When a query contains no restrictions on clustering or index columns, all the data from the partition is returned.
How order impacts clustering restrictions
Because the database uses the clustering columns to determine the location of the data on the partition, you must identify the higher level clustering columns definitively using the equals (=) or IN operators. In a query, you can only restrict the lowest level using the range operators (>, >=, <, or <=).
How data is stored
The following table is used to illustrate how clustering works:
CREATE TABLE cycling.numbers (
key int,
col_1 int,
col_2 int,
col_3 int,
col_4 int,
PRIMARY KEY ((key), col_1, col_2, col_3, col_4)
);The example table contains the following data:
key | col_1 | col_2 | col_3 | col_4
-----+-------+-------+-------+-------
100 | 1 | 1 | 1 | 1
100 | 1 | 1 | 1 | 2
100 | 1 | 1 | 1 | 3
100 | 1 | 1 | 2 | 1
100 | 1 | 1 | 2 | 2
100 | 1 | 1 | 2 | 3
100 | 1 | 2 | 2 | 1
100 | 1 | 2 | 2 | 2
100 | 1 | 2 | 2 | 3
100 | 2 | 1 | 1 | 1
100 | 2 | 1 | 1 | 2
100 | 2 | 1 | 1 | 3
100 | 2 | 1 | 2 | 1
100 | 2 | 1 | 2 | 2
100 | 2 | 1 | 2 | 3
100 | 2 | 2 | 2 | 1
100 | 2 | 2 | 2 | 2
100 | 2 | 2 | 2 | 3
(18 rows)The database stores and locates the data using a nested sort order. The data is stored in hierarchy that the query must traverse:
[json]
--------------------------------------------------------------
{"key": 100, "col_1": 1, "col_2": 1, "col_3": 1, "col_4": 1}
{"key": 100, "col_1": 1, "col_2": 1, "col_3": 1, "col_4": 2}
{"key": 100, "col_1": 1, "col_2": 1, "col_3": 1, "col_4": 3}
{"key": 100, "col_1": 1, "col_2": 1, "col_3": 2, "col_4": 1}
{"key": 100, "col_1": 1, "col_2": 1, "col_3": 2, "col_4": 2}
{"key": 100, "col_1": 1, "col_2": 1, "col_3": 2, "col_4": 3}
{"key": 100, "col_1": 1, "col_2": 2, "col_3": 2, "col_4": 1}
{"key": 100, "col_1": 1, "col_2": 2, "col_3": 2, "col_4": 2}
{"key": 100, "col_1": 1, "col_2": 2, "col_3": 2, "col_4": 3}
{"key": 100, "col_1": 2, "col_2": 1, "col_3": 1, "col_4": 1}
{"key": 100, "col_1": 2, "col_2": 1, "col_3": 1, "col_4": 2}
{"key": 100, "col_1": 2, "col_2": 1, "col_3": 1, "col_4": 3}
{"key": 100, "col_1": 2, "col_2": 1, "col_3": 2, "col_4": 1}
{"key": 100, "col_1": 2, "col_2": 1, "col_3": 2, "col_4": 2}
{"key": 100, "col_1": 2, "col_2": 1, "col_3": 2, "col_4": 3}
{"key": 100, "col_1": 2, "col_2": 2, "col_3": 2, "col_4": 1}
{"key": 100, "col_1": 2, "col_2": 2, "col_3": 2, "col_4": 2}
{"key": 100, "col_1": 2, "col_2": 2, "col_3": 2, "col_4": 3}
(18 rows)To avoid full scans of the partition and to make queries more efficient, the database requires that the higher level columns in the sort order (col_1, col_2, and col_3) are identified using the equals or IN operators. Ranges are allowed on the last column (col_4).
Selecting data from a clustering segment
For example, to find only values in column 4 that are less than or equal to 2:
SELECT * FROM cycling.numbers
WHERE key = 100 AND col_1 = 1 AND col_2 = 1 AND col_3 = 1 AND col_4 <= 2;Results
The results contain the first two rows:
key | col_1 | col_2 | col_3 | col_4
-----+-------+-------+-------+-------
100 | 1 | 1 | 1 | 1
100 | 1 | 1 | 1 | 2
(2 rows)The IN operator can impact performance on medium-large datasets. When selecting multiple segments, the database loads and filters all the specified segments.
For example, to find all values less than or equal to 2 in both col_1 segments 1 and 2:
SELECT * FROM cycling.numbers WHERE key = 100 AND col_1 = 1 AND col_2 > 1Results
The following visualization shows all the segments the database must load to filter multiple segments:
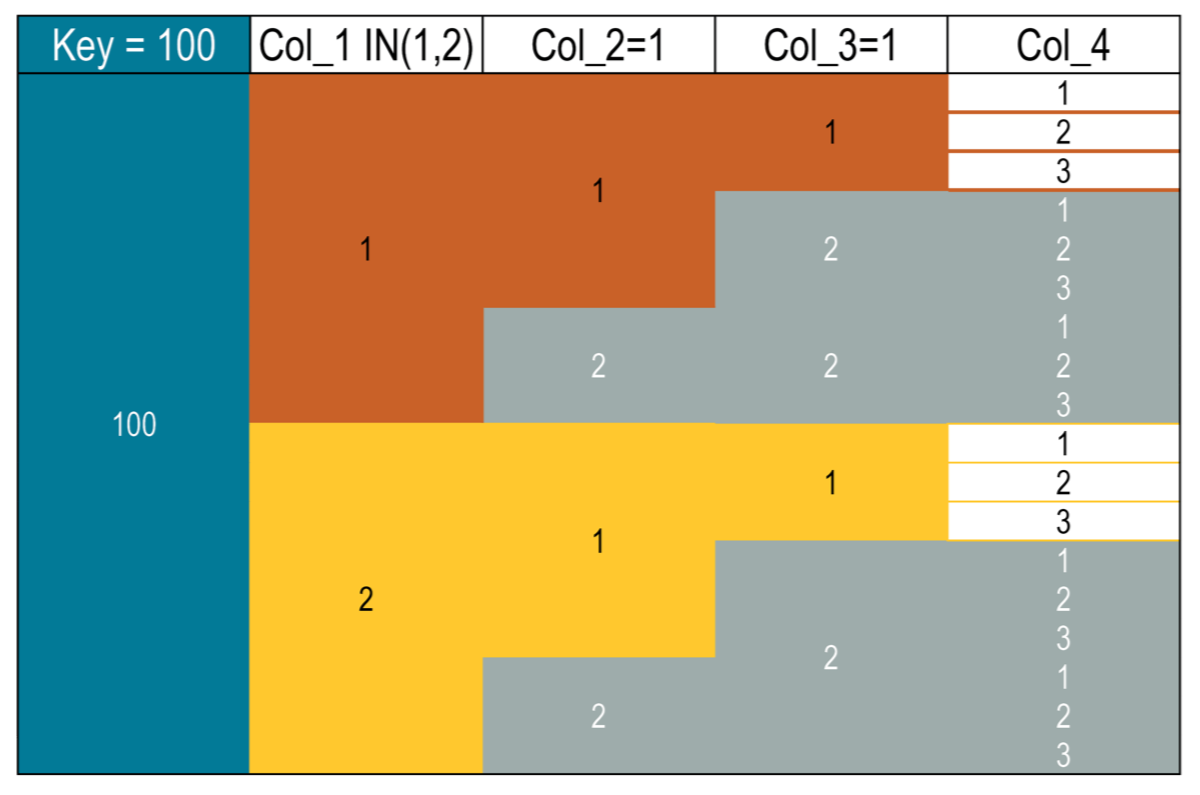
The results return the range from both segments.
key | col_1 | col_2 | col_3 | col_4
-----+-------+-------+-------+-------
100 | 1 | 2 | 2 | 1
100 | 1 | 2 | 2 | 2
100 | 1 | 2 | 2 | 3
(3 rows)|
Use TRACING to analyze the impact of various queries in your environment. |
Invalid restrictions
Queries that attempt to return ranges without identifying any of the higher level segments are rejected:
SELECT * FROM cycling.numbers WHERE key = 100 AND col_4 <= 2;Results
The request is invalid:
InvalidRequest: Error from server: code=2200 [Invalid query] message="PRIMARY KEY column "col_4"
cannot be restricted as preceding column "col_1" is not restricted"|
You can force the query using the ALLOW FILTERING option; however, this loads the entire partition and negatively impacts performance by causing long READ latencies. |
Only restricting top level clustering columns
Unlike partition columns, a query can omit lower level clustering column in logical statements.
For example, to filter one of the mid-level columns, restrict the first level column using equals or IN, then specify a range on the second level:
SELECT * FROM cycling.numbers WHERE key = 100 AND col_1 = 1 AND col_2 > 1Results
key | col_1 | col_2 | col_3 | col_4
-----+-------+-------+-------+-------
100 | 1 | 2 | 2 | 1
100 | 1 | 2 | 2 | 2
100 | 1 | 2 | 2 | 3
(3 rows)Returning ranges that span clustering segments
Slicing provides a way to look at an entire clustering segment and find a row that matches values in multiple columns. The slice logical statement finds a single row location and allows you to return all the rows before, including, between, or after the row.
Slice syntax:
(clustering1, clustering2[, …]) <range_operator> (value1, value2[, …])
[AND (clustering1, clustering2[, …]) <range_operator> (value1, value2[, …])]Slices across full partition
The slice determines the exact location within the sorted columns; therefore, the highest level is evaluated first, then the second, and so forth in order to drill down to the precise row location. The following statement identifies the row where column 1, 2, and 3 are equal to 2 and column 4 is less than or equal to 1.
SELECT * FROM cycling.numbers
WHERE key = 100 AND (col_1, col_2, col_3, col_4) <= (2, 2, 2, 1);The database locates the matching row and then returns every record before the identified row in the results set.
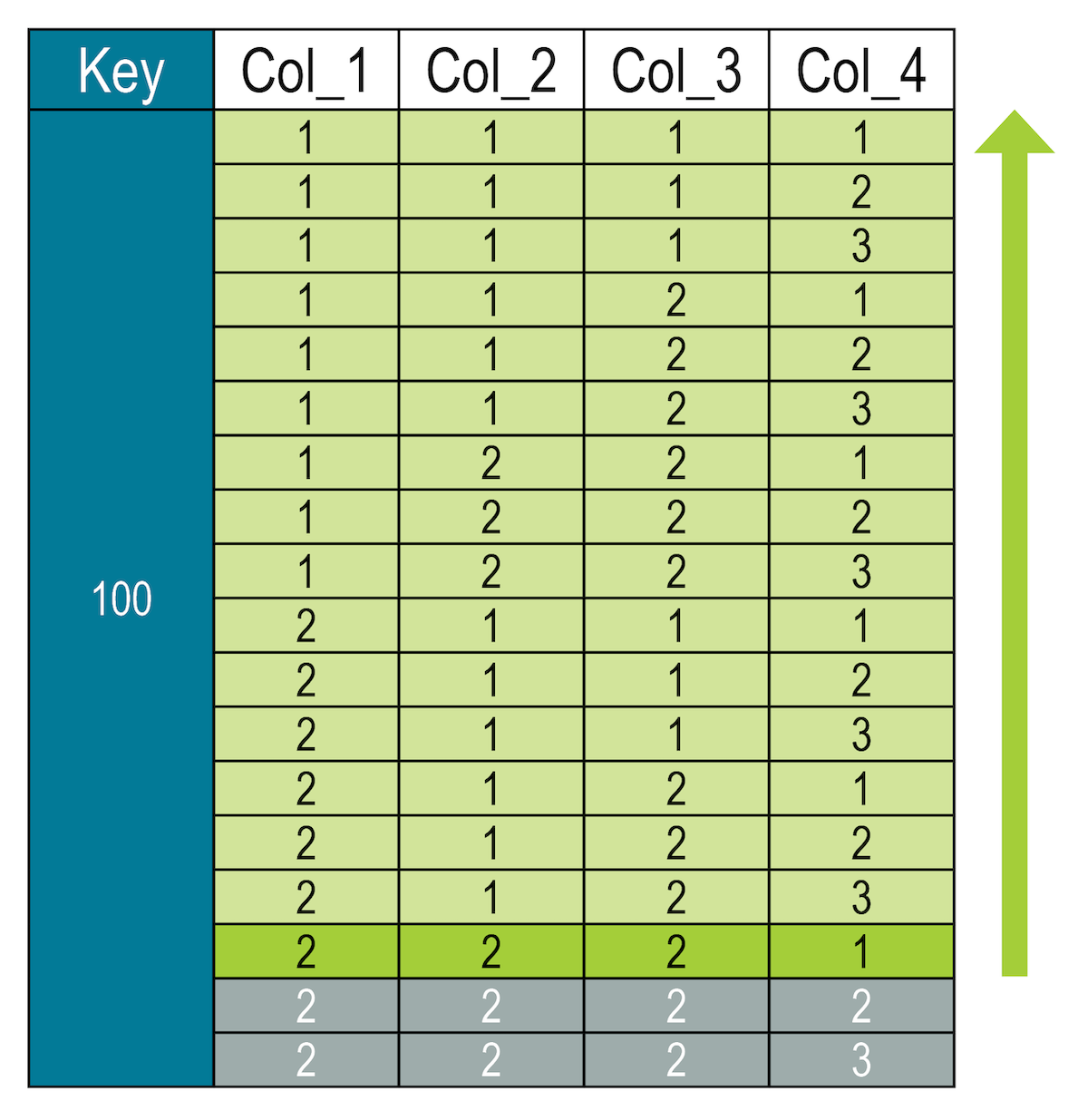
Where col_1 = 1, col_4 contains values 2 and 3 in the results (which are greater than 1). |
The database is NOT filtering on all values in column 4, it is finding the exact location shown in dark green. Once it locates the row, the evaluation ends.
The location might be hypothetical, that is the dataset does not contain a row that exactly matches the values. For example, the query specifies slice values of (2, 1, 1, 4).
SELECT * FROM cycling.numbers
WHERE key = 100 AND (col_1, col_2, col_3, col_4) <= (2, 1, 1, 4);The query finds where the row would be in the order if a row with those values existed and returns all rows before it:
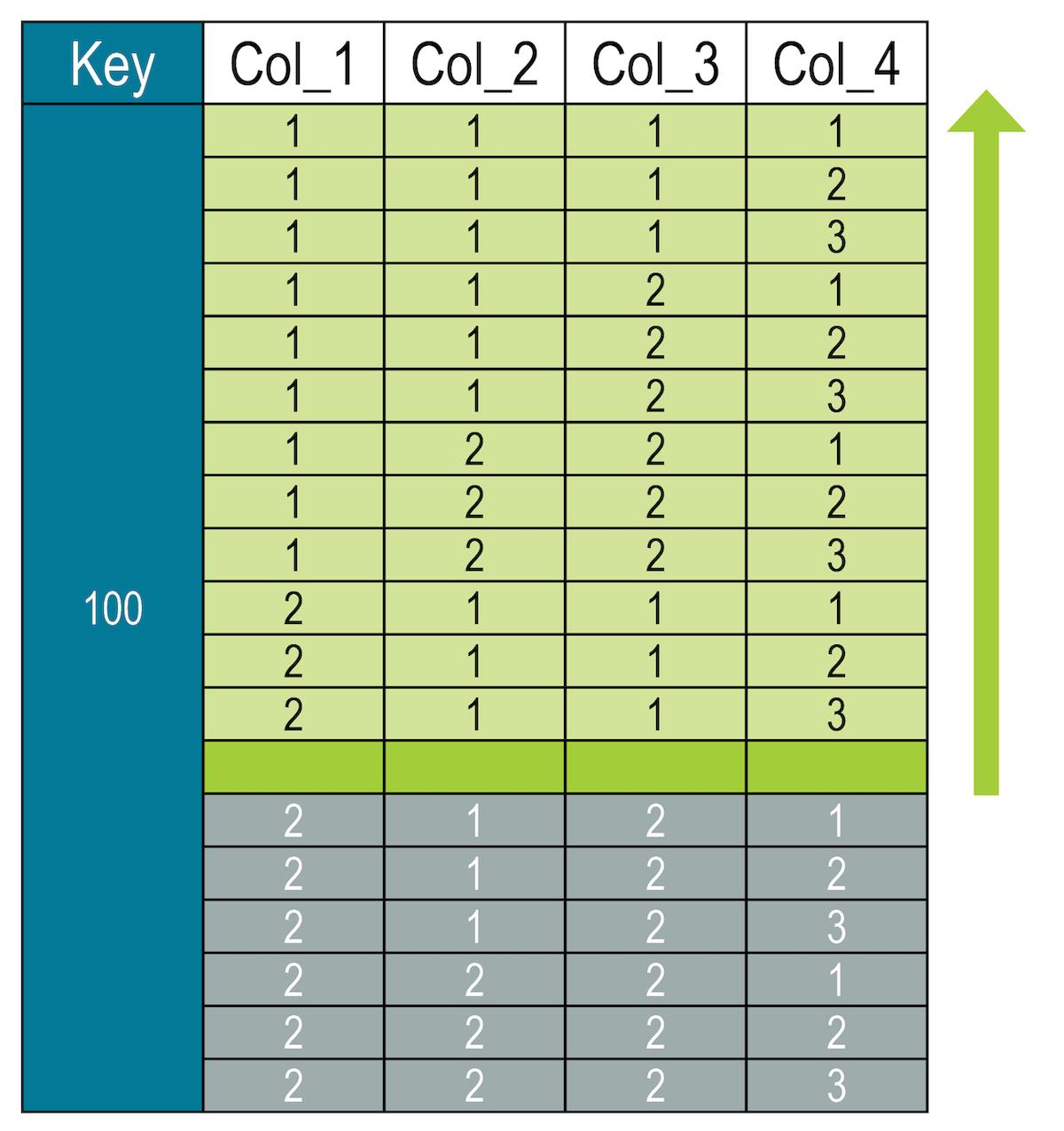
|
The value of column 4 is only evaluated to locate the row placement within the clustering segment. The database locates the segment and then finds col_4 = 4. After finding the location, it returns the row and all the rows before it in the sort order (which in this case spans all clustering columns). |
Slices of clustering segments
The same rules apply to slice restrictions when finding a slice on a lower level segment; identify the higher level clustering segments using equals or IN and specify a range on the lower segments.
For example, to return rows where the value is greater than (1, 3) and less than or equal to (2, 5):
SELECT * FROM cycling.numbers WHERE key = 100 AND col_1 = 1 AND col_2 = 1
AND (col_3, col_4) >= (1, 2) AND (col_3, col_4) < (2, 3);When finding a between range, the two slice statements must be on the same columns for lowest columns in the hierarchy.
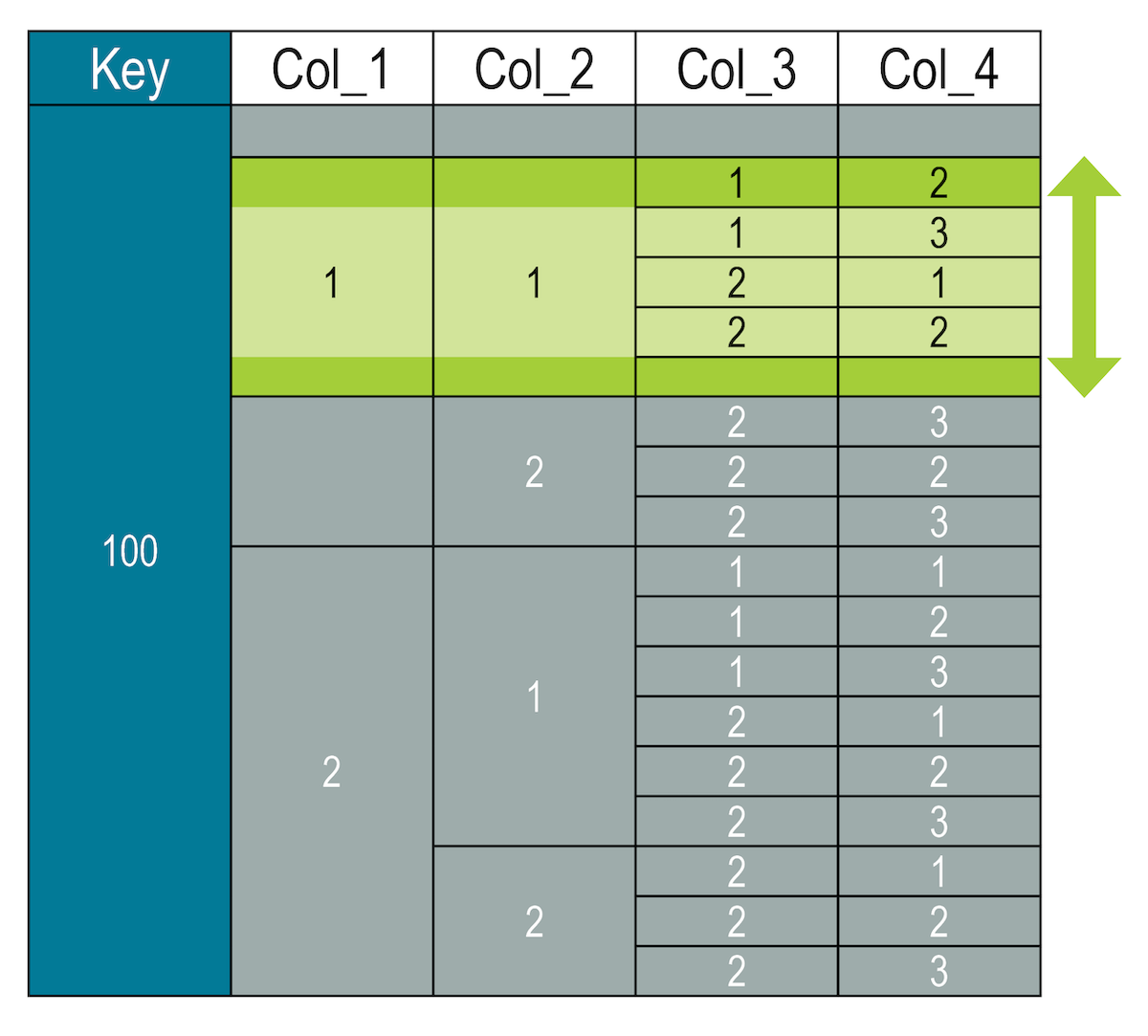
Invalid queries
When returning a slice between two rows, the slice statements must define the same clustering columns. The query is rejected if the columns are different:
SELECT * FROM cycling.numbers WHERE key = 100 AND col_1 = 1
AND (col_2, col_3, col_4) >= (1, 1, 2) AND (col_3, col_4) < (2, 3);Results
The request is invalid:
InvalidRequest: Error from server: code=2200 [Invalid query]
message="Column "col_3" cannot be restricted by two inequalities not starting
with the same column"-
Find the road cycling races that start in 2017 between January 15th and February 14th.
CREATE TABLE IF NOT EXISTS cycling.events (
year int,
start_month int,
start_day int,
end_month int,
end_day int,
race text,
discipline text,
location text,
uci_code text,
PRIMARY KEY (
(year, discipline), start_month, start_day, race
)
);
Limit the start_month and start_day for the range using a slice:
SELECT start_month as month, start_day as day, race FROM cycling.events
WHERE year = 2017 AND discipline = 'Road'
AND (start_month, start_day) < (2, 14)
AND (start_month, start_day) > (1, 15);
Results
The results contain events in that time period:
month | day | race
-------+-----+-----------------------------------------------------------------
1 | 23 | Vuelta Ciclista a la Provincia de San Juan
1 | 26 | Cadel Evans Great Ocean Road Race - Towards Zero Race Melbourne
1 | 26 | Challenge Mallorca: Trofeo Porreres-Felanitx-Ses Salines-Campos
1 | 28 | Cadel Evans Great Ocean Road Race
1 | 28 | Challenge Mallorca: Trofeo Andratx-Mirador des Colomer
1 | 28 | Challenge Mallorca: Trofeo Serra de Tramuntana -2017
1 | 29 | Cadel Evans Great Ocean Road Race
1 | 29 | Dubai Tour
1 | 29 | Grand Prix Cycliste la Marseillaise
1 | 29 | Mallorca Challenge: Trofeo Palma
1 | 31 | Ladies Tour of Qatar
2 | 1 | Etoile de Besseges
2 | 1 | Jayco Herald Sun Tour
2 | 1 | Volta a la Comunitat Valenciana
2 | 5 | G.P. Costa degli Etruschi
2 | 6 | Tour of Qatar
2 | 9 | South African Road Championships
2 | 11 | Trofeo Laigueglia
2 | 11 | Vuelta Ciclista a la Region de Murcia
2 | 12 | Clasica de Almeria
(20 rows)