Speculative query execution with Cassandra drivers
If a node responds slowly, all queries sent to that node experience increased latency. Slow responses can be temporary or permanent. To mitigate these latency spikes, you can use speculative execution to preemptively start a second execution of a query against another node before the first node has replied or returned an error.
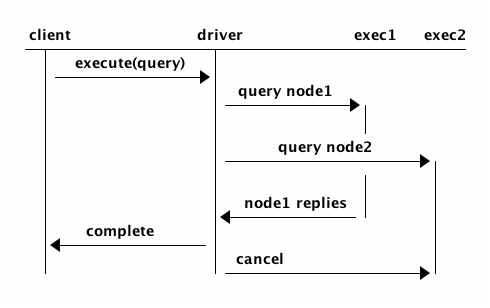
For applications that use speculative execution, the data from whichever node replies faster is returned to the client.
If the second node replies faster, that node’s response is returned to the client. Then, the first execution is cancelled on the client-side only, and the client stops waiting for the response from the first execution.
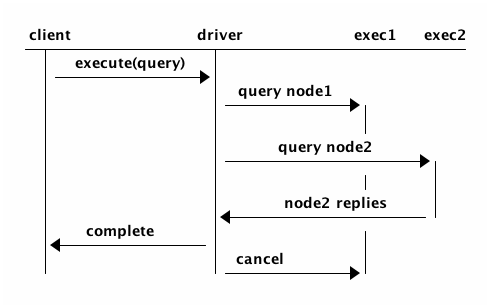
Alternatively, the first node might reply just after the second execution call starts. In this case, the client uses the response from the first node and ignores the response from the second execution.
|
When an execution is cancelled on the client side, the request still interacts with the server, but the client ignores the response. Cancelling an execution on the client side only means that the client stops waiting for the server’s response. Typically, this isn’t an issue because both requests make the same change, unless you are using server-side timestamps. |
Speculative execution only applies to idempotent queries
If a query is non-idempotent, the driver will never schedule speculative executions for the query. This is because there is no way to guarantee that only one coordinator will apply the mutation.
To use speculative execution, your queries must be marked as idempotent. For more information, see Query idempotence in Cassandra drivers.
Configure speculative execution
Speculative execution is disabled by default in DataStax-compatible drivers.
To enable and configure speculative execution, see your driver’s documentation.
-
C/C++
-
C#
-
Go
-
Java
-
Node.js
-
PHP
-
Python
-
Ruby
See the documentation for your version of the Java driver:
See the documentation for your version of the Node.js driver:
See speculativeRetry.
See SpeculativeExecutionPolicy in the documentation for your version of the Python driver:
See speculative_retry.
Performance tuning for speculative executions
The goal of speculative execution is to improve the overall latency of an application. However, too many speculative executions increase the load on the cluster. Most drivers surface metrics for speculative executions that can be used to observe the frequency of speculative executions.
Delay threshold
Ideally, if speculative executions are used to avoid sending queries to unhealthy nodes, a healthy node should rarely reach resource limits.
Each driver provides a configurable delay threshold for sending speculative executions. In order to determine an appropriate threshold for your application, benchmark the healthy platform state (with all nodes up and under a normal load) and monitor the response latencies. Based on these results, use the latency at a high percentile (p99.9) as the speculative executions threshold.
Alternatively, when prioritizing low latency, and the cluster can handle increased throughput, you can set the threshold to 0. This effectively always performs speculative executions by sending them immediately after the first execution.
Stream ID exhaustion
One effect of speculative executions is that many requests are cancelled on the client side. This can lead to a phenomenon called stream ID exhaustion.
Each TCP connection can handle multiple simultaneous requests, identified by a unique number called a stream ID. When a request gets cancelled, the stream ID for that request cannot be reused immediately because the response for that request can be returned silently from the server once it fulfills the request. If this happens often, the number of available stream IDs diminishes over time. When the available stream IDs goes below a given threshold, the connection is closed and a new connection is created. If requests are often cancelled, connections are recycled at a high rate.
In practice, exhausting all stream IDs on a connection shouldn’t occur. Each connection can reference 32768 stream IDs, and most driver implementations are configured to send only 1000 requests per connection by default.
Most drivers provide a metric for observing the number of inflight requests for a node. Some drivers provide a metric for observing the number of orphaned stream IDs. Monitor these metrics to ensure that stream ID exhaustion isn’t occurring.
If stream ID exhaustion is occurring, typical solutions include adding more capacity to the cluster, or adjusting node system settings to avoid resource limits.
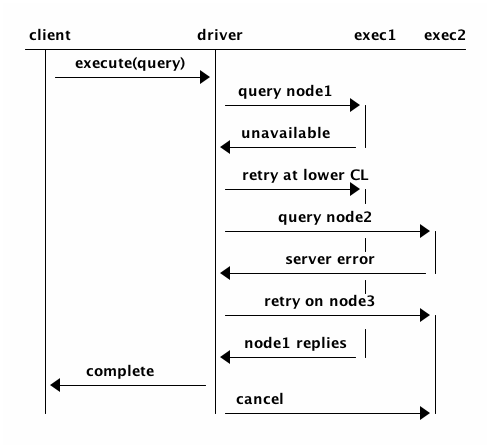
Retry policies
Enabling speculative executions doesn’t change the driver’s retry behavior.
Each parallel execution triggers retries independently if needed.
All executions of the same query share the same query plan, so each node is used by no more than one execution.
Avoid server-side timestamps
All driver versions since Cassandra 2.1 use client-side query timestamps by default.
If you explicitly configure your driver to use server-side timestamps, ordering issues can occur.
With client-side timestamps, all executions use timestamps generated by the client. However, with server-side timestamps, each execution gets a timestamp generated by its coordinating node. Because the requests run against different nodes, slight differences in server clocks can cause operations to be applied in an unexpected order.
For this reason, DataStax recommends that you use client-side timestamps with speculative execution.
Example: Speculative execution with server-side timestamps
Assume you run the following query with speculative execution and server-side timestamps enabled:
INSERT INTO my_table (k, v) VALUES (1, 1);Assuming the first execution is slow, the speculative execution policy triggers a second execution.
Then, the first execution completes, which cancels the second execution on the client-side. However, cancelling an execution only means that the driver stops waiting for the server’s response. The request continues to run against the server.
While the cancelled request is still running against the server, assume the following query runs successfully:
DELETE FROM my_table WHERE k = 1;Finally, when the second INSERT request reaches its target node, it applies the INSERT operation.
The row that was successfully deleted by the last request is now restored, despite the driver ignoring the result of the second INSERT request.
This is because the server-side timestamp was assigned when the request reached the coordinating node, which happened after the DELETE operation.
Although the driver ignored the response, the operation was still applied to the database.
This scenario is avoided completely by using client-side timestamps.
