Initializing a multiple node cluster (multiple data centers)
A deployment scenario for a Cassandra cluster with multiple data centers.
This topic contains information for deploying a Cassandra cluster with multiple data centers.
Data replicates across the data centers automatically and transparently; no ETL work is necessary to move data between different systems or servers. You can configure the number of copies of the data in each data center and Cassandra handles the rest, replicating the data for you.
In Cassandra, the term data center is a grouping of nodes. Data center is synonymous with replication group, that is, a grouping of nodes configured together for replication purposes.
Prerequisites
- Install Cassandra on each node.
- Choose a name for the cluster.
- Get the IP address of each node.
- Determine which nodes will be seed nodes. (Cassandra nodes use the seed node list for finding each other and learning the topology of the ring.)
- Determine the snitch.
- If using multiple data centers, determine a naming convention for each data center and rack, for example: DC1, DC2 or 100, 200 and RAC1, RAC2 or R101, R102.
- Other possible configuration settings are described in The cassandra.yaml configuration file.
Procedure
-
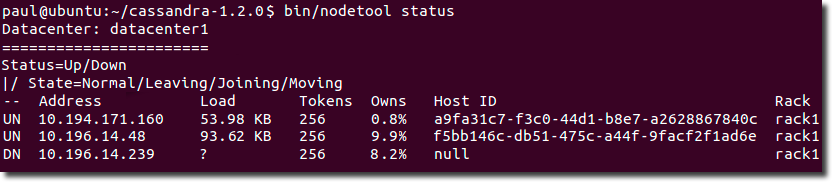
To check that the ring is up and running, run the nodetool
status command.
Related topics