The role of replication
Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance.
Cassandra delivers high availability for writing through its data replication strategy. Cassandra duplicates data on multiple peer nodes to ensure reliability and fault tolerance. Relational databases, on the other hand, typically structure tables to keep data duplication at a minimum. The relational database server has to do additional work to ensure data integrity across the tables. In Cassandra, maintaining integrity between related tables is not an issue. Cassandra tables are not related. Usually, Cassandra performs better on writes than relational databases.
About the write path
When a write occurs, Cassandra stores the data in a structure in memory, the memtable, and also appends writes to the commit log on disk, providing configurable durability.
The commit log receives every write made to a Cassandra node, and these durable writes survive permanently even after hardware failure.
The more a table is used, the larger its memtable needs to be. Cassandra can dynamically
allocate the right amount of memory for the memtable or you can manage the amount of memory
being utilized yourself. When memtable contents exceed a configurable threshold , the memtable data, which includes indexes, is put in a
queue to be flushed to disk. You can configure the length of the queue by changing
memtable_flush_queue_size in the cassandra.yaml. If the data to be flushed exceeds the queue
size, Cassandra blocks writes. The memtable data is flushed to SSTable on disk using sequential I/O. Data in the commit log is purged after its
corresponding data in the memtable is flushed to the SSTable.
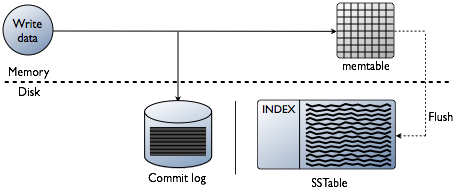
Memtables and SSTables are maintained per table. SSTables are immutable, not written to again after the memtable is flushed. Consequently, a row is typically stored across multiple SSTable files.
For each SSTable, Cassandra creates these in-memory structures:
-
Partition index
A list of primary keys and the start position of rows in the data file.
-
Partition summary
A subset of the partition index. By default 1 primary key out of every 128 is sampled.