DSE Graph、OLTP、およびOLAP
DSE GraphにおけるOLTPとOLAPの関係について説明します。
オンライン・トランザクション処理(OLTP)は、トランザクションが小さいため、クエリー処理が非常に高速という特徴があります。OLTPは通常、データ入力トランザクション、データ取得トランザクションを指向するアプリケーションに使用されます。オンライン分析処理(OLAP)は、トランザクションが比較的少量であることが特徴です。OLAPは、一般的に、集められた履歴データを対象に複雑な計算を行う、データの多次元分析に使用されます。
OLTPアプリケーションでは、秒未満の応答速度を求められます。一方、OLAPアプリケーションではクエリー終了まで長くかかります。 グラフ・データベースでは、OLTP探索は、グローバル・グラフの特定のサブグラフに局限されます。グラフ・データベースは、ランダム・アクセス・データ・システムです。OLAP探索では、グラフ内のすべての頂点を線形にスキャンします。OLTP探索は、サブグラフに対するスキャンを開始する前にインデックスを利用してグラフの特定の頂点に"ジャンプ"します。
OLTPクエリーは、グラフ全体の限定されたサブセットへのアクセスが必要な問い合わせに最適です。OLTPクエリーでは、フィルターを使用して、回答を見つけるために巡回する頂点の数を制限します。 DSE Graphでは、頂点が、その辺および隣接頂点と一緒に配置されます。インデックスを使用した探索でサブグラフが指定されている場合、ディスクに対する要求の数は、要求されたサブグラフの位置を特定してメモリーに書き込むために削減されます。メモリーに書き込まれると、辺沿いに頂点間を巡回します。
OLAPクエリーは、グラフに保存されているデータのかなりの部分にアクセスしなければならない問い合わせに適しています。上記の方法でOLAPクエリーを評価することは効率的ではないため、別のプロセスが使用されます。 OLAPクエリーが処理される際、グラフ全体は、それぞれ、単一の頂点とそのプロパティ、インシデント・辺、辺のプロパティから成るスター・グラフのシーケンスとして解釈されます。 スター・グラフは、すべてのスター・グラフが処理され、見つかったデータの集計が完了するまで1つのスター・グラフから次のスター・グラフへ直線的に処理されます。
これらの基本的原則を理解することが、グラフ・データに対するクエリーを実行するためのより良いグラフ探索の記述につながります。簡単な例でこの違いを説明します。"Julila Childが創作したレシピの数は?"という、食べ物に関するグラフを使用したクエリーを取り上げることにします。
g.V().in().has('name','Julia Child').count()
===>6
この探索では、すべての頂点を検索して内向き辺を巡回し、nameプロパティ・キーとJulia Childプロパティ値を持つ隣接頂点を見つけ、頂点数をカウントします。 返されるカウントには、レシピだけでなくJulia Childに対する辺を持つ頂点がすべて含まれます。後で示しますが、カウント数は不正確で大きすぎることに注意してください。gremlin> g.V().in().has('name','Julia Child').count().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep([],vertex) 61 61 6.733 17.52
query-optimizer 0.052
iterator-setup 0.015
DsegVertexStep(IN,vertex) 78 78 19.496 50.72
query-optimizer-total 0.328
iterator-setup-total 0.313
HasStep([name.eq(Julia Child)]) 5 5 12.147 31.60
CountGlobalStep 1 1 0.040 0.11
SideEffectCapStep([~metrics]) 1 1 0.022 0.06
>TOTAL - - 38.441 -
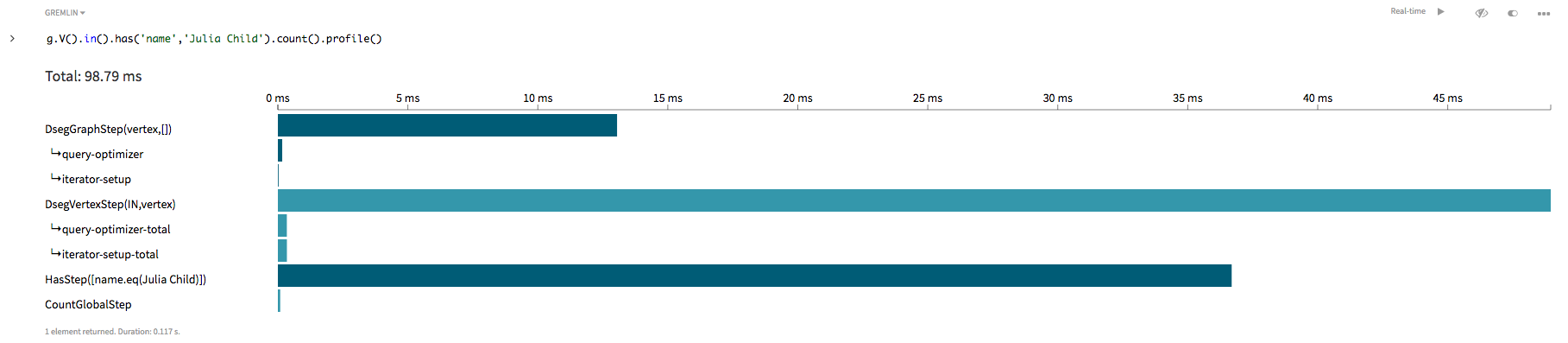
このグラフ探索は伝統的なOLAP探索です。この探索では、すべての頂点を訪問する必要があり、インデックスを使用しません。
g.V().in('created').has('name','Julia Child').count()
===>3
この変更した探索でも、すべての頂点が探索されますが、内向き辺の巡回に際しては、createdとラベル付けされた辺に制限されます。プロファイルを見ると、画像が改善されている様子がわかります。gremlin> g.V().in('created').has('name','Julia Child').count().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep([],vertex) 61 61 9.750 33.94
query-optimizer 0.075
iterator-setup 0.028
DsegVertexStep(IN,[created],vertex) 8 8 17.056 59.38
query-optimizer-total 0.732
iterator-setup-total 0.420
HasStep([name.eq(Julia Child)]) 3 3 1.856 6.46
CountGlobalStep 1 1 0.033 0.12
SideEffectCapStep([~metrics]) 1 1 0.028 0.10
>TOTAL - - 28.725 -
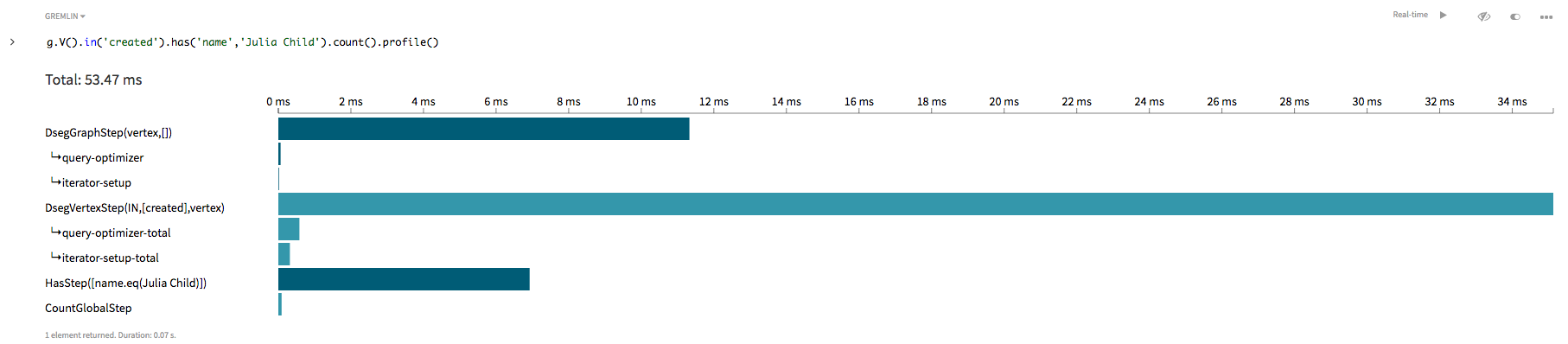
このグラフ探索は、依然として、すべての頂点を巡回するOLAP探索であり、インデックスを使用しません。
g.V().hasLabel('recipe').in().has('name','Julia Child').count()
===>3
この変更後の探索はrecipe頂点に制限されるようになりますが、すべての内向き辺を巡回します。このプロファイルを見ると、画像がいくらか改善されている様子がわかります。gremlin> g.V().hasLabel('recipe').in().has('name','Julia Child').count().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep([~label.eq(recipe)]) 8 8 7.940 28.76
query-optimizer 0.084
iterator-setup 0.011
DsegVertexStep(IN,vertex) 22 22 10.708 38.78
query-optimizer-total 0.093
iterator-setup-total 0.061
HasStep([name.eq(Julia Child)]) 3 3 8.784 31.81
CountGlobalStep 1 1 0.126 0.46
SideEffectCapStep([~metrics]) 1 1 0.053 0.19
>TOTAL - - 27.613 -
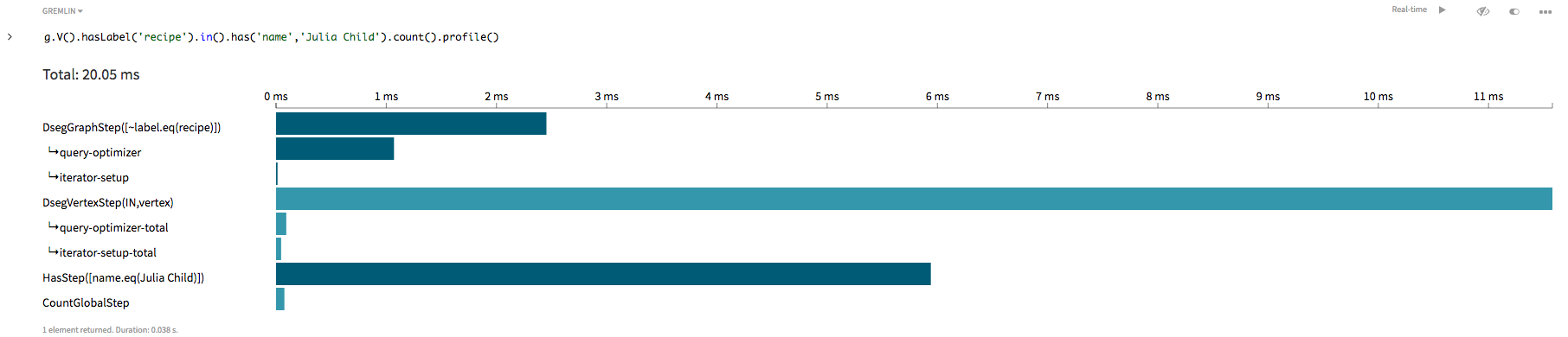
このグラフ探索は、依然として、インデックスを使用しないOLAP 探索です。次の例で説明するように、インデックスは頂点ラベルとプロパティ・キーによって識別されます。この探索は、まず、頂点ラベルに制限を加えることによってクエリーを絞り込みますが、探索の開始点の検出にインデックスは使用されません。
g.V().has('author', 'name', 'Julia Child').outE('created').count()
===>3
頂点ラベルauthorと具体的なプロパティ・キーの両方と値Julia Childを指定することによって、この探索は1つの頂点から開始され、辺ラベルcreatedを持つ外向き辺のみを巡回します。gremlin> g.V().has('author','name','Julia Child').outE('created').count().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep([~label.eq(author), name.eq(Julia... 1 1 2.248 77.28
query-optimizer 0.210
iterator-setup 0.013
DsegVertexStep(OUT,[created],edge) 3 3 0.618 21.25
query-optimizer 0.097
iterator-setup 0.008
CountGlobalStep 1 1 0.029 1.00
SideEffectCapStep([~metrics]) 1 1 0.013 0.47
>TOTAL - - 2.909 -
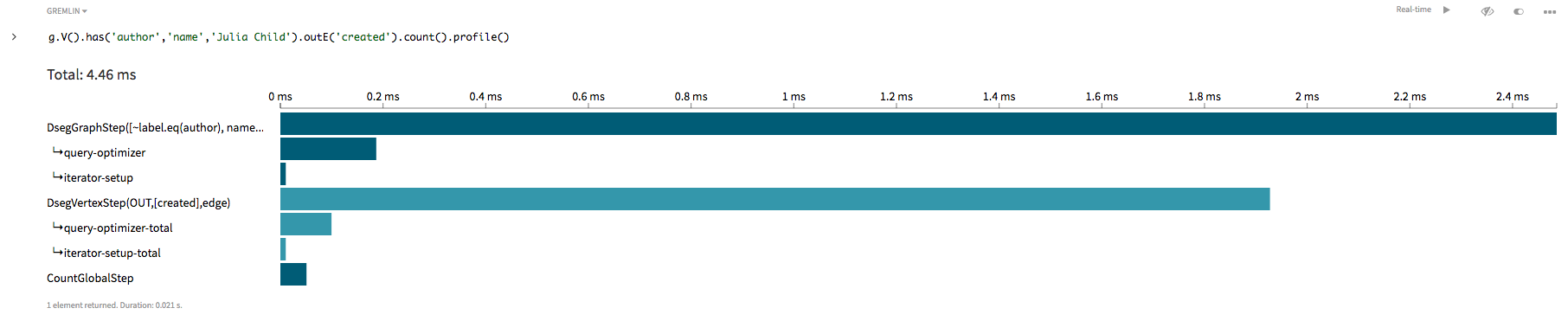
このグラフ探索はOLTP探索です。頂点ラベルauthorおよびプロパティ・キーnameに対するインデックスを使用すると、インデックスが付けられた頂点から探索を直に開始できます。この例の結果は単一の頂点ですが、インデックスを使用して開始点を複数の頂点に制限するクエリーは、グラフ内のすべての頂点をチェックしなければならない線スキャンよりも効率的です。したがって、サブグラフ(グラフの一部)を探索します。
OLTPグラフ探索を作成する鍵は、グラフの探索方法を検討することです。 インデックス作成の使用は、高速なトランザクション処理の成功に不可欠です。DSE Graphに付属しているプロファイリング・ツールは、探索の実行方法の分析に役立ちます。
Sparkを使用したOLAPクエリーの実行の詳細については、DSE GraphおよびGraph Analyticsを参照してください。