Restarting a cluster
Restart an entire cluster in OpsCenter monitoring. Each node in the cluster restarts in a sequential rolling fashion after a sleep time elapses. Adjust the default rolling restart configuration options if necessary.
Restart an entire cluster in OpsCenter monitoring. Each node in the cluster restarts in a sequential rolling fashion after a sleep time elapses. Optionally, drain each node before stopping and restarting each node in the cluster. Some operations such as enabling commit log backups prompt you to perform a rolling restart. There are rolling restart configuration options available for fine-tuning your environment.
Adjusting rolling restart configuration options
If your environment experiences restart node failures, adjustments might be necessary to the default rolling restart configuration values in cluster_name.conf:
- [cassandra] rolling_restart_error_threshold
- A rolling restart will be cancelled if the number of errors during the restart reaches this number. This helps prevent having too many nodes down in your cluster if something catastrophic happens during a rolling restart. Default: 1
- [cassandra] rolling_restart_retry_attempts
- The maximum number of connection retry attempts after restarting a Cassandra node. Default: 25.
- [cassandra] rolling_restart_retry_delay
- The number of seconds to wait between retry attempts when connecting to Cassandra after restarting a node. Default: 5.
- [cassandra] restart_delay
- During a rolling restart, the time in seconds OpsCenter waits after sending the command to stop Cassandra before sending the command to start it again. The default is 30 seconds.
cluster_name.conf
The location of the cluster_name.conf file depends on the type of installation:
- Package installations: /etc/opscenter/clusters/cluster_name.conf
- Tarball installations: install_location/conf/clusters/cluster_name.conf
Procedure
-
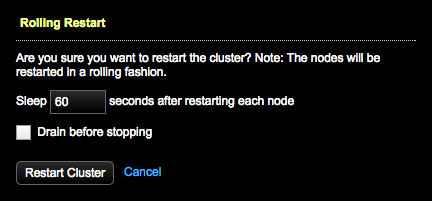
Click Restart from the Cluster
Actions menu.
The Rolling Restart dialog appears.
-
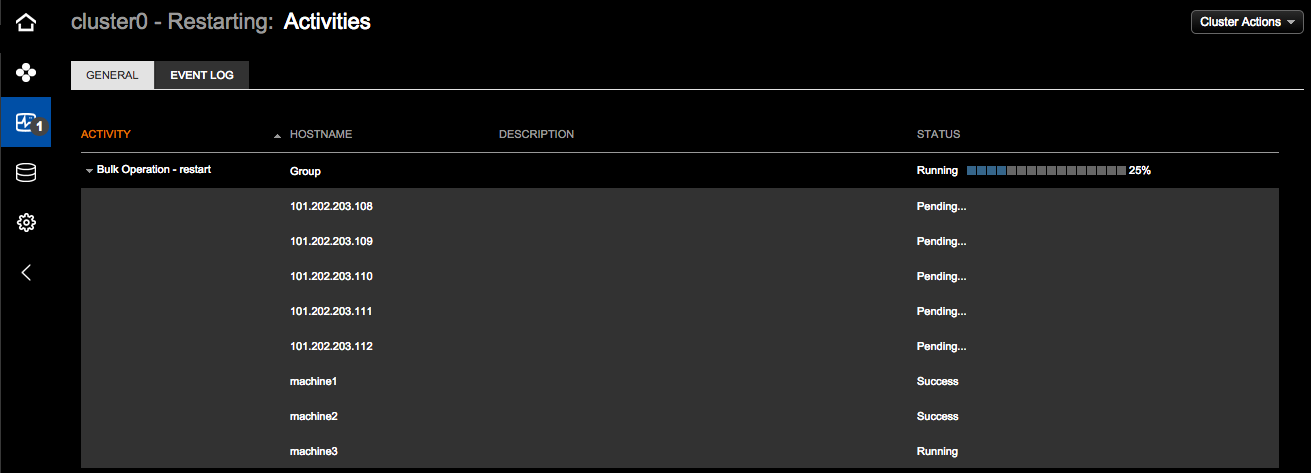
To view the progress, click Show Details in the message,
or click Activities in the left navigation pane. The
Activities icon reflects the number of operations currently in progress. A
cluster successfully restarted message indicates when the restart cluster
operation has completed.