Build a Hotel Search Application with RAGStack and Serverless (non-vector)

This page demonstrates using RAGStack and a vector-enabled Serverless (non-vector) database to build a Hotels Search application.
The application uses a vector-enabled Serverless (non-vector) database to store hotel data, and RAGStack to search for hotels and generate summaries.
See the Hotels App README for more details on getting the app running (including on Gitpod).
Prerequisites
-
Clone the Git repository and change to that directory.
git clone https://github.com/DataStax-Examples/langchain-astrapy-hotels-app.git cd langchain-astrapy-hotels-app -
You will need a vector-enabled Serverless (non-vector) database.
-
Create an Astra vector database.
-
Within your database, create an Astra DB Access Token with Database Administrator permissions.
-
Copy your Serverless (non-vector) API Endpoint for the vector-enabled Serverless (non-vector) database, as displayed in Astra Portal.
-
-
Set the following environment variables in a
.envfile inlangchain-astrapy-hotels-app(you can use the provided.env.templateas an example):OPENAI_API_KEY=sk-... ASTRA_DB_API_ENDPOINT=https://<ASTRA_DB_ID>-<ASTRA_DB_REGION>.apps.astra.datastax.com ASTRA_DB_APPLICATION_TOKEN=AstraCS:... -
Install the required dependencies:
pip install -r requirements.txt -
Verify you have a recent version (7.0+) of
npm(needed to run the client):npm --version
See the Prerequisites page for more details on finding these values.
Load the data
-
From the root folder, run four Python scripts to populate your database with data collections.
-
Python
-
Result
python -m setup.2-populate-review-vector-collection python -m setup.3-populate-hotels-and-cities-collections python -m setup.4-create-users-collection python -m setup.5-populate-reviews-collection** [JustPreCalculatedEmbeddings] INFO: embed request for 'This is a sample sentence.'. Returning moot results [2-populate-review-vector-collection.py] Finished. 10000 rows written. [3-populate-hotels-and-cities-collections.py] Inserted 1433 hotels [3-populate-hotels-and-cities-collections.py] Inserted 842 cities [5-populate-reviews-collection.py] Inserted 10000 reviews -
-
Each script populates a different collection in your vector-enabled Serverless (non-vector) database, including a collection of precalculated embeddings for vector search.
The application will use these collections to deliver valuable, personalized results to users.
Run the application
Now that your vector database is populated, run the application frontend to see the results.
-
Open a new terminal and start the API server.
uvicorn api:app --reload -
Open a new terminal and change directory to the
clientfolder (cd client). Install the node dependencies and start the application.npm install npm start -
Open http://localhost:3000 to view the application in your browser. Click "Login" in the upper right corner, enter any values for the username and password, and click Login.
-
Enter
USfor the country and a US city for the location, and click Search. -
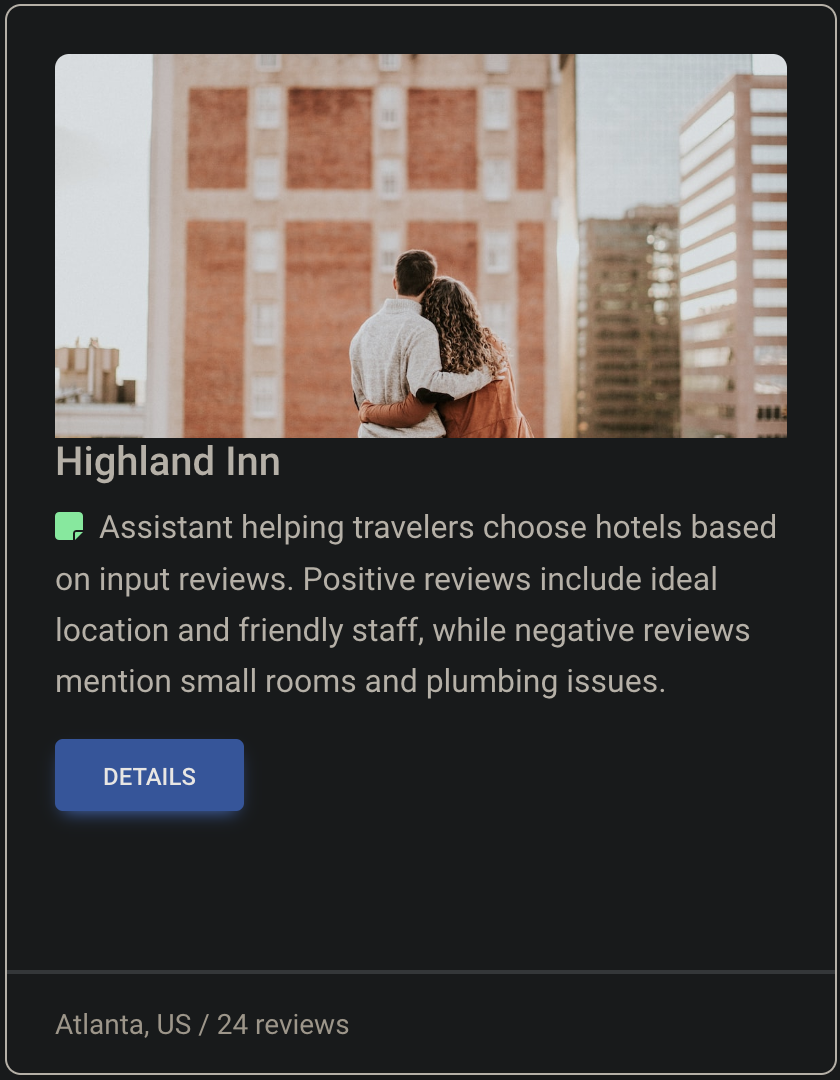
The application lists hotels, including an OpenAI-generated summary of reviews from the reviews collection.
-
Selecting "Details" will show more information about the hotel, including a summary based on your Preferences, stored in the users collection.
-
The "Preferences" section lets you edit your profile, so that the "Details" for a hotel will be re-calculated, possibly highlighting different reviews and adapting the AI-generated summary at the top.
Cleanup
-
Use
ctrl+cin both terminals, to stop the API server and the application. -
Launch the following cleanup script to delete all collections used by the application:
python -m setup.cleanup-delete-all-collections
