Anti-entropy repair
Anti-entropy repairs are important for every Apache Cassandra® cluster.
Frequent data deletions and downed nodes are common causes of data inconsistency.
Use anti-entropy repair for routine maintenance and when a cluster needs fixing by running nodetool repair.
How does anti-entropy repair work?
Cassandra accomplishes anti-entropy repair using Merkle trees, which are binary hash trees whose leaves are hashes of the individual key values, similar to Dynamo and Riak. The anti-entropy process compares the data of all replicas and updates each replica to the newest version. Cassandra has two phases to the process:
-
Build a Merkle tree for each replica
-
Compare the Merkle trees to discover differences
The leaf of a Merkle tree is the hash of a row value. Each parent node higher in the tree is a hash of its respective children. Because higher nodes in the Merkle tree represent data further down the tree, Cassandra can check each branch independently without requiring the coordinator node to download the entire data set.
For anti-entropy repair, HCD uses a compact tree version with a depth of 15 (215 = 32K leaf nodes). For example, for a node containing one million partitions with one damaged partition, about 30 partitions are streamed, which is the number that fall into each of the leaves of the tree. HCD works with smaller Merkle trees because they require less storage memory and can be transferred more quickly to other nodes during the comparison process.
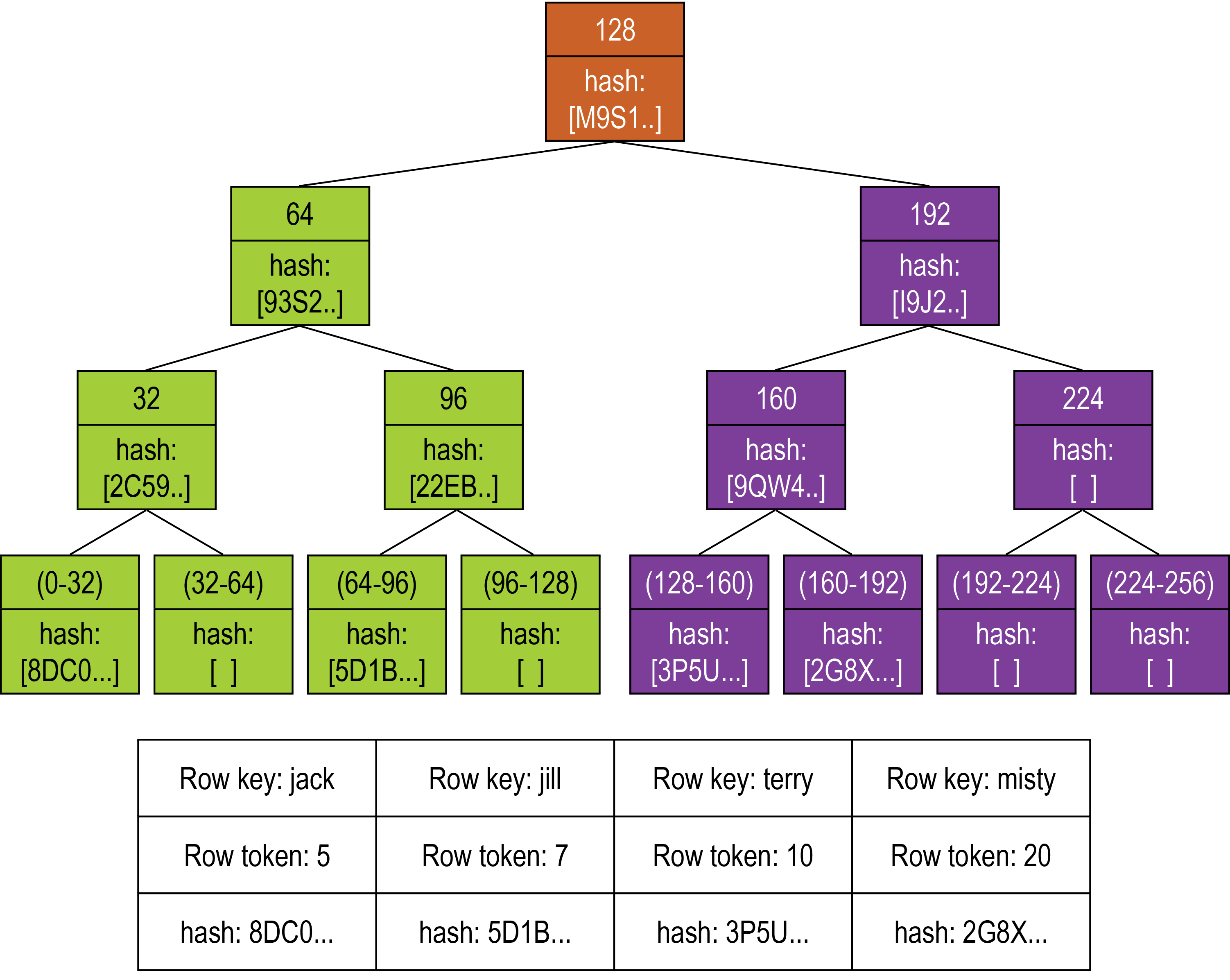
After the initiating node receives the Merkle trees from the participating peer nodes, the initiating node compares every tree to every other tree. If a difference is detected, the differing nodes exchange data for the conflicting range(s), and the new data is written to SSTables.
The comparison begins with the top node of the Merkle tree. If no difference is detected, then the data requires no repair. If a difference is detected, then the process proceeds to the left child node and compares and then the right child node. When a node is found to differ, inconsistent data exists for the range that pertains to that node. All data that corresponds to the leaves below that Merkle tree node will be replaced with new data. For any given replica set, HCD performs validation compaction on only one replica at a time.
Merkle tree building is resource intensive, stressing disk I/O and using memory. Some options discussed here help lessen the impact on the cluster performance.
Run the nodetool repair -pr command on either a specified node or all nodes.
Running nodetool repair -pr on a designated node will repair the subset of data owned by the target node cluster-wide.
The subset of data is determined by the token range owned by the node.
Data owned by this node will be repaired throughout the cluster.
Running nodetool repair on all nodes will repair the subset of data owned by any node in the cluster.
By including all nodes, all data subsets in the cluster will be repaired.
The Repair in Cassandra blog post discusses this process in more detail.
Sequential vs Parallel repair
Sequential repair with the -seq, --sequential flag takes action on one node after another.
Parallel repair without the sequential flag specified repairs all nodes with the same replica data at the same time.
Datacenter parallel, -dc-par, combines sequential and parallel by simultaneously running a sequential repair in all datacenters; one node in each datacenter runs repair until the repair is complete.
Sequential repair takes a snapshot of each replica. Snapshots are hardlinks to existing SSTables. They are immutable and require almost no disk space. The snapshots are active while the repair proceeds, then the database deletes them.
When the coordinator node finds discrepancies in the Merkle trees, the coordinator node makes required repairs from the snapshots. For example, for a table in a keyspace with a replication factor of three (RF=3) and replicas A, B, and C, the repair command takes a snapshot of each replica immediately and then repairs each replica from the snapshots sequentially (using snapshot A to repair replica B, then snapshot A to repair replica C, then snapshot B to repair replica C).
Parallel repair constructs the Merkle tables for all nodes in all datacenters at the same time. It works on nodes A, B, and C all at once. During parallel repair, the dynamic snitch processes queries for this table using a replica in the snapshot that is not undergoing repair. Use parallel repair to complete the repair quickly or when you have operational downtime that allows the resources to be completely consumed during the repair.
Datacenter parallel repair, unlike sequential repair, constructs the Merkle tables for all datacenters at the same time. Therefore, no snapshots are required or generated.
