of data.
Before the node is started for the first time, each node in the cluster must be assigned a token. Set the token with the initial_token property in the cassandra.yaml configuration file. Also, be sure to comment out the num_token property.
| Package installations | /etc/cassandra/cassandra.yaml |
| Tarball installations | install_location/resources/cassandra/conf/cassandra.yaml |
For more detailed information, see Database internals.
Calculating tokens for a single data center
For example, for 6 nodes in a single data center, the results for calculating tokens using the Murmur3Partitioner are:
[ '-9223372036854775808', '-6148914691236517206', '-3074457345618258604', '-2', '3074457345618258600', '6148914691236517202' ]
Calculating tokens for multiple racks in a single data center
If you have multiple racks in single data center, calculate the tokens for the number of nodes and then assign the tokens to nodes on alternating racks. For example: rack1, rack2, rack1, rack2, and so on. The image shows the rack assignments:
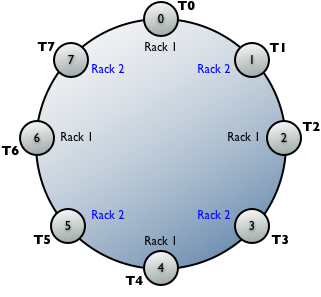
As a best practice, each rack should have the same number of nodes so you can alternate the rack assignments.
Calculating tokens for a multiple data center cluster
In multiple data center deployments using the NetworkTopologyStrategy, calculate the replica placement for your custom keyspaces per data center. The NetworkTopologyStrategy determines replica placement independently within each data center. The first replica is placed according to the partitioner. Additional replicas in the same data center are determined by walking the ring clockwise until a node in a different rack from the previous replica is found. If no such node exists, additional replicas are placed in the same rack.
Do not use SimpleStrategy for this type of cluster. There are different methods you can use when calculating multiple data center clusters. The important point is that the nodes within each data center manage an equal amount of data; the distribution of the nodes within the cluster is not as important. DataStax recommends using DataStax Enterprise OpsCenter to re-balance a cluster.
Alternating token assignments
Calculate the tokens for each data center and then alternate the token assignments so that the nodes for each data center are evenly dispersed around the ring. The following image shows the token position and data center assignments:
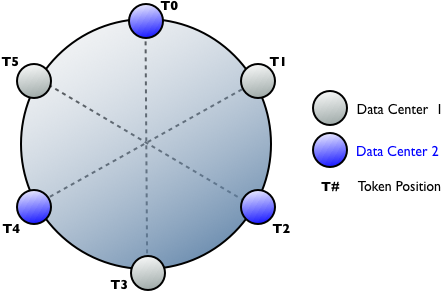
Avoiding token collisions
To avoid token collisions, offset the values for each token. Although you can increment in values of 1, it is better to use a larger offset value, such as 100, to allow room to replace a dead node.
The following shows the tokens for a cluster with two 3 node data centers and one 2 node data center.
['-9223372036854775808', '-3074457345618258603', '3074457345618258602']
['-9223372036854775808', '0']
Using an offset value of 100:
- Data Center
1
['-9223372036854775808', '-3074457345618258603', '3074457345618258602']
- Data Center
2
['-9223372036854775708', '-3074457345618258503', '3074457345618258702']
- Data Center 3
['-9223372036854775608', '200']