Production Cluster Sizing
This document summarizes DataStax’s recommendations for the sizing and optimization of an Apache Pulsar cluster on Linux in a production environment. Remember, a Pulsar instance is made of one or many clusters.
Of course, the sizing of a cluster depends on factors like use case and expected load, so this document is not intended to be a one-size-fits-all guide. Rather, we’d like to demonstrate how we consider and spec the initial size of a Pulsar cluster, and assist you on your journey to unlocking the scaling power of Pulsar.
This page summarizes the requirements, assumptions, definitions, and methodologies that inform our cluster sizing recommendations. If you’re looking for specific deployment topology recommendations, see Installation topologies.
|
Kubernetes Autoscaling for Apache Pulsar (KAAP) takes care of scaling Pulsar cluster components, deploying new clusters, and even migrating your existing cluster to an operator-managed deployment. |
Dedicated VMs or Kubernetes
As you begin your journey to design an Apache Pulsar cluster, one of the first questions to consider is what infrastructure your cluster will run on. Most of this guide will focus on running a cluster with dedicated virtual machines. While Kubernetes is the more popular option, it is easier to express disk calculations, throughput, and secure communications in terms of a VM.
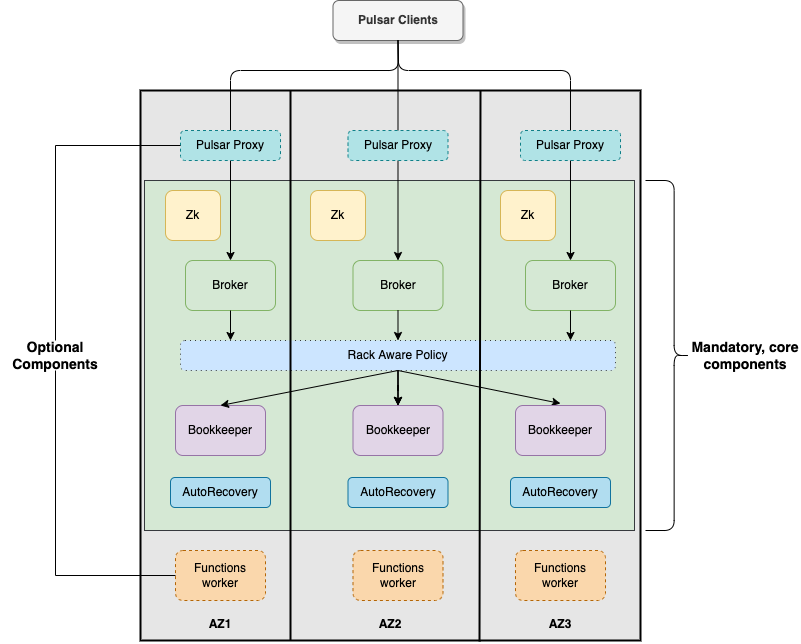
Pulsar cluster components
Pulsar clusters come in many shapes and sizes. There are minimum components for base functionality, and there are recommended components that make message routing, management, and observability easier. For this guide we will focus on the required components and what it takes to make them resilient to outages and highly available in a three-zone cloud.
Required components
-
Apache ZooKeeper™ - This is Pulsar’s meta data store. It stores data about a cluster’s configuration, helps the proxy direct messages to the correct broker, and holds bookie configurations. Start with 1 instance of ZooKeeper in each availability zone (AZ) to mitigate a single failure point, and scale ZooKeeper as cluster traffic increases. You could scale ZooKeeper as traffic within the cluster increases, but it shouldn’t be very often as it can handle quite a bit of load.
-
Broker - This is Pulsar’s message router. Ideally, each broker should be fully utilized without becoming a performance bottleneck. The Pulsar broker is stateless, so it requires considerable computing power but not much storage. Start with 1 broker instance in each zone, and set a scaling rule that watches CPU load. The best way to optimize this is through performance testing based on your cluster’s workload characteristics.
-
Apache BookKeeper™ (bookie) - This is Pulsar’s data store. BookKeeper stores message data in a low-latency, resilient way. Pulsar uses BookKeeper’s quorum math to function, so a loss of 1 BookKeeper instance won’t bring your system down, but will cause some data loss. Start with at least 3 bookies, with 1 in each AZ. At least 2 bookies per AZ are required for high availability, so if one bookie goes down, the other bookie in the AZ can take over. Scale bookies up on disc usage percentage. Scale down manually by making a bookie read-only, offloading its data, then terminating the instance.
Recommended server components
The DataStax Pulsar Helm chart deployment includes optional but highly recommended server components for better Pulsar cluster metrics monitoring and operation visibility.
-
BookKeeper AutoRecovery - This is a Pulsar component that recovers BookKeeper data in the event of a bookie outage. While optional you will want the insurance of AutoRecovery working on your behalf. A single instance of AutoRecovery should be adequate - only in the most heavily-used clusters will you need more.
-
Pulsar proxy - The Pulsar proxy is just that - a proxy. It runs at the edge of the cluster with public facing endpoints. Without it, your brokers would expose those endpoints, which is not an ideal configuration in production. Pulsar proxy also offers special options for cluster extensions, like the DataStax Starlight suite of APIs. Start with a proxy in each zone. The proxy will be made aware of all the brokers in the same zone and load balance across them. Have your load balancer round-robin to all proxy instances in all zones. Proxy is optional for VM deployments and required for Kubernetes deployments. Scale proxies by their network load or (if running extensions) also scale on CPU usage.
-
Dedicated functions worker(s) - You can optionally run dedicated function workers in a Pulsar cluster. Without dedicated function workers, functions run as a separate process on the broker. Function worker spec is usually focused on compute and memory. Scale the workers based on overall usage (both CPU and memory).
-
Pulsar AdminConsole - This is an optional web-based admin console for managing Pulsar clusters, and makes management much easier than tons of CLI commands. The sizing and scaling for AdminConsole has nothing to do with the cluster, as it is not a failure point.
-
Pulsar Heartbeat - This is an optional component that monitors the health of Pulsar cluster and emits metrics about the cluster that are helpful for observing and debugging issues.
-
Prometheus/Grafana/Alert manager stack - This is the default observability stack for a cluster. The DataStax Pulsar Helm chart includes pre-made dashboards in Grafana and pre-wires all the metrics scraping.
Message retention
The broker ensures messages are received and delivered appropriately, but it is a stateless process so it doesn’t use its memory to track this. Instead, the broker uses the BookKeeper instances, known as bookies, to store message data and the message’s acknowledgement state.
A great benefit of BookKeeper is its quorum policies. These policies make each bookie aware of the other bookies to form a BookKeeper cluster. With a cluster established, the cluster can have acknowledgement rules that form a data replication factor. For example, if you had 3 bookies in a BookKeeper cluster with an acknowledgement rule that at least 2 of the 3 bookies must have a copy of the data, then the cluster has a replication factor of 2. A Pulsar broker uses the managedLedgerDefaultAckQuorum and managedLedgerDefaultWriteQuorum configurations to set the bounds of this rule. For more about BookKeeper persistence, see here.
When a client produces a message, the broker will not acknowledge receipt until the replication factor has been achieved. Continuing from the above example, if the replication factor is 2, a broker’s acknowledgment means a minimum of 2 bookies have confirmed storage of message data. If the broker times out waiting for at least 2 responses from the bookies, then the broker will not acknowledge receipt with the client. The client will need to handle the exception by attempting to resend or fail. This process forms one of Pulsar’s core values - guaranteed message receipt.
Now that the broker has a message, it guarantees delivery to the associated topic’s subscribers. We refer to this as the broker’s backlog. The size of the backlog is sometimes expressed by the number of messages. For example, a Pulsar operator might say, "we try to keep the backlog below 100 messages." The number of brokers available to process messages directly impacts the size of the backlog. However, the number of messages is not a meaningful number on its own without knowing the size of the messages. Message size is essential information because it determines how full a bookie’s disk will be. If the backlog has 100 messages that are 4Gb each, then 400Gb is occupied on a bookie’s disk. If the backlog has 100 messages that are 1Kb each, then only 100Kb is occupied on the bookie’s disk. Quite a difference in storage capacity!
Until all subscribers have acknowledged receipt of a message, the broker will not mark a message as acknowledged. This is another core feature of Pulsar - guaranteed message delivery. But there are realities around this - we must assume that all functions, sinks, and clients subscribed to the message’s topic are healthy and programmed correctly to acknowledge receipt.
Unfortunately, this isn’t realistic. Things happen. Processes lock up. Networks go down. If we tell Pulsar to indefinitely attempt message delivery to all subscribers on all topics, the backlog would grow out of control, with bookie disks continuously filling and never draining. So, guaranteed message delivery must be managed with some rules.
Pulsar has different ways of managing the broker’s backlog (ie: guaranteed message delivery). Combining these different settings make up the rules of message retention. The rules of message retention directly impact how full a bookie’s disk can be. We can’t cover every possability within Pulsar’s message retention system, so we will focus on 3 key areas and let those drive our sizing calculation. For more on message retention and expiration, see Pulsar’s message retention and expiry documentation.
Retention policy
The broker’s goal is to mark a message for deletion, which means all subscribers have acknowledged message receipt and the message can be removed from the bookie’s disk. Don’t confuse this with Pulsar’s tiered storage, where you can store the broker’s backlog for a very long time. This is a different concept than retention. Sometimes you want acknowledged messages to stay on disk for a certain period of time, or until a certain size threshold has been reached. For example, when a client is constantly reading a topic’s messages and needs to have the same low latency performance as a consumer of unacknowledged messages, a highly performant reader is required.
Retention can be expressed in size or time. Expressed as size, when the broker’s backlog reaches some size threshold (in Mb), it will begin marking the oldest acknowledged messages for deletion until the size is reduced. Expressed in time, any acknowledged messages older than some time period (like 3 hours) will be marked for deletion. Size and time can also be used together to create a more comprehensive retention rule.
Pulsar’s default behavior disables retention policy, so our sizing calculations will assume this configuration. When all subscribers have acknowledged, the message is removed.
Backlog quota size
As mentioned above, the broker’s backlog size is directly proportional to how much disk is being consumed on a bookie. Pulsar provides the option to set thresholds of how large the backlog of a certain namespace can get. A policy can also be set to manage behavior for when that backlog threshold is passed.
Pulsar’s default is to not set a backlog quote on a namespace, so our sizing calculations will assume this configuration.
Message time to live (TTL)
TTL determines how long an unacknowledged message will last in the backlog before it is marked for deletion. Pulsar’s default behavior disables TTL and stores unacked messages forever, but in a production cluster, there must be limits in place to prevent bookie disks from filling up and crippling a cluster’s health.
The TTL parameter is like a stopwatch attached to each message that defines the amount of time a message is allowed to stay unacknowledged. When the TTL expires, Pulsar automatically moves the message to the acknowledged state (and thus makes it ready for deletion).
TTL is expressed in terms of time, at the namespace level. A default value for all new namespace can be set with the ttlDurationDefaultInSeconds broker configuration value.
Aggregated cluster workload
To size a cluster, you need a general understanding of what workloads it will be running. Realistically, it’s almost impossible to definitively know the exact applications and message sizes that will be used. If your cluster is successful, more teams will want to use it! So we’ve collected the "building blocks" of sizing a cluster, which we call an "aggregated cluster workload". Think of it as a loosely calculated algorithm to approximate cluster sizing.
-
Average message size (uncompressed) - this is the most important number to understand. A message is sized by the number of bytes. A message includes its message key, properties, and a message payload. A message key is roughly the same number of characters as a GUID (or hash). Message properties is a key/value collection of metadata, so the number of characters varies. The message payload accounts for the bulk of the sizing variability. To start, assume the message is a JSON string with some number of characters. For more on message compression, see the Pulsar documentation, or search for "calculate bytes of string" in your favorite search engine - you’ll find many free tools where you can type out a sample JSON-formatted string and see the byte count.
-
Incoming message throughput - this is the second most important number to understand. Throughput is expressed as a number of messages that the cluster can produce in a second. Think about this number in terms of steady traffic and burst traffic. Pulsar can scale brokers to handle bursts, so you don’t need to size for maximum workload, but you do need to consider the time it takes to scale up broker instances. If you were streaming in data every time someone clicked on a web page, and the site received a constant 2000 views per second, then your minimum throughput must be able to handle a load above that requirement, because that stream won’t be the only load on the cluster. You likewise wouldn’t size the cluster to your existing load, because you hope that load will grow over time.
-
Message retention and TTL period - the size or time acknowledged messages are kept on disk. See message retention above for more detail.
-
Tiered storage policies - Tiered storage offloads BookKeeper data to cheaper, long-term storage, and can impact cluster sizing if that storage service is included in the cluster. For our calculations we will not be including this feature. For more on tiered storage, see Pulsar documentation.
There are other factors that could be a part of the aggregated cluster workload. As you gain familiarity with Pulsar you can further customize this calculation. For now, we will estimate with the above numbers to size a cluster.
Example workload aggregation worksheet
Gather the following workload characteristics to determine your cluster’s size requirements:
| Workload input | Value |
|---|---|
Average message size |
1 Kb |
Incoming message throughput |
100000 messages per second |
Message retention |
Disabled |
TTL Policy |
3 hours |
Tiered storage |
N/A |
Example methodology
With the aggregated workload characteristics, we can now apply our methodology to these characteristics to size a production cluster.
First, size the BookKeeper disk because it’s the most important component (bookies store message data) and the hardest to scale. By default, Pulsar sets BookKeeper ack-quorum size to 2. That means at least 2 bookies in the ensemble need to acknowledge receipt of message data before Pulsar will acknowledge receipt of the message. But (very important) we want the message replication factor to be an odd number, so we can tolerate 1 bookie failure.
-
Multiply replication factor (3) by average message payload size (1) by average message throughput (100000), then factor in TTL (3) and retention period (3600) (when applicable).
Total message size (raw) = 3 * // replication factor 1 Kb * // average message payload size 100000 * // average message throughput (3 * 60 * 60) // TTL in seconds = 3,240,000,000 Kb ≅ 3 TbWe now know our cluster needs 3 Tb of storage for BookKeeper ledger data.
-
Calculate the number of BookKeeper nodes with an individual ledger disk capacity.
BookKeeper count(raw)=ceiling(3/(4 * 0.85)) = 1If our bookie has a 4Tb disk and we anticipate at least 3Tb of workload, only 1 bookie is needed. For fault tolerance, we adjust this to a number that is divisible by the number of zones, which equals 3 bookies.
-
Given the replication factor of 3, we will need at least 1 broker to write messages to the bookies. That gives us a broker-to-BookKeeper ratio of 1:3. Now we can calculate the total number of brokers across 3 zones.
broker count(raw)=ceiling(1/3) = 1We need 1 broker to serve messages. As with other components, this must account for fault tolerance. To be evenly divisible by the number of zones, we will set brokers to 3.
Pulsar component instance counts
Now that we know how many server instances of broker and bookie are required to support our workload, we include the other components to size the overall cluster.
| Component | VM Count | Notes |
|---|---|---|
ZooKeeper |
3 |
1 per zone |
BookKeeper (bookie) |
3 |
Calculated above |
Broker |
3 |
Calculated above |
Proxy |
3 |
1 per zone |
AutoRecovery |
3 |
1 per zone |
Function workers |
3 |
1 per zone |
Admin |
1 |
1 per cluster |
Heartbeat |
1 |
1 per cluster |
Next steps
See Installation topologies for specific deployment topologies and hardware recommendations.
