Helpers
|
This Langflow feature is currently in public preview. Development is ongoing, and the features and functionality are subject to change. Langflow, and the use of such, is subject to the DataStax Preview Terms. |
Helper components provide utility functions to help manage data, tasks, and other components in your flow.
Use a helper component in a flow
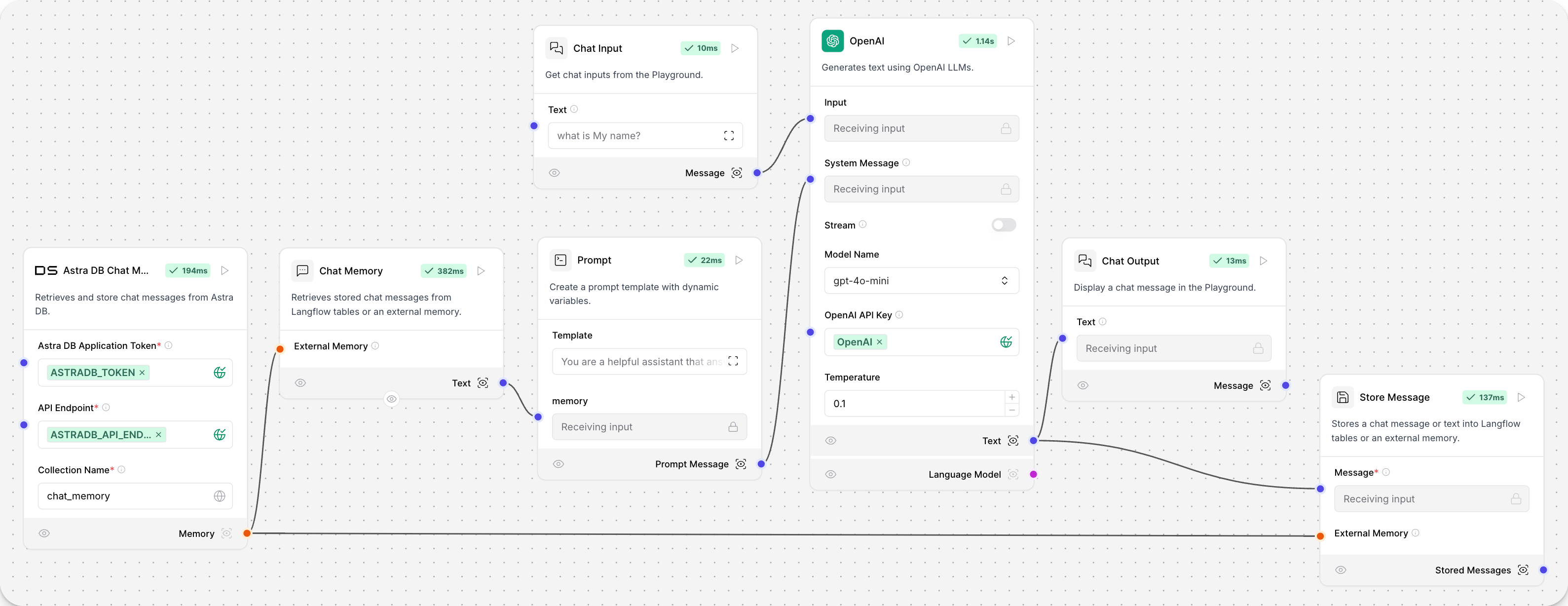
Chat memory in Langflow is stored either in local Langflow tables with LCBufferMemory, or connected to an external database.
The Store Message helper component stores chat memories as Data objects, and the Message History helper component retrieves chat messages as data objects or strings.
This example flow stores and retrieves chat history from an Astra DB Chat Memory component with Store Message and Chat Memory components.
Create list
|
This component is in Legacy, which means it is no longer in active development. Use the Structured output component instead. |
This component takes a list of text inputs and converts each text into a data object. These data objects are then collected into a list, which is returned as the output.
Parameters
| Name | Display Name | Info |
|---|---|---|
texts |
Texts |
Enter one or more texts. This input accepts multiple text entries. |
| Display Name | Name | Info |
|---|---|---|
Data List |
list |
A list of data objects created from the input texts. |
Current date
The Current date component returns the current date and time in a selected timezone. This component provides a flexible way to obtain timezone-specific date and time information within a Langflow pipeline.
Parameters
| Name | Display Name | Info |
|---|---|---|
timezone |
Timezone |
Select the timezone for the current date and time. |
| Name | Display Name | Info |
|---|---|---|
current_date |
Current Date |
The resulting current date and time in the selected timezone. |
Custom component
|
This component is available by clicking New Custom Component in the Components menu. |
Use this component as a template to create your custom component.
Hierarchical Task
|
This component has moved to the Bundles section of the components menu. |
This component creates and manages hierarchical tasks for CrewAI agents in a Playground environment.
For more information, see the CrewAI documentation.
Parameters
| Name | Display Name | Info |
|---|---|---|
task_description |
Description |
Descriptive text detailing task’s purpose and execution. |
expected_output |
Expected Output |
Clear definition of expected task outcome. |
tools |
Tools |
List of tools/resources limited for task execution. Uses the Agent tools by default. |
| Name | Display Name | Info |
|---|---|---|
task_output |
Task |
The built hierarchical task. |
ID generator
This component generates a unique ID.
Parameters
| Name | Display Name | Info |
|---|---|---|
value |
Value |
Unique ID generated. |
Message history
|
This component was named Chat Memory prior to Langflow version 1.1.0. |
This component retrieves and manages chat messages from Langflow tables or an external memory.
Parameters
| Name | Display Name | Info |
|---|---|---|
memory |
External Memory |
Retrieve messages from an external memory. If empty, it uses the Langflow tables. |
sender |
Sender Type |
Filter by sender type. |
sender_name |
Sender Name |
Filter by sender name. |
n_messages |
Number of Messages |
Number of messages to retrieve. |
session_id |
Session ID |
The session ID of the chat. If empty, the current session ID parameter is used. |
order |
Order |
Order of the messages. |
template |
Template |
The template to use for formatting the data. It can contain the keys {text}, {sender} or any other key in the message data. |
| Name | Display Name | Info |
|---|---|---|
messages |
Messages (data object) |
Retrieved messages as data objects. |
messages_text |
Messages (text) |
Retrieved messages formatted as text. |
lc_memory |
Memory |
The created LangChain-compatible memory object. |
Output Parser
|
This component is in Legacy, which means it is no longer in active development as of Langflow version 1.3. Use the Structured output component instead. |
This component transforms the output of a language model into a specified format. It supports CSV format parsing, which converts LLM responses into comma-separated lists using Langchain’s CommaSeparatedListOutputParser.
|
This component only provides formatting instructions and parsing functionality. It does not include a prompt. You’ll need to connect it to a separate Prompt component to create the actual prompt template for the LLM to use. |
Both the Output Parser and Structured Output components format LLM responses, but they have different use cases.
The Output Parser is simpler and focused on converting responses into comma-separated lists. Use this when you just need a list of items, for example ["item1", "item2", "item3"].
The Structured Output is more complex and flexible, and allows you to define custom schemas with multiple fields of different types. Use this when you need to extract structured data with specific fields and types.
To use this component:
-
Create a Prompt component and connect the Output Parser’s
format_instructionsoutput to it. This ensures the LLM knows how to format its response. -
Write your actual prompt text in the Prompt component, including the
{format_instructions}variable. For example, in your Prompt component, the template might look like:{format_instructions} Please list three fruits. -
Connect the
output_parseroutput to your LLM model. -
The output parser converts this into a Python list:
["apple", "banana", "orange"].
Parameters
| Name | Display Name | Info |
|---|---|---|
parser_type |
Parser |
Select the parser type. Currently supports "CSV". |
| Name | Display Name | Info |
|---|---|---|
format_instructions |
Format Instructions |
Pass to a prompt template to include formatting instructions for LLM responses. |
output_parser |
Output Parser |
The constructed output parser that can be used to parse LLM responses. |
Sequential task
|
This component has moved to the Bundles section of the components menu. |
This component creates and manage sequential tasks for CrewAI agents. It builds a SequentialTask object with the provided description, expected output, and agent, allowing for the specification of tools and asynchronous execution.
For more information, see the CrewAI documentation.
Parameters
| Name | Display Name | Info |
|---|---|---|
task_description |
Description |
Descriptive text detailing task’s purpose and execution. |
expected_output |
Expected Output |
Clear definition of expected task outcome. |
tools |
Tools |
List of tools/resources limited for task execution. Uses the Agent tools by default. |
agent |
Agent |
CrewAI Agent that will perform the task. |
task |
Task |
CrewAI Task that will perform the task. |
async_execution |
Async Execution |
Boolean flag indicating asynchronous task execution. |
| Name | Display Name | Info |
|---|---|---|
task_output |
Task |
The built sequential task or list of tasks. |
Message store
This component stores chat messages or text into Langflow tables or an external memory.
It provides flexibility in managing message storage and retrieval within a chat system.
Parameters
| Name | Display Name | Info |
|---|---|---|
message |
Message |
The chat message to be stored. (Required) |
memory |
External Memory |
The external memory to store the message. If empty, it will use the Langflow tables. |
sender |
Sender |
The sender of the message. Can be Machine or User. If empty, the current sender parameter will be used. |
sender_name |
Sender Name |
The name of the sender. Can be AI or User. If empty, the current sender parameter will be used. |
session_id |
Session ID |
The session ID of the chat. If empty, the current session ID parameter will be used. |
| Name | Display Name | Info |
|---|---|---|
stored_messages |
Stored Messages |
The list of stored messages after the current message has been added. |
Structured output
This component transforms LLM responses into structured data formats.
Use the structured output component in a flow
In this example from the Financial Support Parser template, the Structured Output component transforms unstructured financial reports into structured data.
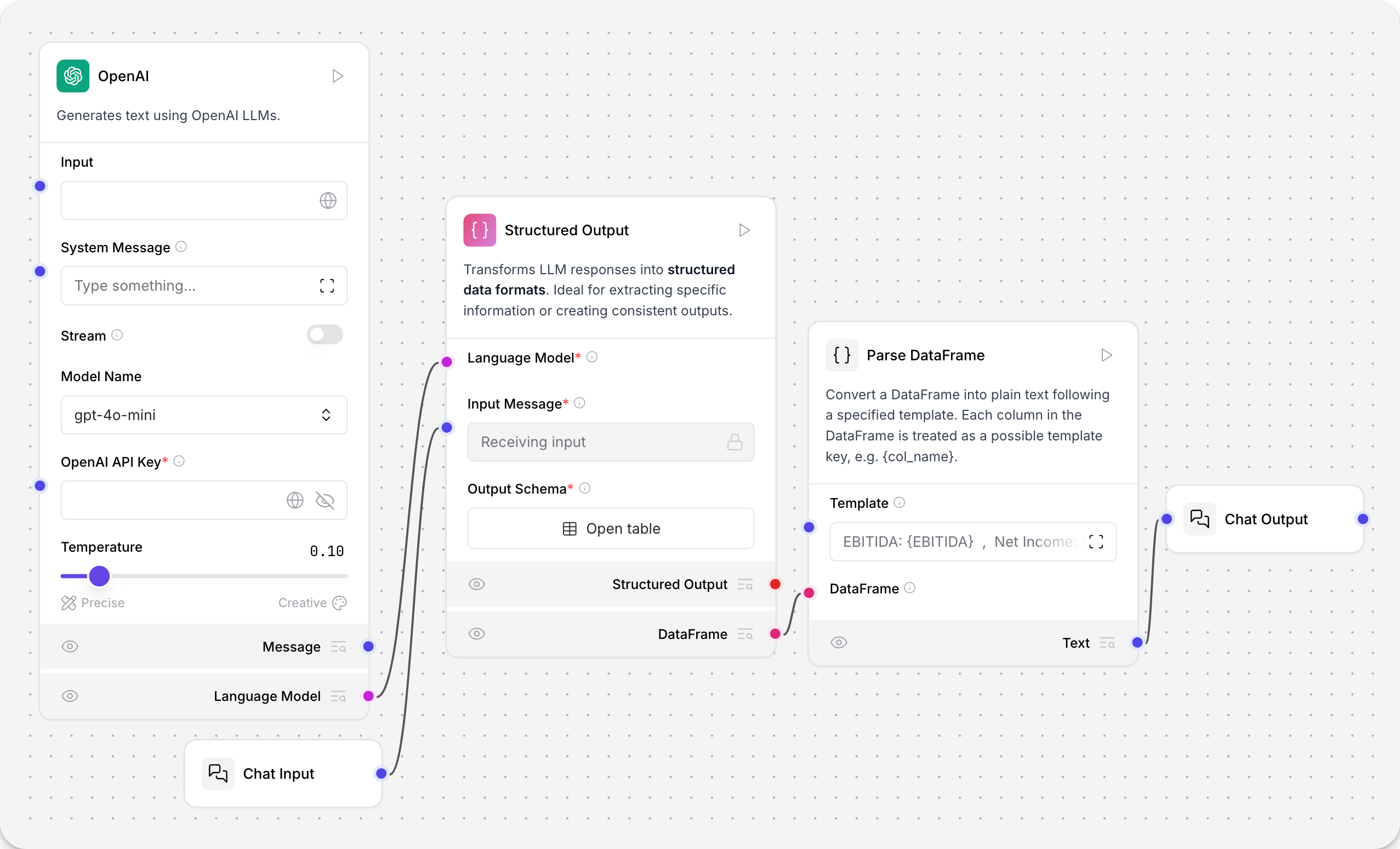
The connected LLM model is prompted by the Structured Output component’s system_prompt parameter to extract structured output from the unstructured text.
In the Structured Output component, click the Open table button to view the output_schema table.
The output_schema parameter defines the structure and data types for the model’s output using a table with the following fields:
-
Name: The name of the output field.
-
Description: The purpose of the output field.
-
Type: The data type of the output field. The available types are
str,int,float,bool,list, ordict. Default:text. -
Multiple: Set to
Trueif you expect multiple values for a single field. For example, a list of features is set totrueto contain multiple values, such as["waterproof", "durable", "lightweight"]. Default:True.
The Parse DataFrame component parses the structured output into a template for orderly presentation in chat output. The template receives the values from the output_schema table with curly braces.
For example, the template EBITDA: {EBITDA} , Net Income: {NET_INCOME} , GROSS_PROFIT: {GROSS_PROFIT} presents the extracted values in the Playground as EBITDA: 900 million , Net Income: 500 million , GROSS_PROFIT: 1.2 billion.
Parameters
| Name | Display Name | Info |
|---|---|---|
llm |
Language Model |
The language model to use to generate the structured output. |
input_value |
Input Message |
The input message to the language model. |
system_prompt |
Format Instructions |
Instructions to the language model for formatting the output. |
schema_name |
Schema Name |
The name for the output data schema. |
output_schema |
Output Schema |
The structure and data types for the model’s output. |
multiple |
Generate Multiple |
[Deprecated] Always set to True. |
| Name | Display Name | Info |
|---|---|---|
structured_output |
Structured Output |
The structured output based on the defined schema. |
structured_output_dataframe |
DataFrame |
The structured output converted to a DataFrame format. |
