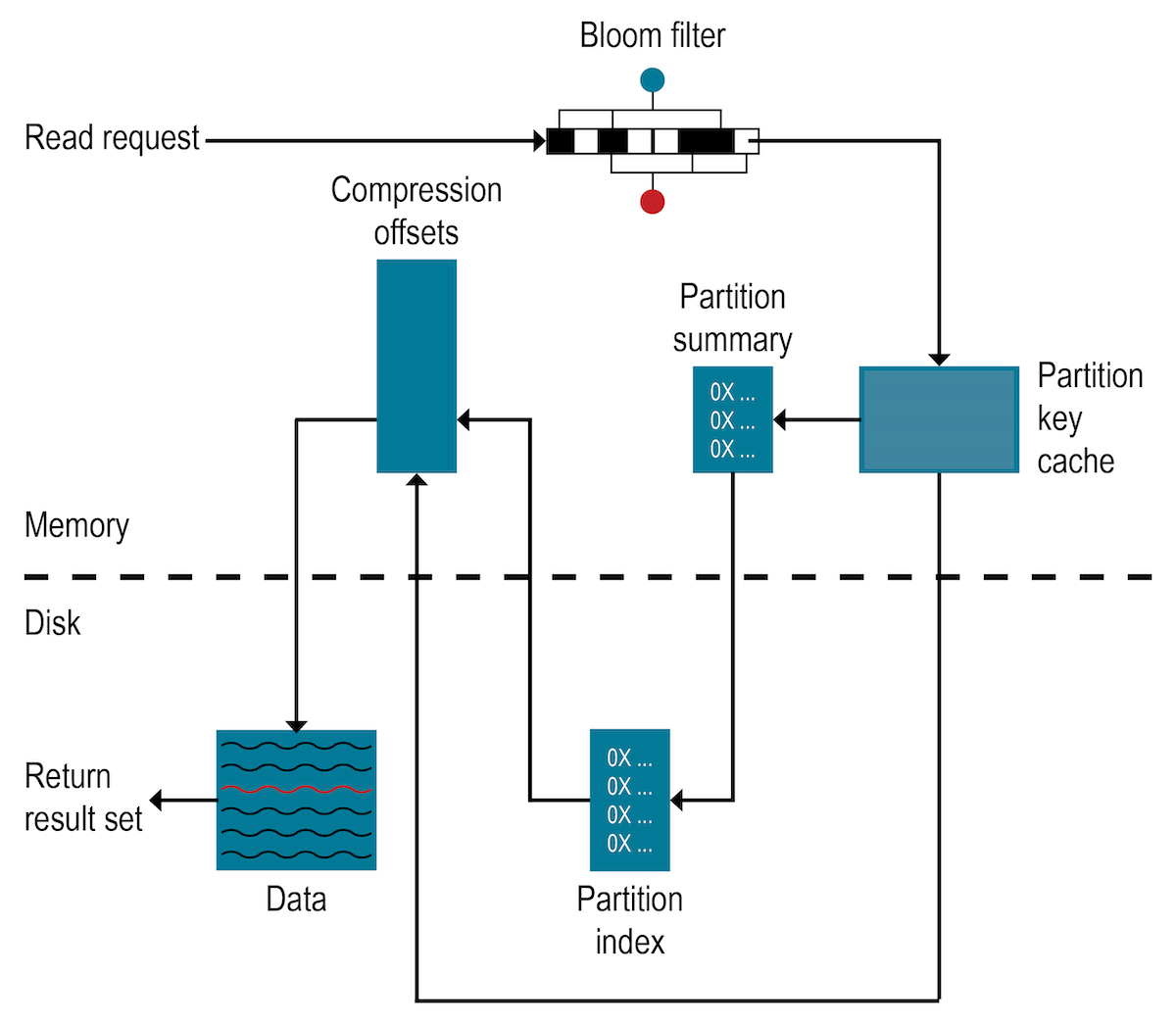
How is data read?
To satisfy a read, the Hyper-Converged Database (HCD) database must combine results from the active memtable and potentially multiple SSTables. If the memtable has the desired partition data, then the data is read and merged with the data from the SSTables.
The database processes data at several stages on the read path to discover where the data is stored, starting with the data in the memtable and finishing with SSTables:
-
Check the memtable
-
Check row cache, if enabled
-
Check Bloom filter
-
Find the partition offset in the partition index in the chunk cache/memory
-
If any required index data is not present in the cache, pull it from disk
-
Read the data from the uncompressed chunk cache
-
If any required data chunk is not present in the cache:
-
Locate the data on disk using the compression offset map
-
Fetch the data from the SSTable on disk into the chunk cache
-
Row cache
Typical of any database, reads are fastest when the most in-demand data fits into memory. The operating system page cache is best at improving performance, although the row cache can provide some improvement for very read-intensive operations, where read operations are 95% of the load. Row cache is not recommended for write-intensive operations.
If the row cache is enabled, it stores a subset of the partition data stored on disk in the SSTables in memory. The row cache is stored in fully off-heap memory using an implementation that relieves garbage collection pressure in the Java Virtual Machine (JVM). The subset stored in the row cache uses a configurable amount of memory for a specified period of time. When the cache is full, the row cache uses LRU (least-recently-used) eviction to reclaim memory.
The row cache size is configurable, as is the number of rows to store. Configuring the number of rows to be stored is a useful feature, making a "Last 10 Items" query very fast to read. If row cache is enabled, desired partition data is read from the row cache, potentially saving two seeks to disk for the data.
The rows stored in row cache are frequently accessed rows that are merged and saved to the row cache from the SSTables as they are accessed. After storage, the data is available to later queries. The row cache is not write-through.
If a write comes in for the row, the cache for that row is invalidated and is not cached again until the row is read. Similarly, if a partition is updated, the entire partition is removed from the cache. When the desired partition data is not found in the row cache, the bloom filter is checked.
Bloom filter
Each SSTable has an associated Bloom filter, which can establish that an SSTable does not contain certain partition data. A Bloom filter can also determine the likelihood that partition data is stored in an SSTable by narrowing the pool of keys, which increases partition key lookup.
HCD checks the Bloom filter to discover which SSTables are likely to have the requested partition data. If the Bloom filter does not rule out an SSTable, HCD checks the partition index. Not all SSTables identified by the Bloom filter will have data. Because the Bloom filter is a probabilistic function, it can sometimes return false positives.
The Bloom filter is stored in off-heap memory, and grows to approximately 1-2 gigabytes (GB) per billion partitions. In an extreme case, each row can have a partition, so a single machine can easily have billions of these entries. To trade memory for performance, tune the Bloom filter.
Partition index
The partition index maps partition keys to a row index and supports iteration from a partially specified partition position if required. The size of database partitions often varies. The partition index trie data structure uses a unique byte-ordered partition key prefixes to point to:
-
A row index for tables that have wide partitions
-
Directly to the data position in a file for tables that have partitions that only include a few rows or a single row
If a leaf of the trie is reached, then the prefix of the partition key matches some content in the file, but we are not yet sure if it is a full match for the partition key. The leaf node points to a place in the row index or data file. In either case, the first bytes at the specified position contain a serialization of the partition key, which is compared to the mapped key. If it matches, we have found the partition. If not, since the stored prefixes are unique, no data for this partition exists in the SSTable.
Uncompressed data in chunk cache (memory)
The chunk cache buffers data before it is compressed and written to an SSTable. When reading data, uncompressed data is checked first. If the data is compressed and on disk, the process uses the compression offset map to locate the data on disk and uncompress the SSTable into memory. For more information, see Compaction.
Compression offset map
The compression offset map stores pointers to the exact location on disk where the desired partition data will be found. This location is stored in off-heap memory and is accessed by either the partition key cache or the partition index. After the compression offset map identifies the disk location, the desired compressed partition data is fetched from the correct SSTable(s). The query then receives the result set.
|
Within a partition, all rows are not equally expensive to query. The very beginning of the partition (the first rows, clustered by your key definition) is slightly less expensive to query because there is no need to consult the partition-level index. |
The compression offset map grows to 1-3 gigabytes (GB) per terabyte (TB) compressed. The more data is compressed, the greater number of compressed blocks required, and the larger the compression offset table. Compression is enabled by default even though going through the compression offset map consumes CPU resources. Having compression enabled makes the page cache more effective, and typically results in a timely search.
