Mixing workloads in a cluster
About using real-time (Cassandra), Hadoop, or search (Solr) nodes in the same cluster.
A common question is how to use real-time (Cassandra), analytics (Hadoop), or search (Solr) nodes in the same cluster. Within the same data center, attempting to run Solr on some nodes and real-time queries or analytics on other nodes does not work. The answer is to organize the nodes running different workloads into virtual data centers.
Creating a virtual data center
Virtual data centers are a convenient way to organize work loads within clusters. When you create a keyspace using CQL, you can set up virtual data centers, independent of what physical data center the individual nodes are in. You assign analytics nodes to one data center, search nodes to another, and Cassandra real-time nodes to yet another data center. The separate, virtual data centers for different types of nodes segregate workloads running Solr from those running Cassandra real-time or Hadoop analytics applications. Segregating workloads ensures that only one type of workload is active per data center.
Workload segregation
- A Cassandra real-time application needs very rapid access to Cassandra
data.
The real-time application accesses data directly by key, large sequential blocks, or sequential slices.
- A DSE Search/Solr application needs a broadcast or scatter model to perform
full-index searching.
Virtually every Solr search needs to hit a large percentage of the nodes in the virtual data center (depending on the RF setting) to access data in the entire Cassandra table. The data from a small number of rows are returned at a time.
- Real-time queries (Cassandra and no other services)
- Analytics (Cassandra and Hadoop)
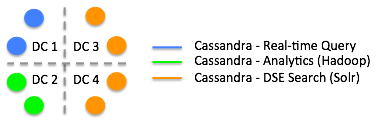
In separate data centers, some DSE nodes handle search while others handle MapReduce, or just act as real-time Cassandra nodes. Cassandra ingests the data, Solr indexes the data, and you run MapReduce against that data, all in one cluster without having to do any manual extract, transform, and load (ETL) operations. Cassandra handles the replication and isolation of resources.
The Solr nodes run HTTP and hold the indexes for the Cassandra table data. If a Solr node goes down, the commit log replays the Cassandra inserts, which correspond to Solr inserts, and the node is restored automatically.
The diagram shows the different types of node, even Analytics and Cassandra nodes, in separate data centers. Separating Analytics and Cassandra nodes is not mandatory as it is between Solr and the other node types. Separating all workloads is typically, but not always, recommended by DataStax. Occasionally, there is a use case for keeping Analytics and Cassandra in the same data center. You do not have to have an one or more additional replication factors when nodes are in the same data center.
To deploy a mixed workload cluster, see Multiple data center deployment.
Restrictions
- For production use or for use with mixed workloads, do not create the keyspace using SimpleStrategy. SimpleStrategy will not work in mixed workload clusters running Solr. NetworkTopologyStrategy is highly recommended for most deployments because it is much easier to expand to multiple data centers when required by future expansion.
- Do not run Solr and Hadoop on the same node in either production or development environments.
- From Hadoop and Cassandra real-time clusters in multiple data centers, do not attempt to insert data to be indexed by Solr using CQL or Thrift. Run the CQL or Thrift inserts on a Solr node in its own data center.
Replicating data across data centers
You set up replication for Solr nodes exactly as you do for other nodes in a Cassandra cluster, by creating a keyspace. You can change the replication of a keyspace after creating it.