DSE Graph, OLTP and OLAP
Explain OLTP and OLAP relationship in DSE Graph.
Online transaction processing (OLTP) is characterized by a large number of short online transactions for very fast query processing. OLTP is typically used for data entry and retrieval transaction-oriented applications. Online analytical processing (OLAP) is characterized by relatively low volume of transactions. OLAP is typically used to perform multidimensional analysis of data, doing complex calculations on aggregated historical data.
OLTP applications require sub-second response times, whereas OLAP applications take much longer to finish queries. In graph databases, OLTP traversals are localized to a particular subgraph of the global graph. Graph databases are a random access data system. OLAP traversals will do a linear scan of all vertices in the graph. OLTP traversals leverage indexes to "jump" in to a particular vertex in the graph before starting a scan on the subgraph.
OLTP queries are best for questions that require access to a limited subset of the entire graph. OLTP queries use filters to limit the number of vertices that will be walked to find answers. DSE Graph colocates vertices with their edges and adjacent neighbors. When a subgraph is specified in a traversal using indexes, the number of requests to disk are reduced to locate and write the requested subgraph to memory. Once in memory, the traversal performs a link walk from vertex to vertex along the edges.
OLAP queries are best for questions that must access a significant portion of the data stored in a graph. Using the method described above to evaluate OLAP queries will not be efficient, so a different process is used. When OLAP queries are processed, the entire graph is interpreted as a sequence of star graphs, each composed of a single vertex, along with its properties, incident edges and the edge's properties. The star graphs are linearly processed, jumping from one star graph to the next until all star graphs are processed and an aggregation of the discovered data is completed.
Understanding these underlying principles can lead to writing better graph traversals to query the graph data. A simple example illustrates the differences. Using the food graph, the query is "How many recipes has Julia Child created?"
g.V().in().has('name','Julia Child').count()
===>6name and property value of Julia
Child, and counts the number of vertices. The count returned includes all vertices
with edges to Julia Child, and not just the recipes, so as shown later, the count is incorrect
and too high.gremlin> g.V().in().has('name','Julia Child').count().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep(vertex,[]) 61 61 28.932 18.71
query-optimizer 0.563
\_condition=((label = FridgeSensor | label = author | label = book | label = ingredient | label = meal |
label = recipe | label = reviewer) & (true))
query-setup 0.048
\_isFitted=true
\_isSorted=false
\_isScan=true
index-query 0.979
\_usesCache=false
\_statement=SELECT "city_id", "sensor_id" FROM "DSEQuickStart"."FridgeSensor_p" WHERE "~~vertex_exists" =
? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 0.862
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."author_p" WHERE "~~vertex_exists" =
? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 0.679
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."book_p" WHERE "~~vertex_exists" = ?
LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 1.344
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."ingredient_p" WHERE "~~vertex_exists
" = ? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 5000
0
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 1.053
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."meal_p" WHERE "~~vertex_exists" = ?
LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 4.173
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."recipe_p" WHERE "~~vertex_exists" =
? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 1.291
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."reviewer_p" WHERE "~~vertex_exists"
= ? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
DsegVertexStep(IN,vertex) 78 78 95.721 61.90
query-optimizer 0.305
\_condition=((true) & direction = IN)
vertex-query 4.136
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 588941056, (java.lang.Long) 0, (java.lang.I
nteger) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
vertex-query 0.558
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 1432048000, (java.lang.Long) 1, (java.lang.
Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
vertex-query 1.146
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 153541376, (java.lang.Long) 1, (java.lang.I
nteger) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.941
\_isFitted=false
\_isSorted=true
\_isScan=false
query-setup 0.015
\_isFitted=false
\_isSorted=true
\_isScan=false
vertex-query 1.966
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 138026496, (java.lang.Long) 0, (java.lang.I
nteger) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.015
\_isFitted=false
\_isSorted=true
\_isScan=false
query-setup 0.013
\_isFitted=false
\_isSorted=true
\_isScan=false
query-setup 0.016
\_isFitted=false
\_isSorted=true
\_isScan=false
NoOpBarrierStep(2500) 78 25 2.877 1.86
HasStep([name.=(Julia Child)]) 5 1 25.242 16.32
CountGlobalStep 1 1 1.859 1.20
>TOTAL - - 154.632 -profile() method now includes
CQL commands that are executed due to gremlin commands.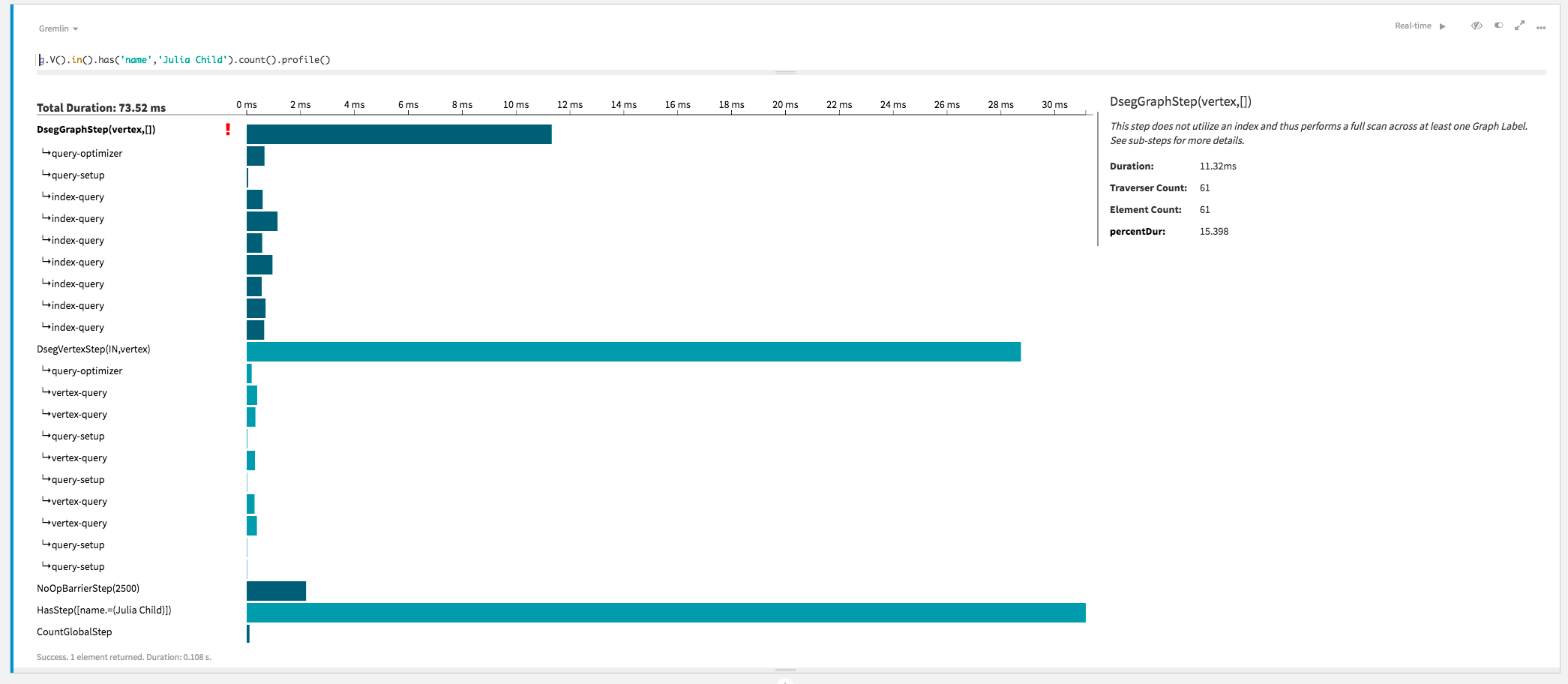
This graph traversal is a classic OLAP traversal, that must touch all vertices and does not make use of indexing.
g.V().in('created').has('name','Julia Child').count()
===>3created. Looking at the profile shows an
improved
picture:gremlin> g.V().in('created').has('name','Julia Child').count().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep(vertex,[]) 61 61 22.251 16.91
query-optimizer 1.760
\_condition=((label = FridgeSensor | label = author | label = book | label = ingredient | label = meal |
label = recipe | label = reviewer) & (true))
query-setup 0.071
\_isFitted=true
\_isSorted=false
\_isScan=true
index-query 1.139
\_usesCache=false
\_statement=SELECT "city_id", "sensor_id" FROM "DSEQuickStart"."FridgeSensor_p" WHERE "~~vertex_exists" =
? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 2.012
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."author_p" WHERE "~~vertex_exists" =
? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 0.549
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."book_p" WHERE "~~vertex_exists" = ?
LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 0.849
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."ingredient_p" WHERE "~~vertex_exists
" = ? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 5000
0
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 0.887
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."meal_p" WHERE "~~vertex_exists" = ?
LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 0.889
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."recipe_p" WHERE "~~vertex_exists" =
? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
index-query 0.499
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."reviewer_p" WHERE "~~vertex_exists"
= ? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
DsegVertexStep(IN,[created],vertex) 8 8 103.458 78.62
query-optimizer 0.618
\_condition=(((label = created) & (true)) & direction = IN)
vertex-query 0.261
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? AND "~~
edge_label_id" = ? LIMIT ? ALLOW FILTERING; with params (java.lang.Integer) 1432048000, (java
.lang.Long) 1, (java.lang.Integer) 65577, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
vertex-query 0.200
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? AND "~~
edge_label_id" = ? LIMIT ? ALLOW FILTERING; with params (java.lang.Integer) 153541376, (java.
lang.Long) 1, (java.lang.Integer) 65577, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.017
\_isFitted=true
\_isSorted=true
\_isScan=false
vertex-query 6.140
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? AND "~~
edge_label_id" = ? LIMIT ? ALLOW FILTERING; with params (java.lang.Integer) 588941056, (java.
lang.Long) 0, (java.lang.Integer) 65577, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.017
\_isFitted=true
\_isSorted=true
\_isScan=false
vertex-query 0.201
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? AND "~~
edge_label_id" = ? LIMIT ? ALLOW FILTERING; with params (java.lang.Integer) 771301632, (java.
lang.Long) 0, (java.lang.Integer) 65577, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.012
\_isFitted=true
\_isSorted=true
\_isScan=false
vertex-query 0.173
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? AND "~~
edge_label_id" = ? LIMIT ? ALLOW FILTERING; with params (java.lang.Integer) 994194304, (java.
lang.Long) 0, (java.lang.Integer) 65577, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.012
\_isFitted=true
\_isSorted=true
\_isScan=false
NoOpBarrierStep(2500) 8 4 0.910 0.69
HasStep([name.=(Julia Child)]) 3 1 4.903 3.73
CountGlobalStep 1 1 0.075 0.06
>TOTAL - - 131.599 -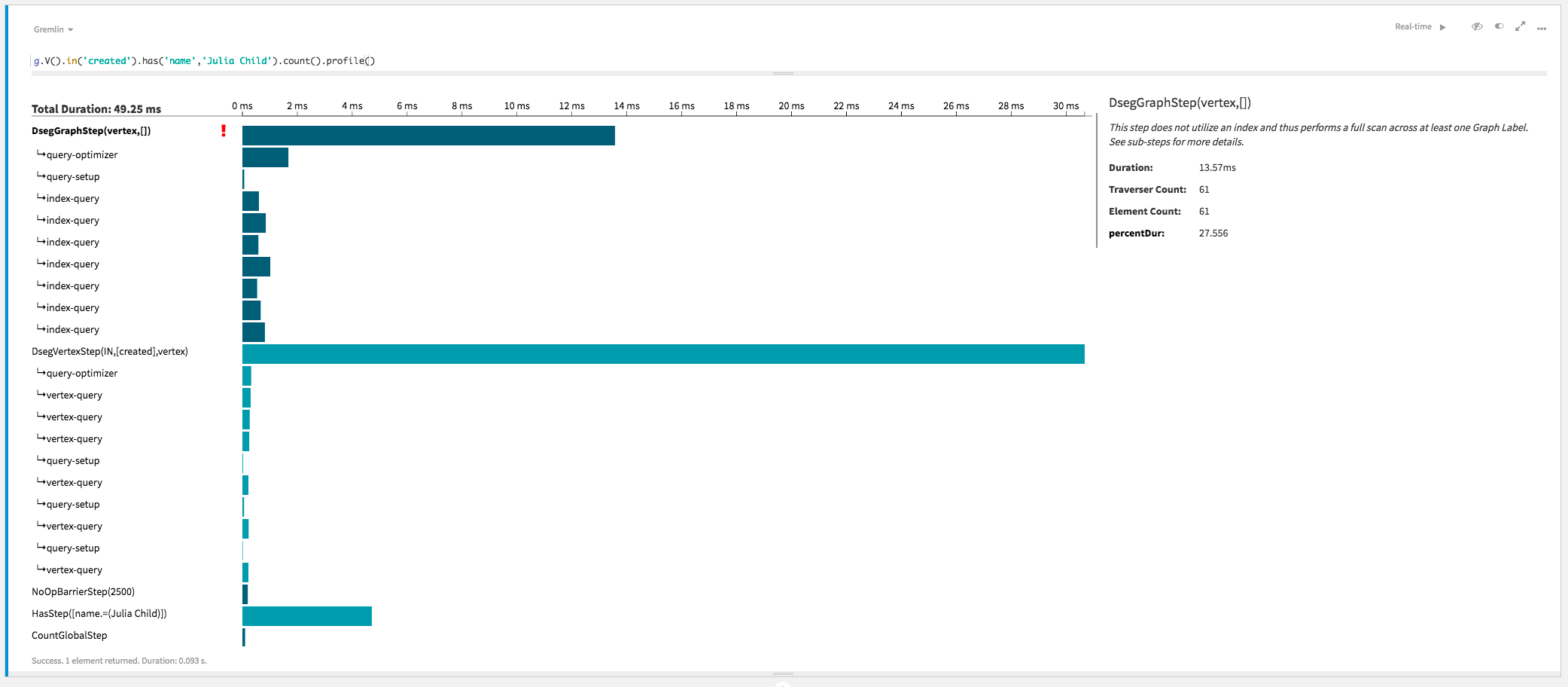
This graph traversal is still an OLAP traversal that touch all vertices and does not use indexes.
g.V().hasLabel('recipe').in().has('name','Julia Child').count()
===>3recipe vertices, but walks all
incoming edges. The profile shows a somewhat better picture:gremlin> g.V().hasLabel('recipe').in().has('name','Julia Child').count().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep([~label.=(recipe)]) 8 8 2.598 9.25
query-optimizer 0.241
\_condition=((label = recipe) & (true))
query-setup 0.187
\_isFitted=true
\_isSorted=false
\_isScan=true
index-query 1.225
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."recipe_p" WHERE "~~vertex_exists" =
? LIMIT ? ALLOW FILTERING; with params (java.lang.Boolean) true, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
DsegVertexStep(IN,vertex) 15 15 9.668 34.41
query-optimizer 0.150
\_condition=((true) & direction = IN)
query-setup 0.047
\_isFitted=false
\_isSorted=true
\_isScan=false
vertex-query 0.896
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."recipe_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 1315507840, (java.lang.Long) 1, (java.lang.
Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
vertex-query 1.415
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."recipe_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 96517120, (java.lang.Long) 1, (java.lang.In
teger) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
vertex-query 2.846
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."recipe_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 1598713728, (java.lang.Long) 1, (java.lang.
Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.038
\_isFitted=false
\_isSorted=true
\_isScan=false
vertex-query 0.364
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."recipe_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 1146421632, (java.lang.Long) 1, (java.lang.
Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.014
\_isFitted=false
\_isSorted=true
\_isScan=false
vertex-query 0.431
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."recipe_e" WHERE "community_id" = ? AND "member_id" = ? LIMIT ?
ALLOW FILTERING; with params (java.lang.Integer) 384373760, (java.lang.Long) 2, (java.lang.I
nteger) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.014
\_isFitted=false
\_isSorted=true
\_isScan=false
HasStep([name.=(Julia Child)]) 3 3 15.765 56.10
CountGlobalStep 1 1 0.068 0.24
>TOTAL - - 28.100 -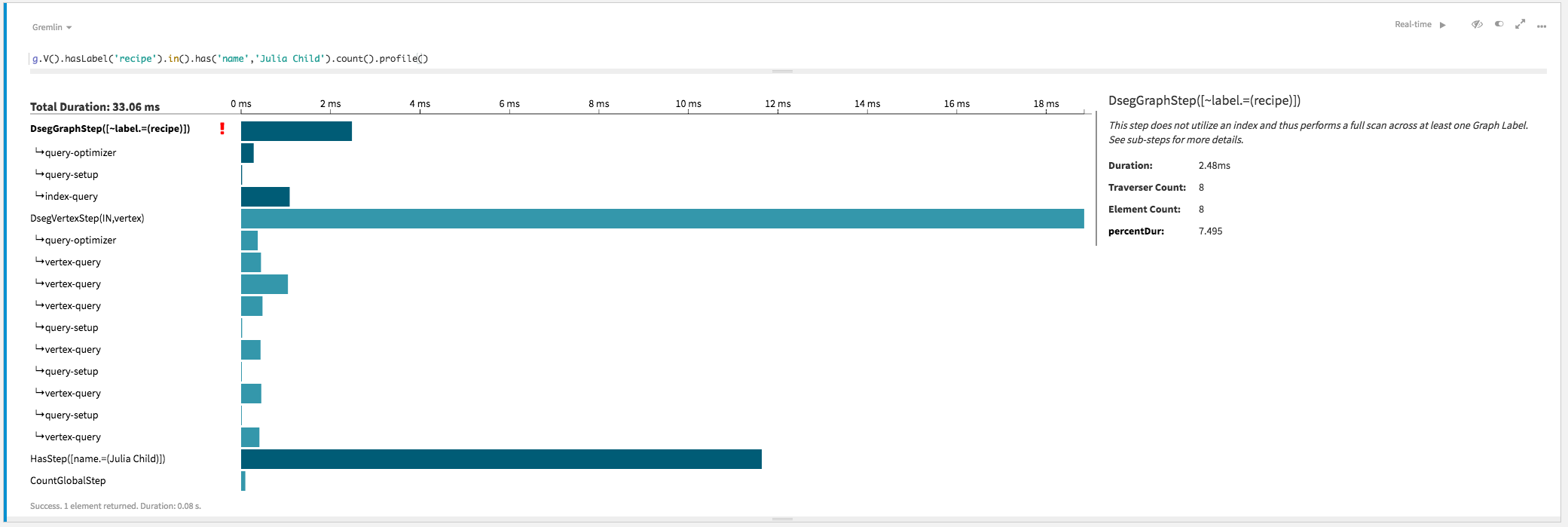
This graph traversal is still an OLAP traversal that does not use indexes. As will be described in the next example, indexes are identified by vertex label and property key. Although this traversal narrows the query by limiting the vertex label initially, an index is not used to find the starting point for the traversal.
g.V().has('author', 'name', 'Julia Child').outE('created').count()
===>3author and a specific property key and value Julia Child,
and walks only the outgoing edges that have an edge label created.
gremlin> g.V().has('author','name','Julia Child').outE('created').count().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep([~label.=(author), name.=(Julia C... 1 1 29.049 84.45
query-optimizer 7.673
\_condition=(((label = author) & (true)) & name = Julia Child)
query-setup 0.033
\_isFitted=true
\_isSorted=false
\_isScan=false
index-query 17.694
\_indexType=Secondary
\_usesCache=false
\_statement=SELECT "community_id", "member_id" FROM "DSEQuickStart"."author_p" WHERE "name" = ? LIMIT ?;
with params (java.lang.String) Julia Child, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
DsegVertexStep(OUT,[created],edge) 3 3 5.265 15.31
query-optimizer 0.200
\_condition=(((label = created) & (true)) & direction = OUT)
vertex-query 0.586
\_usesCache=false
\_statement=SELECT * FROM "DSEQuickStart"."author_e" WHERE "community_id" = ? AND "member_id" = ? AND "~~
edge_label_id" = ? LIMIT ? ALLOW FILTERING; with params (java.lang.Integer) 1535517312, (java
.lang.Long) 0, (java.lang.Integer) 65576, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_isPartitioned=false
\_usesIndex=false
query-setup 0.057
\_isFitted=true
\_isSorted=true
\_isScan=false
CountGlobalStep 1 1 0.081 0.24
>TOTAL - - 34.397 -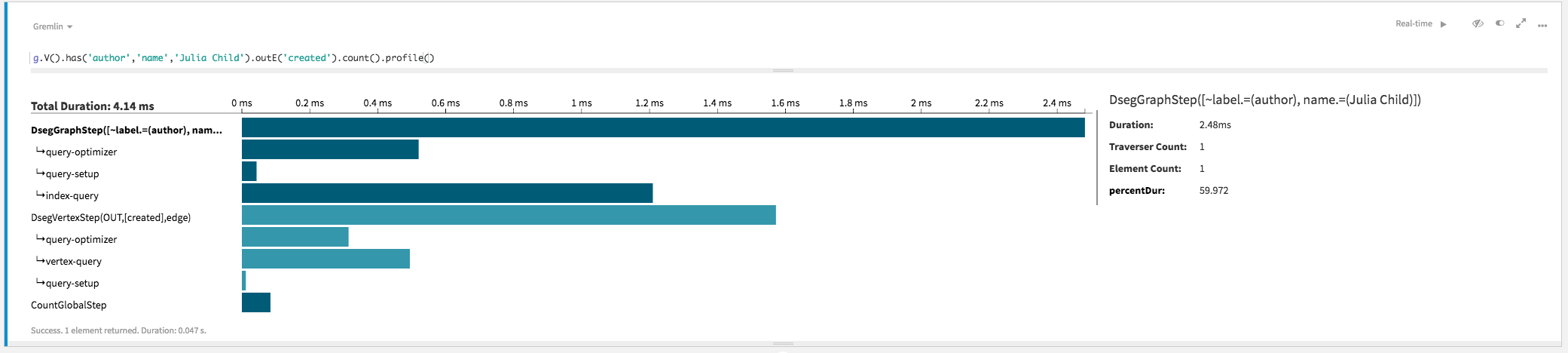
This graph traversal is an OLTP traversal. An index on the vertex label author
and property key name can be used to start the traversal directly at an indexed
vertex. This example results in a single vertex, but queries that use indexing to limit the
starting point to even several vertices will be more efficient than a linear scan that must check
all vertices in the graph. Thus, a subgraph, or portion of the graph is traversed.
The key to creating OLTP graph traversals is considering how the graph will be traversed. Use of indexing is critical to the success of fast transactional processing. The profiling tool included with DSE Graph is valuable to analyzing how the traversal performs.
For information on running OLAP queries using Spark, see DSE Graph and Graph Analytics.