Cassandra Basics
What is Apache Cassandra®?
Cassandra is a NoSQL distributed database. By design, NoSQL databases are lightweight, open-source, non-relational, and largely distributed. Counted among their strengths are horizontal scalability, distributed architectures, and a flexible approach to schema definition.
NoSQL databases enable rapid, ad-hoc organization and analysis of extremely high-volume, disparate data types. That’s become more important in recent years, with the advent of Big Data and the need to rapidly scale databases in the cloud. Cassandra is among the NoSQL databases that have addressed the constraints of previous data management technologies, such as SQL databases.
Distribution provides power and resilience
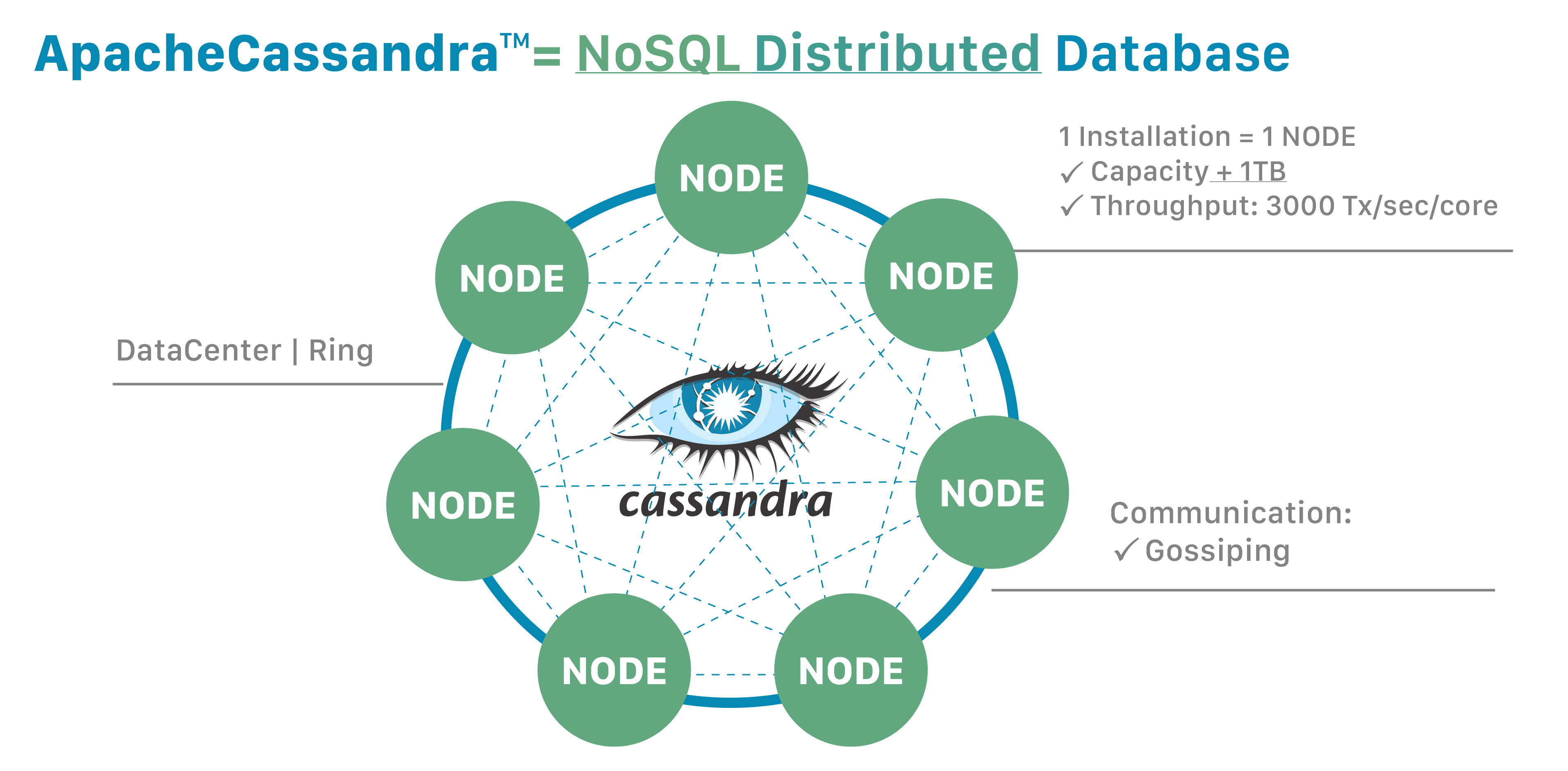 One important Cassandra attribute is that its databases are distributed.
That yields both technical and business advantages.
Cassandra databases easily scale when an application is under high stress, and the distribution also prevents data loss from any given datacenter’s hardware failure.
A distributed architecture also brings technical power; for example, a developer can tweak the throughput of read queries or write queries in isolation.
One important Cassandra attribute is that its databases are distributed.
That yields both technical and business advantages.
Cassandra databases easily scale when an application is under high stress, and the distribution also prevents data loss from any given datacenter’s hardware failure.
A distributed architecture also brings technical power; for example, a developer can tweak the throughput of read queries or write queries in isolation.
"Distributed" means that Cassandra can run on multiple machines while appearing to users as a unified whole. There is little point in running Cassandra as a single node, although it is very helpful to do so to help you get up to speed on how it works. But to get the maximum benefit out of Cassandra, you would run it on multiple machines.
Since it is a distributed database, Cassandra can (and usually does) have multiple nodes. A node represents a single instance of Cassandra. These nodes communicate with one another through a protocol called gossip, which is a process of computer peer-to-peer communication. Cassandra also has a peer-to-peer architecture - any node in the database can provide the exact same functionality as any other node - contributing to Cassandra’s robustness and resilience. Multiple nodes can be organized logically into a cluster, or "ring". You can also have multiple datacenters.
Want more power? Add more nodes
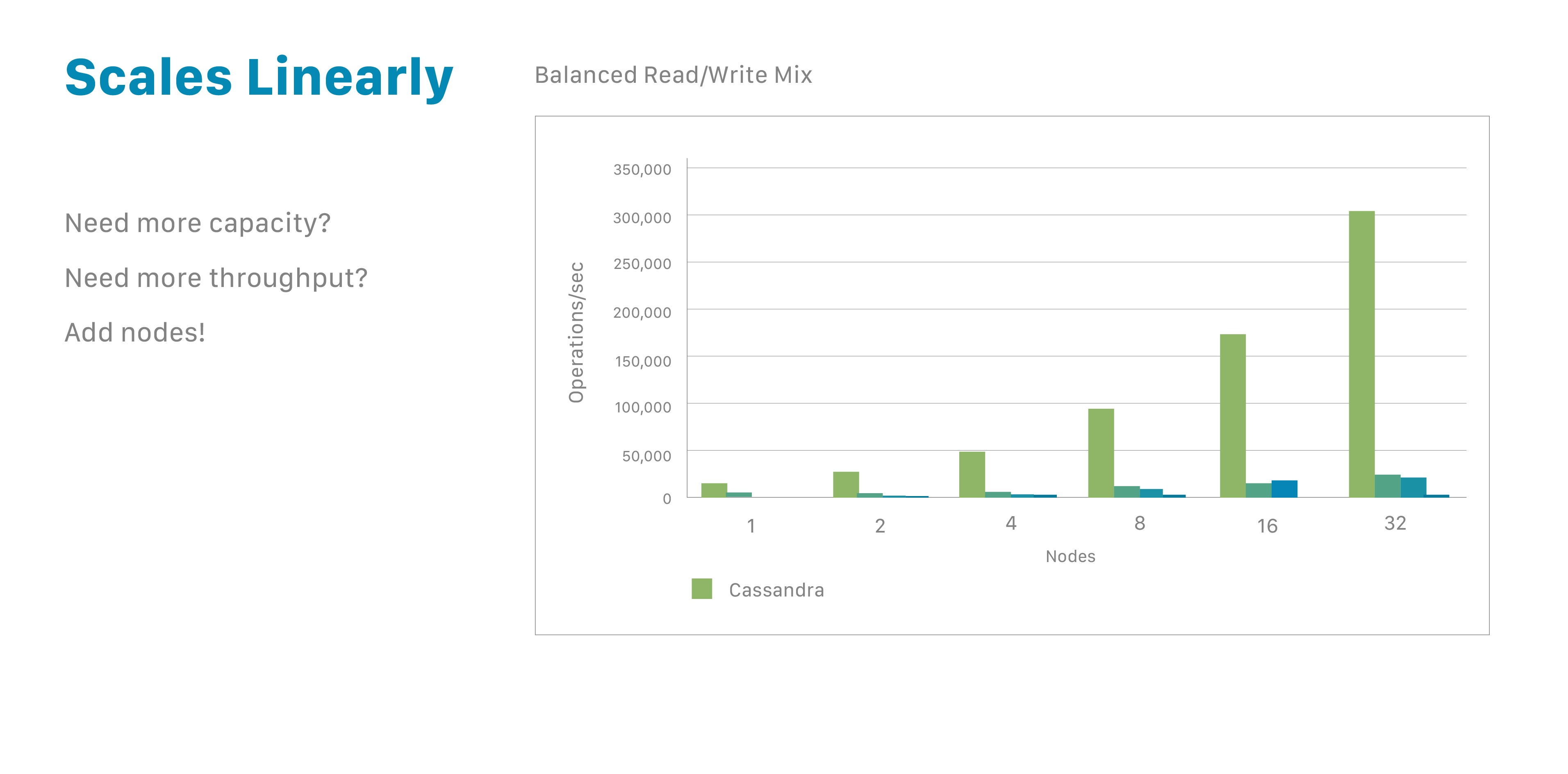
 One reason for Cassandra’s popularity is that it enables developers to scale their databases dynamically, using off-the-shelf hardware, with no downtime.
You can expand when you need to, and also shrink, if the application requirements suggest that path.
One reason for Cassandra’s popularity is that it enables developers to scale their databases dynamically, using off-the-shelf hardware, with no downtime.
You can expand when you need to, and also shrink, if the application requirements suggest that path.
Perhaps you are used to Oracle or MySQL databases. If so, you know that extending them to support more users or storage capacity requires you to add more CPU power, RAM, or faster disks. Each of those costs a significant amount of money. And yet: Eventually you still encounter some ceilings and constraints.
In contrast, Cassandra makes it easy to increase the amount of data it can manage. Because it’s based on nodes, Cassandra scales horizontally (aka scale-out), using lower commodity hardware. To double your capacity or double your throughput, double the number of nodes. That’s all it takes. Need more power? Add more nodes - whether that’s 8 more or 8,000 - with no downtime. You also have the flexibility to scale back if you wish.
This linear scalability applies essentially indefinitely. This capability has become one of Cassandra’s key strengths.
Introducing partitions
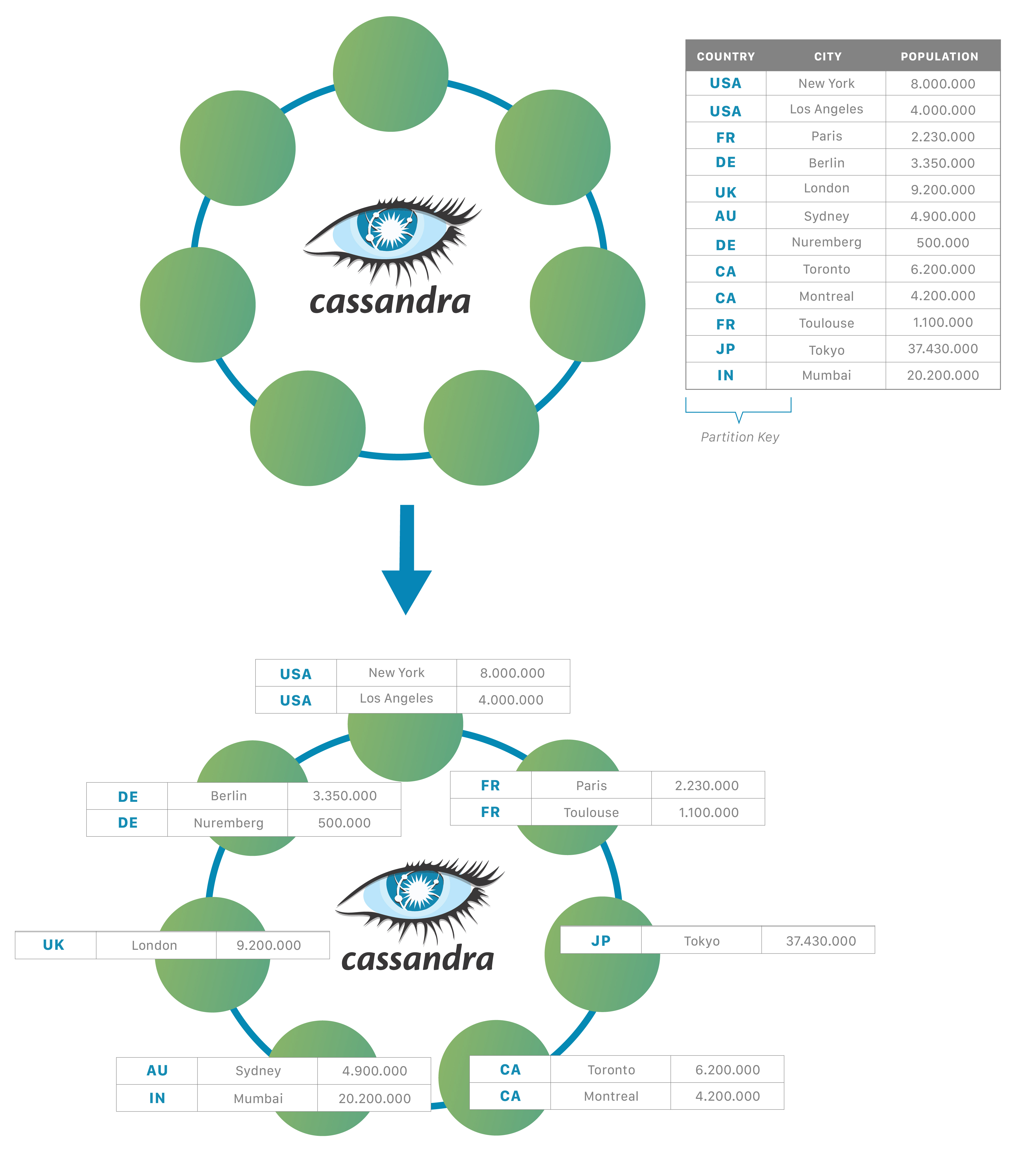
 In Cassandra, the data itself is automatically distributed, with (positive) performance consequences.
It accomplishes this using partitions.
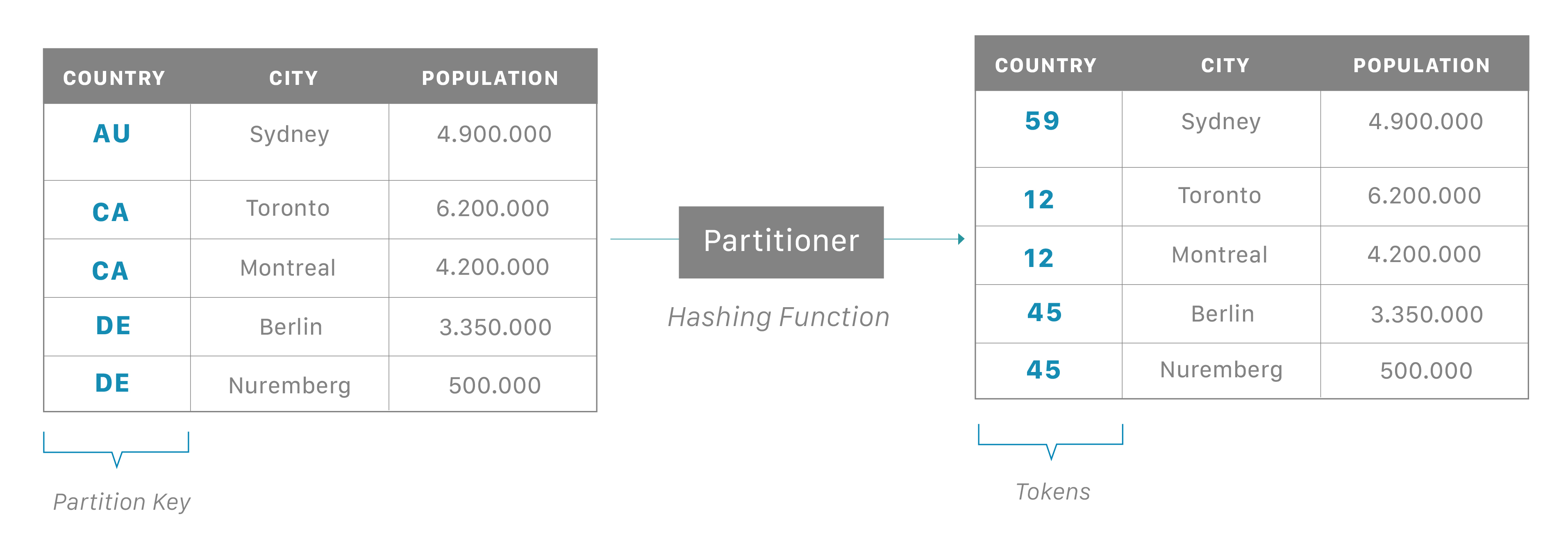
Each node owns a particular set of tokens, and Cassandra distributes data based on the ranges of these tokens across the cluster.
The partition key is responsible for distributing data among nodes and is important for determining data locality.
When data is inserted into the cluster, the first step is to apply a hash function to the partition key. The output is used to determine what node (based on the token range) will get the data.
In Cassandra, the data itself is automatically distributed, with (positive) performance consequences.
It accomplishes this using partitions.
Each node owns a particular set of tokens, and Cassandra distributes data based on the ranges of these tokens across the cluster.
The partition key is responsible for distributing data among nodes and is important for determining data locality.
When data is inserted into the cluster, the first step is to apply a hash function to the partition key. The output is used to determine what node (based on the token range) will get the data.
 When data comes in, the database’s coordinator takes on the job of assigning to a given partition - let’s call it partition 59.
Remember that any node in the cluster can take on the role as the coordinator.
As we mentioned earlier, nodes gossip to one another; during which they communicate about which node is responsible for what ranges.
So in our example, the coordinator does a lookup: Which node has the token 59?
When it finds the right one, it forwards that data to that node.
The node that owns the data for that range is called a replica node.
One piece of data can be replicated to multiple (replica) nodes, ensuring reliability and fault tolerance. So far, our data has only been replicated to one replica.
This represents a replication factor of one, or RF = 1.
When data comes in, the database’s coordinator takes on the job of assigning to a given partition - let’s call it partition 59.
Remember that any node in the cluster can take on the role as the coordinator.
As we mentioned earlier, nodes gossip to one another; during which they communicate about which node is responsible for what ranges.
So in our example, the coordinator does a lookup: Which node has the token 59?
When it finds the right one, it forwards that data to that node.
The node that owns the data for that range is called a replica node.
One piece of data can be replicated to multiple (replica) nodes, ensuring reliability and fault tolerance. So far, our data has only been replicated to one replica.
This represents a replication factor of one, or RF = 1.
The coordinator node isn’t a single location; the system would be fragile if it were. It’s simply the node that gets the request at that particular moment. Any node can act as the coordinator.
Replication ensures reliability and fault tolerance
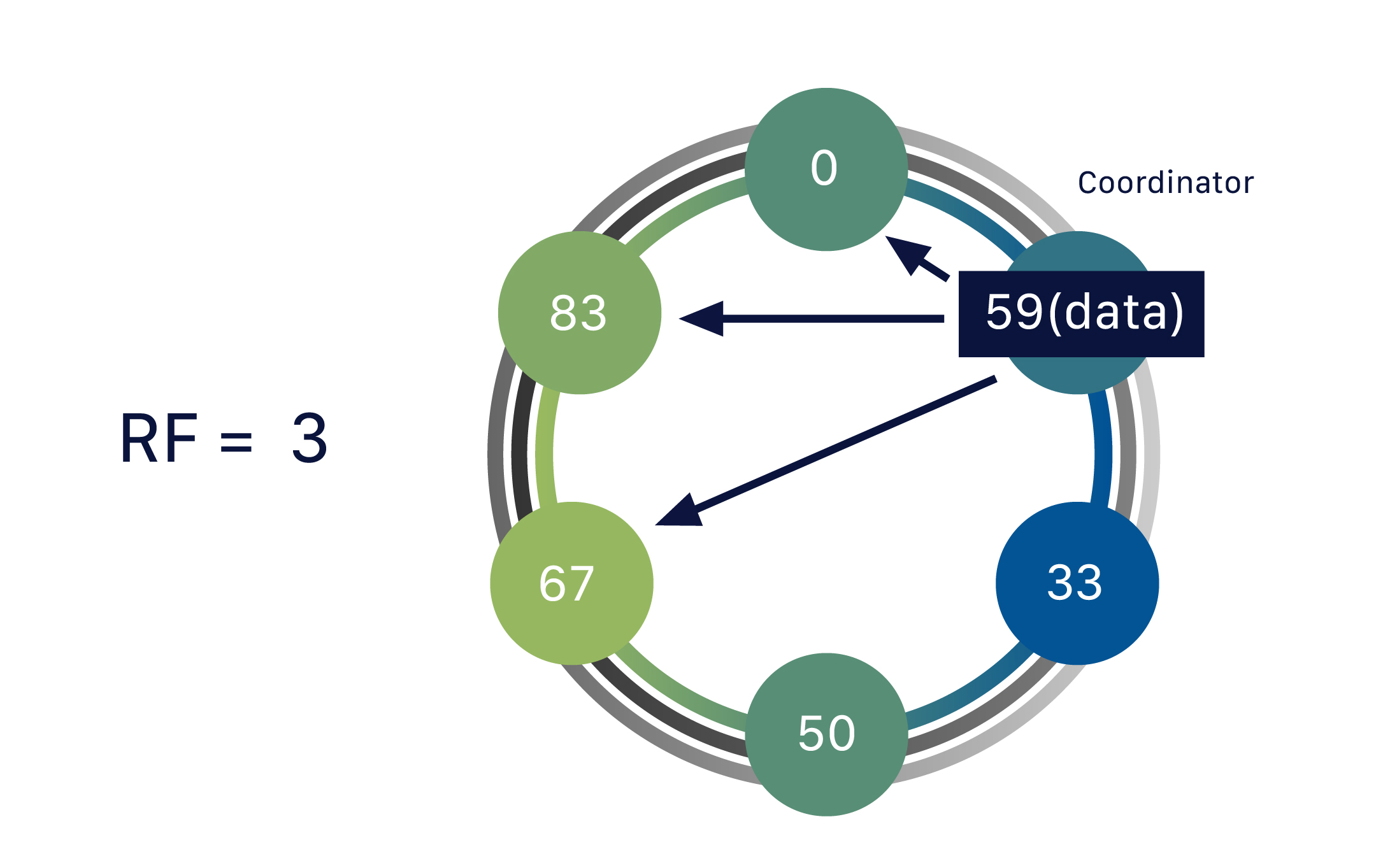 One piece of data can be replicated to multiple (replica) nodes, ensuring reliability and fault tolerance. Cassandra supports the notion of a replication factor (RF), which describes how many copies of your data should exist in the database.
So far, our data has only been replicated to one replica (RF = 1).
If we up this to a replication factor of two (RF = 2), the data needs to be stored on a second replica as well - and hence each node becomes responsible for a secondary range of tokens, in addition to its primary range.
A replication factor of three ensures that there are three nodes (replicas) covering that particular token range, and the data is stored on yet another one.
One piece of data can be replicated to multiple (replica) nodes, ensuring reliability and fault tolerance. Cassandra supports the notion of a replication factor (RF), which describes how many copies of your data should exist in the database.
So far, our data has only been replicated to one replica (RF = 1).
If we up this to a replication factor of two (RF = 2), the data needs to be stored on a second replica as well - and hence each node becomes responsible for a secondary range of tokens, in addition to its primary range.
A replication factor of three ensures that there are three nodes (replicas) covering that particular token range, and the data is stored on yet another one.
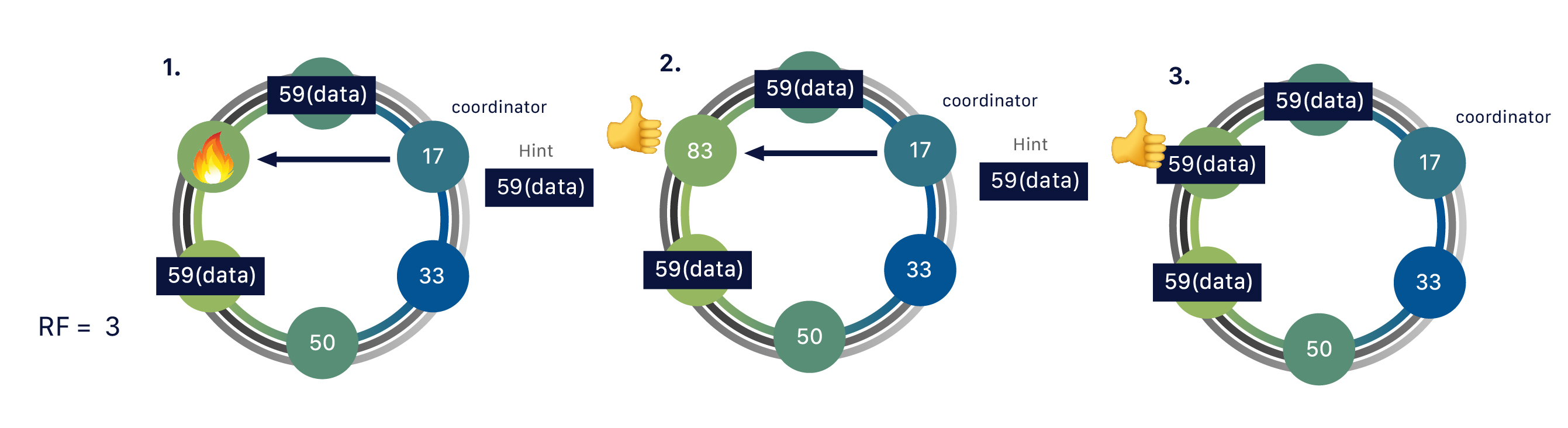 The distributed nature of Cassandra makes it more resilient and performant.
This really comes into play when we have multiple replicas for the same data.
Doing so helps the system to be self-healing if something goes wrong, such as if a node goes down, a hard drive fails, or AWS resets an instance.
Replication ensures that data isn’t lost.
If a request comes in for data, even if one of our replicas has gone down, the other two are still available to fulfill the request.
The coordinator stores a “hint” for that data as well, and when the downed replica comes back up, it will find out what it missed, and catch up to speed with the other two replicas.
No manual action is required, this is done completely automatically.
The distributed nature of Cassandra makes it more resilient and performant.
This really comes into play when we have multiple replicas for the same data.
Doing so helps the system to be self-healing if something goes wrong, such as if a node goes down, a hard drive fails, or AWS resets an instance.
Replication ensures that data isn’t lost.
If a request comes in for data, even if one of our replicas has gone down, the other two are still available to fulfill the request.
The coordinator stores a “hint” for that data as well, and when the downed replica comes back up, it will find out what it missed, and catch up to speed with the other two replicas.
No manual action is required, this is done completely automatically.
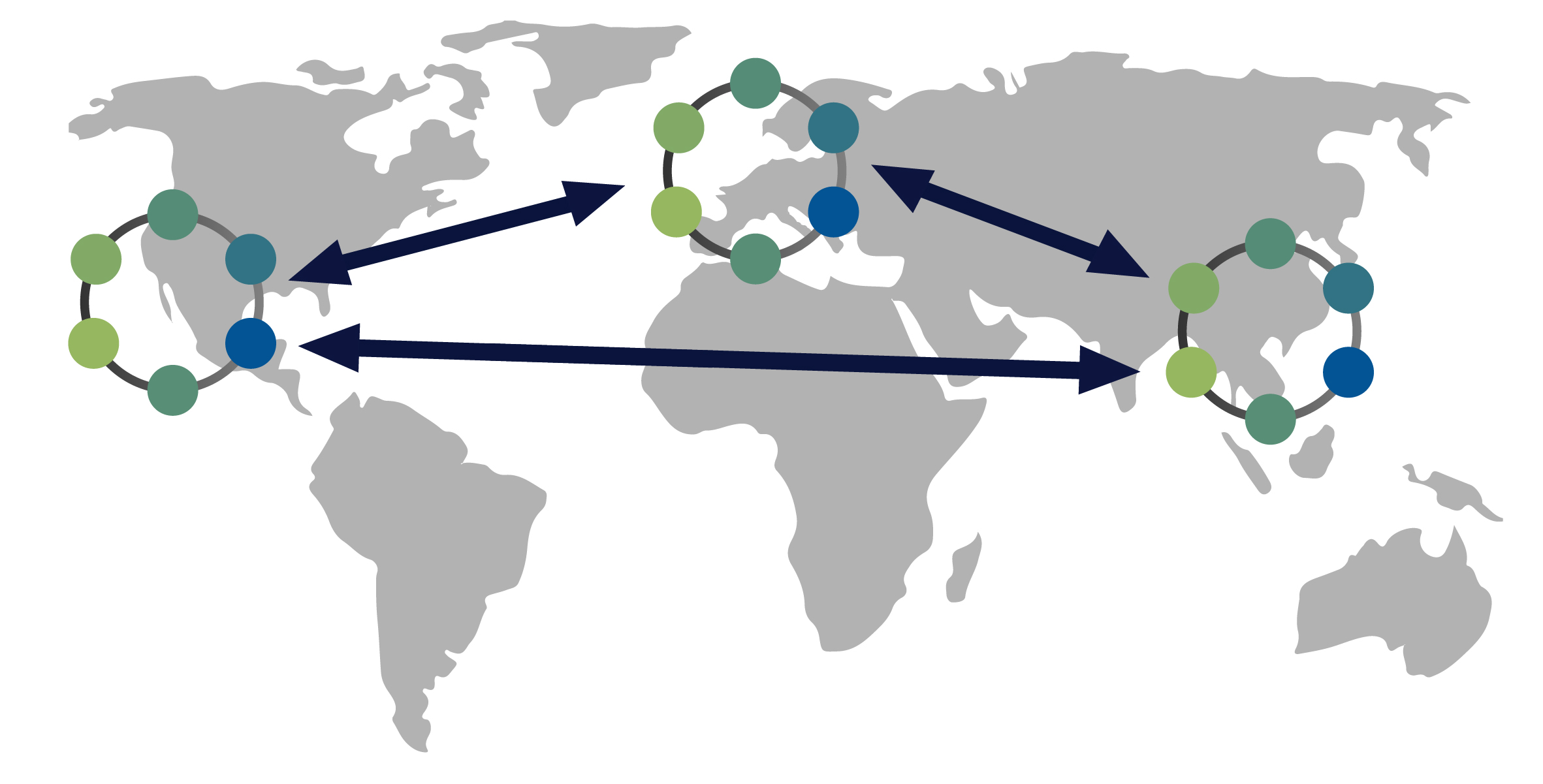 The use of multiple replicas also has performance advantages.
Because you aren’t limited to a single instance, there are three nodes (replicas) that can be accessed to provide data for our operations, which we can load balance amongst to achieve the best performance.
The use of multiple replicas also has performance advantages.
Because you aren’t limited to a single instance, there are three nodes (replicas) that can be accessed to provide data for our operations, which we can load balance amongst to achieve the best performance.
Cassandra automatically replicates that data around your different data centers. Your application can write data to a Cassandra node on the U.S. west coast, and that data is automatically available in data centers at nodes in Asia and Europe. That has positive performance advantages - especially if you support a worldwide user base. In a world dependent on cloud computing and fast data access, no user suffers from latency due to distance
Tuning your consistency
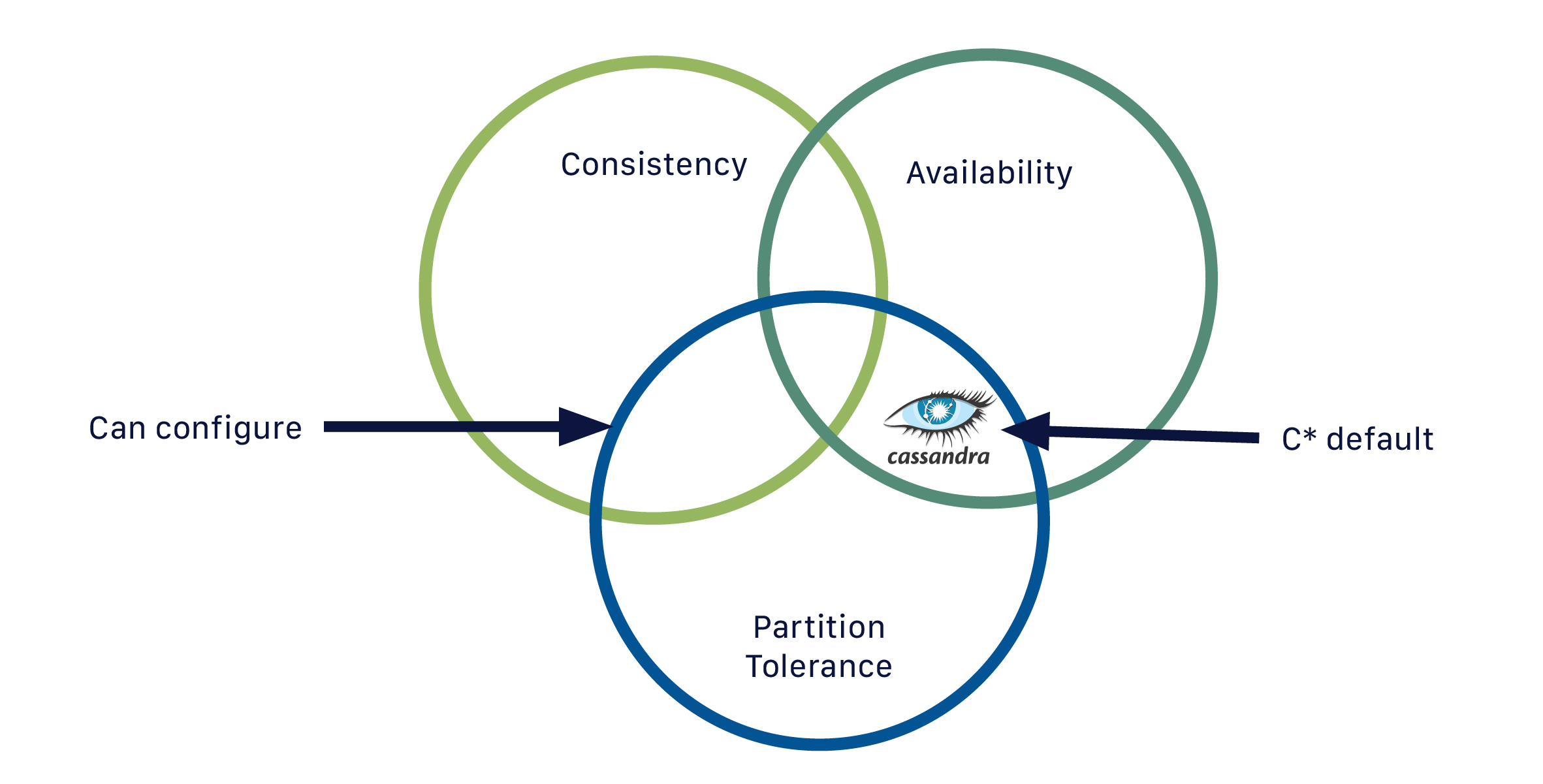 If you are familiar with CAP theorem, Cassandra is by default an AP (Available Partition-tolerant) database, hence it is “always on”.
But you can indeed configure the consistency on a per-query basis.
In this context, the consistency level represents the minimum number of Cassandra nodes that must acknowledge a read or write operation to the coordinator before the operation is considered successful.
As a general rule, you will select your consistency level (CL) based on your replication factor.
If you are familiar with CAP theorem, Cassandra is by default an AP (Available Partition-tolerant) database, hence it is “always on”.
But you can indeed configure the consistency on a per-query basis.
In this context, the consistency level represents the minimum number of Cassandra nodes that must acknowledge a read or write operation to the coordinator before the operation is considered successful.
As a general rule, you will select your consistency level (CL) based on your replication factor.
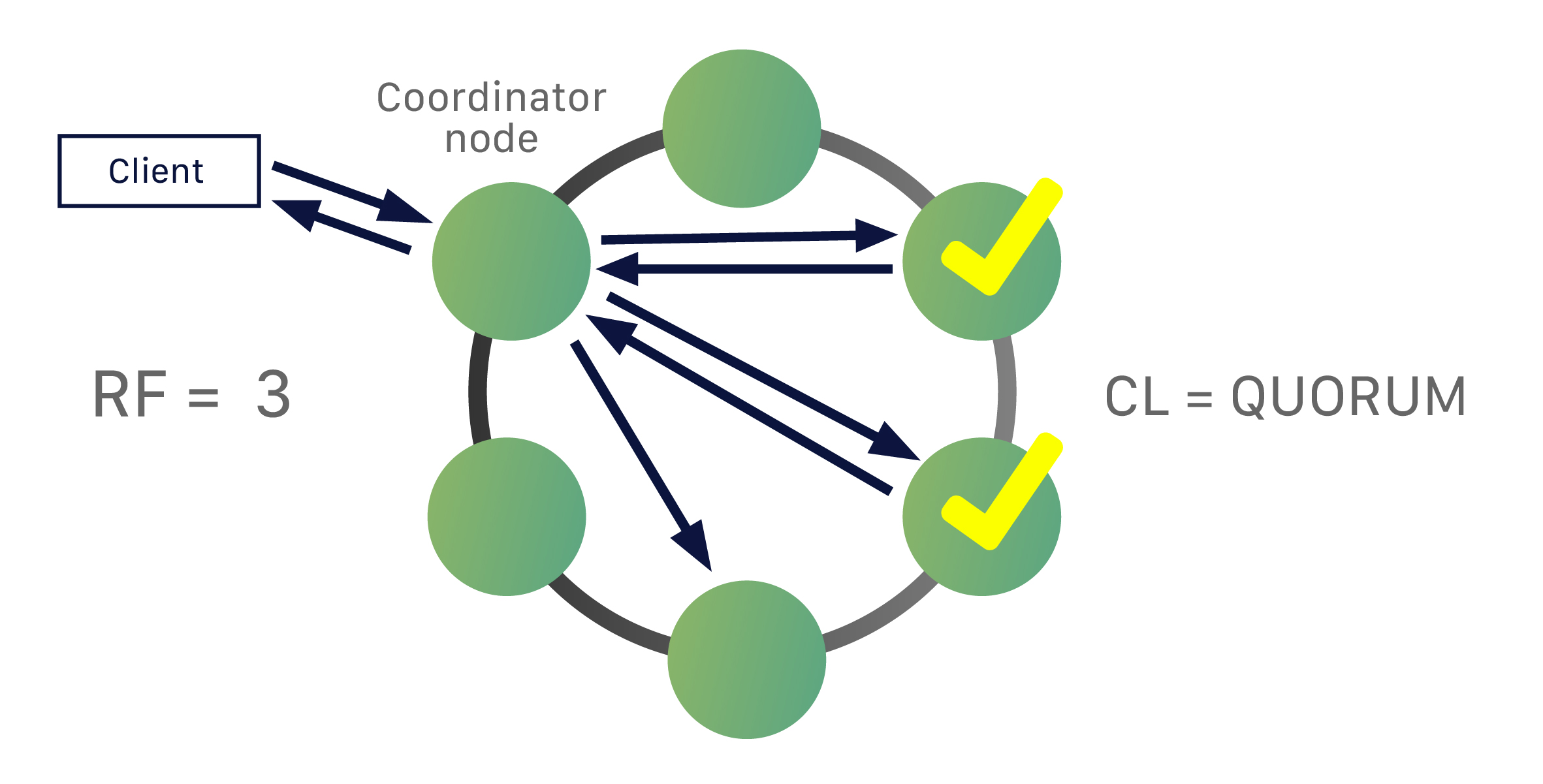 For the example below, your data is replicated out to three nodes.
The consistency level is CL=QUORUM (Quorum referring to majority, 2 replicas in this case or RF/2 +1) therefore the coordinator will need to get acknowledgement back from two of the replicas in order for the query to be considered a success.
For the example below, your data is replicated out to three nodes.
The consistency level is CL=QUORUM (Quorum referring to majority, 2 replicas in this case or RF/2 +1) therefore the coordinator will need to get acknowledgement back from two of the replicas in order for the query to be considered a success.
As with other computing tasks, it can take some skill to learn to tune this feature for ideal performance, availability, and data integrity - but the fact that you can control it with such granularity means you can control deployments in great detail.
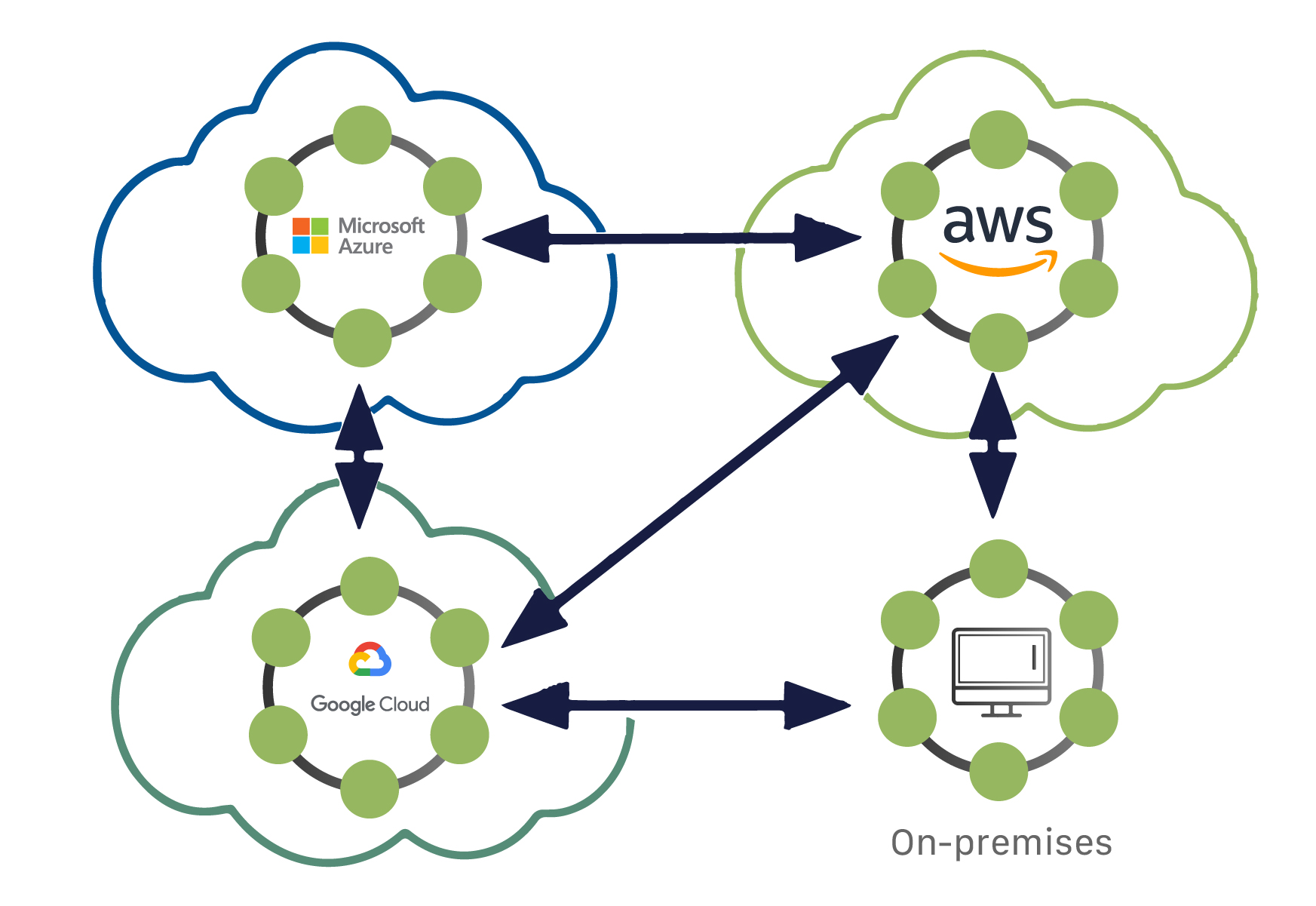 Ultimately, Cassandra is deployment agnostic.
It doesn’t care where you put it - on prem, a cloud provider, multiple cloud providers.
You can use a combination of those for a single database. That gives software developers the maximum amount of flexibility.
Ultimately, Cassandra is deployment agnostic.
It doesn’t care where you put it - on prem, a cloud provider, multiple cloud providers.
You can use a combination of those for a single database. That gives software developers the maximum amount of flexibility.
