About BYOH
DataStax Enterprise works with external Hadoop systems in a bring your own Hadoop (BYOH) model. Use BYOH to run DSE Analytics with a separate Hadoop cluster from a different vendor.
Hadoop is a software framework for distributed processing of large data sets using MapReduce programs. DataStax Enterprise works with these external Hadoop systems in a bring your own Hadoop (BYOH) model. Use BYOH to run DSE Analytics with a separate Hadoop cluster, from a different vendor. Supported vendors are:
- Hadoop 2.x data warehouse implementations Cloudera 4.5, 4.6, 5.0.x, and 5.2.x
- Hortonworks 1.3.3, 2.0.x, 2.1, and 2.2
You can use Hadoop in one of the following modes:
- External Hadoop (BYOH)
Uses the Hadoop distribution provided by Cloudera (CDH) or Hortonworks (HDP).
- Internal Hadoop (DSE Hadoop)
DSE Hadoop uses an embedded Apache Hadoop 1.0.4 to eliminate the need to install a separate Hadoop cluster.
By default, the Hadoop 2.7.1 client libraries are used, except for Hive and Pig, which use Hadoop 1.0.4 libraries with built-in Hadoop trackers.
- Bi-directional data movement between Cassandra in DataStax Enterprise and the Hadoop Distributed File System (HDFS)
- Hive queries against Cassandra data in DataStax Enterprise
- Data combination (joins) between Cassandra and HDFS data
- ODBC access to Cassandra data through Hive
Components
| Component | DSE-integrated Hadoop owner | BYOH owner | DSE interaction |
|---|---|---|---|
| Job Tracker | DSE Cluster | Hadoop Cluster | Optional |
| Task Tracker | DSE Cluster | Hadoop Cluster | Co-located with BYOH nodes |
| Pig | Distributed with DSE | Distribution chosen by operator | Can launch from Task Trackers |
| Hive | Distributed with DSE | Distribution chosen by operator | Can launch from Task Trackers |
| HDFS/CFS | CFS | HDFS | Block storage |
BYOH installation and configuration
- Ensure that you meet the prerequisites.
- Install DataStax Enterprise on all nodes in the Cloudera or Hortonworks cluster and on additional nodes outside the Hadoop cluster.
- Install several Cloudera or Hortonworks components on the additional nodes and deploy those nodes in a virtual BYOH datacenter.
- Configure DataStax Enterprise BYOH environment variables on
each node in the BYOH datacenter to point to the Hadoop cluster, as shown in the following diagram:
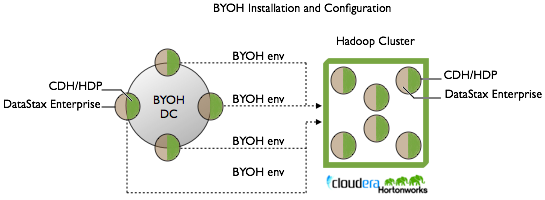
DataStax Enterprise runs only on BYOH nodes, and uses Hadoop components to integrate BYOH and Hadoop. You never start up the DataStax Enterprise installations on the Hadoop cluster.
MapReduce process
In a typical Hadoop cluster, Task Tracker and Data Node services run on each node. A Job Tracker service running on one of the master nodes coordinates MapReduce jobs between the Task Trackers, which pull data locally from data node. For the latest versions of Hadoop using YARN, Node Manager services replace Task Trackers and the Resource Manager service replaces the Job Tracker.
- Task Tracker--Means Task Tracker or Node Manager.
- Job Tracker--Means Job Tracker or Resource Manager.
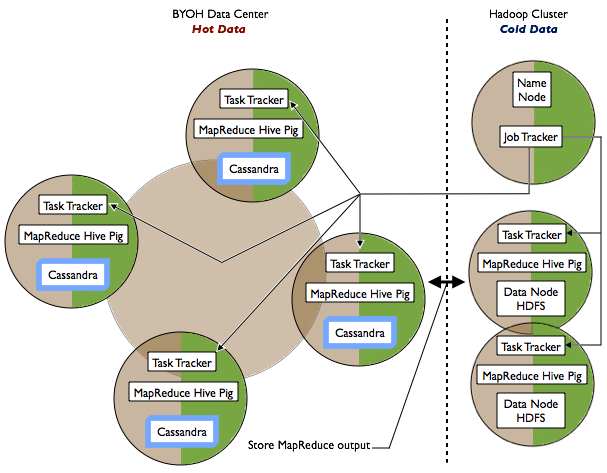
A MapReduce service runs on each BYOH node along with optional MapReduce, Hive, and Pig clients. To take advantage of the performance benefits offered by Cassandra, BYOH handles frequently accessed hot data. The Hadoop cluster handles less-frequently and rarely accessed cold data. You design the MapReduce application to store output in Cassandra or Hadoop.
The following diagram shows the data flow of a job in a BYOH datacenter. The Job Tracker/Resource Manager (JT/RM) receives MapReduce input from the client application. The JT/RM sends a MapReduce job request to the Task Trackers/Node Managers (TT/NM) and optional clients, MapReduce, Hive, and Pig. The data is written to Cassandra and results sent back to the client.
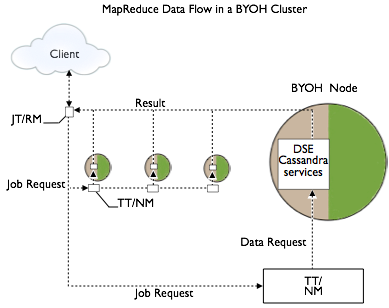
BYOH workflow
BYOH clients submit Hive jobs to the Hadoop Job Tracker or ResourceManager in the case of YARN. If Cassandra is the source of the data, the Job Tracker evaluates the job, and the ColumnFamilyInputFormat creates input splits and assigns tasks to the various Task Trackers in the Cassandra node setup (giving the jobs local data access). The Hadoop job runs until the output phase.
During the output phase if Cassandra is the target of the output, the HiveCqlOutputFormat writes the data back into Cassandra from the various reducers. During the reduce step, if data is written back to Cassandra, locality is not a concern and data gets written normally into the cluster. For Hadoop in general, this pattern is the same. When spilled to disk, results are written to separate files, partial results for each reducer. When written to HDFS, the data is written back from each of the reducers.
Intermediate MapReduce files are stored on the local disk or in temporary HDFS tables, depending on configuration, but never in CFS. Using the BYOH model, Hadoop MapReduce jobs can access Cassandra as a data source and write results back to Cassandra or Hadoop.