How is data deleted?
The processes for deleting data are designed to improve performance and work with the Hyper-Converged Database (HCD) database built-in properties for data distribution and fault-tolerance.
The database treats a delete as an insert or upsert.
The data being added to the partition in the DELETE command is a deletion marker called a tombstone.
The tombstones go through the write path, and are written to SSTables on one or more nodes.
A key differentiator of a tombstone is a built-in expiration known as the grace period, set by gc_grace_seconds.
At the end of its expiration period, the tombstone will be deleted as part of the normal compaction process, if it no longer marks any deleted data in another SSTable.
Marking a record (row or column) with a time-to-live (TTL) value indicates that when the specified time ends, the database marks the record with a tombstone and handles it like other tombstoned records.
|
For more information about tombstones, see What are tombstones? |
Deletion in a distributed system
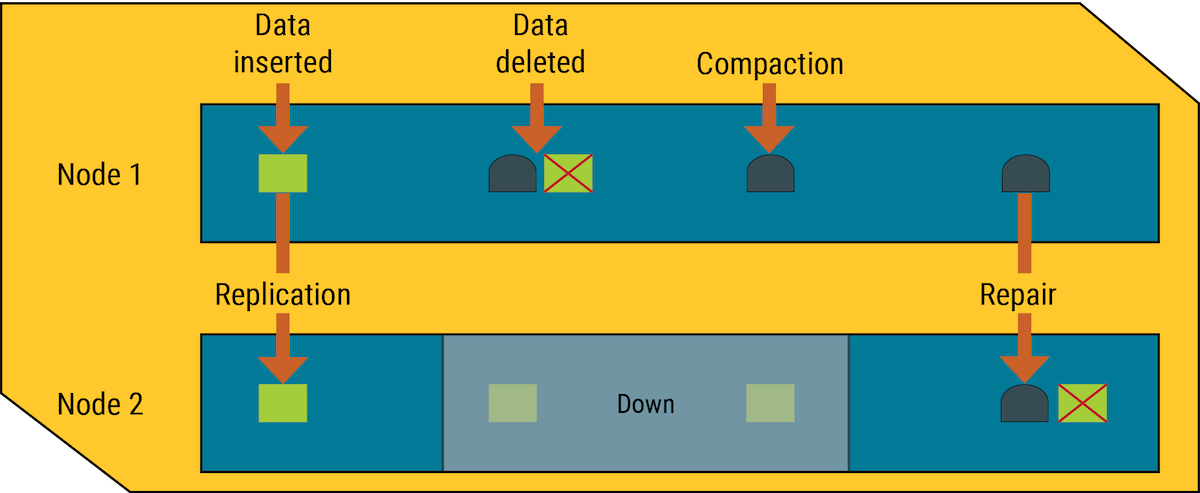
In a multi-node cluster, HCD can store replicas of the same data on two or more nodes. This helps prevent data loss, but complicates the delete process. If a node receives a delete for data it stores locally, the node marks the specified record for deletion and tries to pass the tombstone to other nodes containing replicas of that record. If one replica node is unresponsive at that time, it does not receive the tombstone immediately, so it still contains the pre-delete version of the record.
If the tombstone has already been deleted from the rest of the cluster before that node recovers, the database treats the record on the recovered node as new data, and propagates it to the rest of the cluster. This kind of deleted but persistent record is called a zombie.
To prevent the reappearance of zombies, the database gives each tombstone a grace period. The purpose of the grace period is to give unresponsive nodes time to recover and process tombstones normally. When multiple replica answers are part of a read request, and those responses differ, then whichever values are most recent take precedence. For example, if a node has a tombstone but another node has a more recent change, then the final result includes the more recent change.
If a node has a tombstone and another node has only an older value for the record, then the final record will have the tombstone. If a client writes a new update to the tombstone during the grace period, the database overwrites the tombstone.
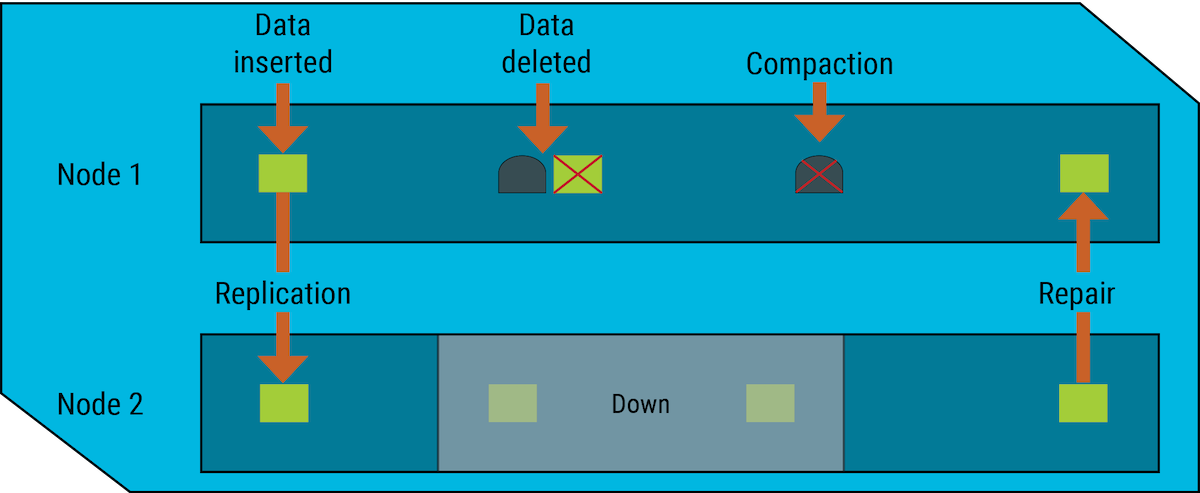
When an unresponsive node recovers, HCD uses hinted handoffs to replay the database mutations that the node missed while it was down. HCD does not replay a mutation for a tombstone during its grace period. If the node does not recover until after the grace period ends, the deletion might be missed.
After the tombstone’s grace period ends, HCD deletes the tombstone during compaction.
Expiring data
The grace period for a tombstone is set by the gc_grace_seconds property.
The default value is 864,000 seconds (ten days), and each table can have its own value for this property.
On a single-node cluster, this property can safely be set to zero.
-
The expiration date/time for a tombstone is the date/time of its creation plus the value of the
gc_grace_secondsproperty. -
To completely prevent the reappearance of zombie records, run
nodetool repairon a node after it recovers, and on each table every interval set bygc_grace_seconds.
If all records in a table are given a TTL at creation, are allowed to expire, and are not deleted manually, it is not necessary to run nodetool repair for that table on a regular basis.
For more information on expiring data with TTL, see Expiring data with TTL.
If using SizeTieredCompactionStrategy (STCS), delete any expired tombstones immediately by manually starting the compaction process with
nodetool compact.
|
If forcing compaction, the database might create one very large SSTable from all the data and will not trigger another compaction for a long time. The data in the SSTable created during the forced compaction can grow very stale during this long period of non-compaction. |
HCD also supports batch data insertion and updates. This procedure introduces the danger of replaying a record insertion after that record has been removed from the rest of the cluster. HCD does not replay a batched mutation for a tombstone that is still within its grace period.
HCD supports immediate deletion through the DROP KEYSPACE and DROP TABLE statements.
Diagram legend
The following table explains the icons in the delete diagrams:
| Icon | Description |
|---|---|

|
Data on a node. |

|
Data on an unavailable replica node. |

|
Data removed from node. |

|
Tombstone indicating that data has been deleted. |

|
Tombstone removed from node. |
