About DataStax Bulk Loader (DSBulk)
DSBulk is open-source software that you can use to load, unload, and count database records and return related information. For more information about this open-source project, including licensing, see the DSBulk GitHub repository.
You can load and unload CSV and JSON files with options for parsing and progress reporting. Load/unload targets can be compressed or uncompressed, and they can be files, directories, stdin/stdout, or URLs. Performance is optimized through multi-threaded operation, and you can tune various parameters to improve load and unload times.
|
To get started, see Install DataStax Bulk Loader. |
DSBulk compatibility
DSBulk is compatible with the following databases:
-
Astra DB
-
Hyper-Converged Database (HCD)
-
DataStax Enterprise (DSE) 5.1, 6.8, and 6.9
-
Apache Cassandra® 2.1 and later
DSBulk is supported on Linux, macOS, and Windows platforms.
DSBulk architecture
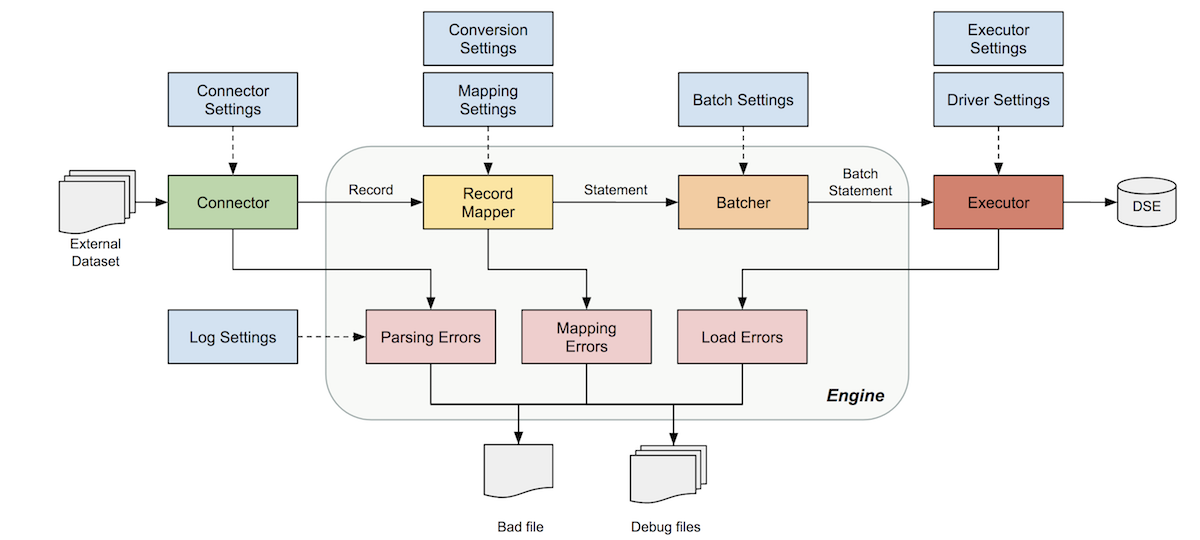
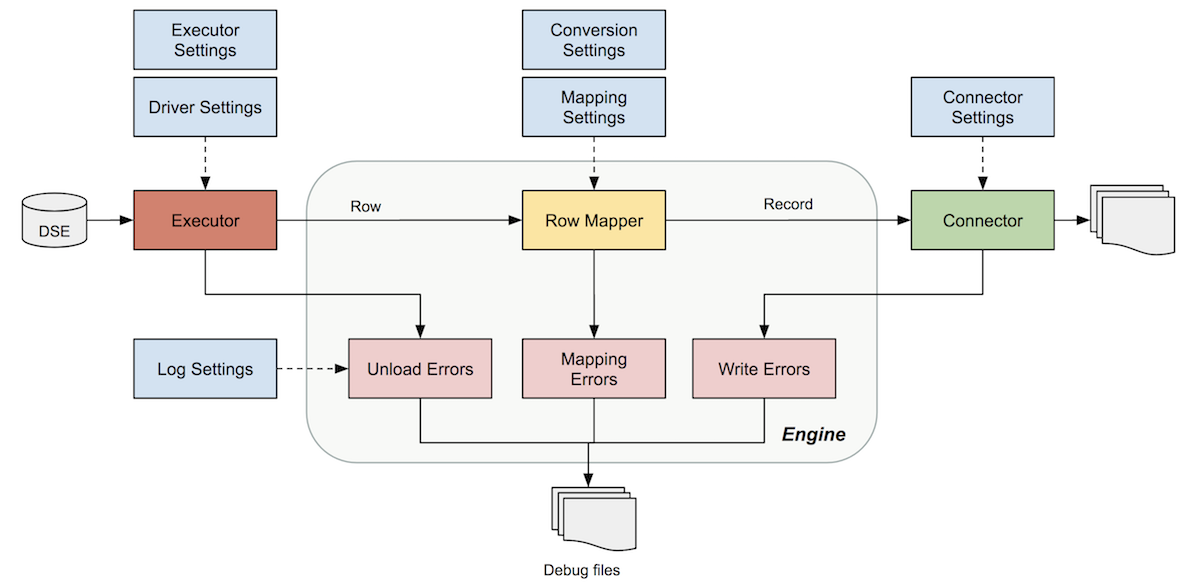
The DSBulk engine is the key architectural component responsible for the orchestration of DSBulk operations. The main features are as follows:
- Configuration
-
The engine collects user-supplied settings, merges them with default values and configures the loading/unloading operation to run.
Options can be supplied on the command line or with configuration files.
- Connection handling
-
The engine handles the Apache Cassandra® Java driver connection to your database, and the connectors that read and write CSV and JSON data.
The engine manages the driver-specific settings, and it supports authentication and SSL encryption.
- Conversion
-
The engine handles data type conversions such as Boolean, number, or date conversions to appropriate internal representations.
The internal representation are typically Java Temporal or Number objects. The external representation can be anything, and it is typically strings or raw bytes as emitted by a connector.
DSBulk also handles
NULLandUNSETvalues, with options for multiple representations ofNULLandEMPTYvalues. - Mapping
-
The engine can analyze metadata gathered from the driver, and then infer the appropriate
INSERTorSELECTprepared statement. It then checks this information against user-supplied information about the data source to infer the bound variables to use.Alternatively, you can provide your own explicit mapping.
- Monitoring
-
The engine reports metrics about all its internal components, mainly the connector and the bulk executor.
- Error handling
-
The engine handles errors from both connectors and the bulk executor. It reports read, parse, and write failures.