Data
|
This Langflow feature is currently in public preview. Development is ongoing, and the features and functionality are subject to change. Langflow, and the use of such, is subject to the DataStax Preview Terms. |
Data components load data from a source into your flow.
They may perform some processing or type checking, like converting raw HTML data into text, or ensuring your loaded file is of an acceptable type.
Use a data component in a flow
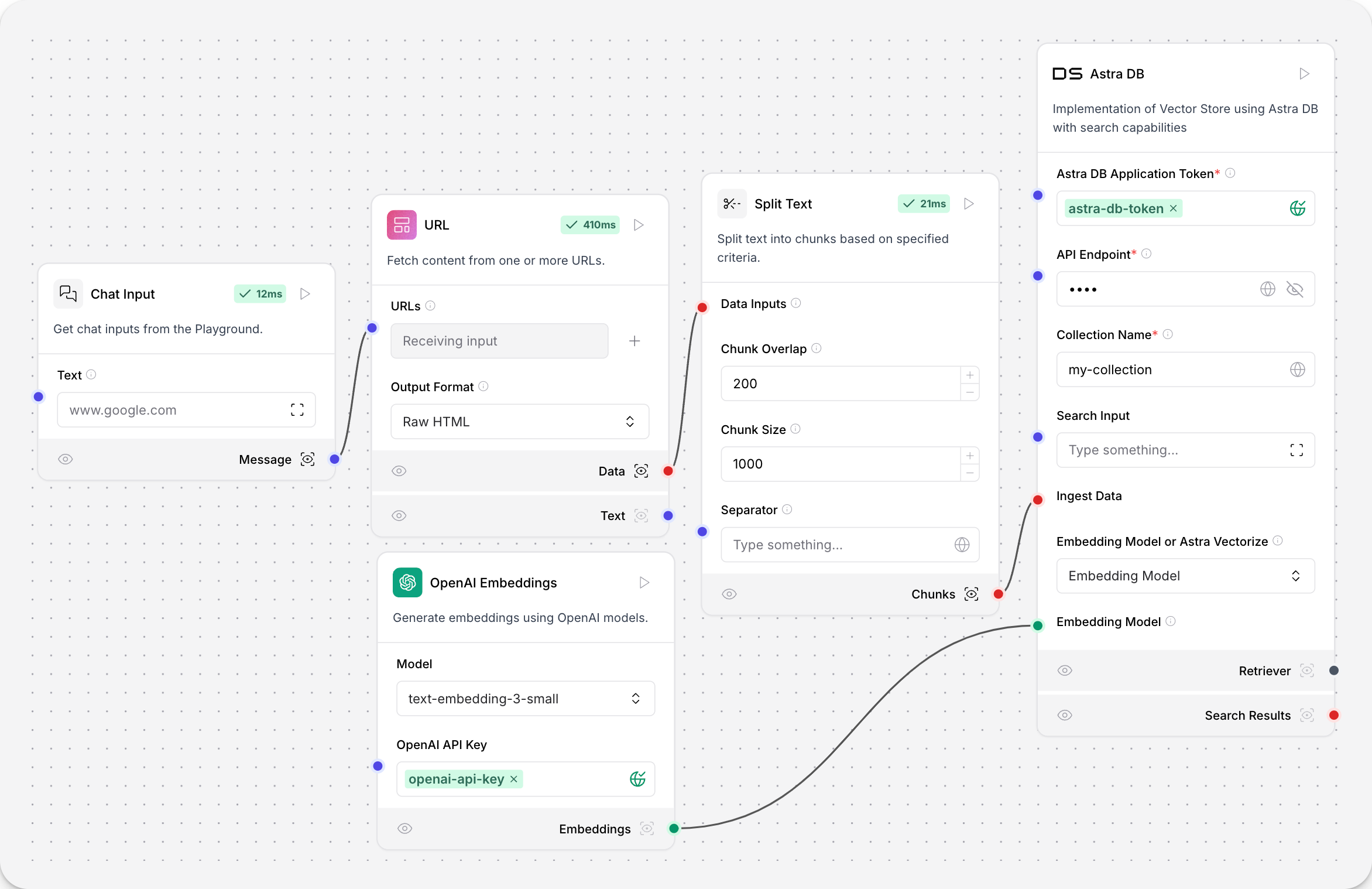
The URL data component loads content from a list of URLs.
In the component’s URLs field, enter a comma-separated list of URLs you want to load. Alternatively, connect a component that outputs the Message type, like the Chat Input component, to supply your URLs with a component.
To output a Data type, in the Output Format dropdown, select Raw HTML.
To output a Message type, in the Output Format dropdown, select Text. This option applies postprocessing with the data_to_text helper function.
In this example of a document ingestion pipeline, the URL component outputs raw HTML to a text splitter, which splits the raw content into chunks for a vector database to ingest.
API Request
This component makes HTTP requests using URLs or cURL commands.
Parameters
| Name | Display Name | Info |
|---|---|---|
urls |
URLs |
Enter one or more URLs, separated by commas. |
curl |
cURL |
Paste a curl command to populate the fields. This completes the dictionary fields for headers and body. |
method |
Method |
The HTTP method to use. |
use_curl |
Use cURL |
Enable cURL mode to populate fields from a cURL command. |
query_params |
Query Parameters |
The query parameters to append to the URL. |
body |
Body |
The body sent with the request as a dictionary (for POST, PATCH, PUT). |
headers |
Headers |
The headers sent with the request as a dictionary. |
timeout |
Timeout |
The timeout specified for the request. |
follow_redirects |
Follow Redirects |
Whether to follow http redirects. |
include_httpx_metadata |
Include HTTPx Metadata |
Include properties such as headers, status_code, response_headers, and redirection_history in the output. |
| Name | Display Name | Info |
|---|---|---|
data |
Data |
The result of the API requests. |
Directory
This component recursively loads files from a directory, with options for file types, depth, and concurrency.
Parameters
| Name | Display Name | Info |
|---|---|---|
path |
Path |
The path to the directory to load files from. |
types |
Types |
The file types to load. Leave empty to load all types. |
depth |
Depth |
Controls how many directory levels deep to search for files. 0 means only search current directory, 1 means one level down, and so on. |
max_concurrency |
Max Concurrency |
Maximum concurrency for loading files. The default is 2 files. |
load_hidden |
Load Hidden |
If true, hidden files are loaded. |
recursive |
Recursive |
If true, subdirectories are included in the search. |
silent_errors |
Silent Errors |
When |
use_multithreading |
Use Multithreading |
When |
| Name | Display Name | Info |
|---|---|---|
data |
Data |
Loaded file data from the directory. Type: |
File
This component loads and parses text files of various supported formats, converting the content into a Data object. It supports multiple file types and provides an option for silent error handling.
The maximum supported file size is 100 MB.
Parameters
| Name | Display Name | Info |
|---|---|---|
path |
Path |
File path to load. |
silent_errors |
Silent Errors |
If true, errors will not raise an exception |
| Name | Display Name | Info |
|---|---|---|
data |
Data |
Parsed content of the file as a Data object |
Supported file extensions
The following file types are supported for processing:
Supported file extensions
| Document formats |
|
| Data formats |
|
| Markup Languages |
|
| Programming Languages |
|
| Image Formats |
|
Gmail loader
Google components are available in the Components menu under Bundles.
This component loads emails from Gmail using provided credentials and filters. For more information about creating a service account JSON, see Service Account JSON.
Parameters
| Input | Type | Description |
|---|---|---|
json_string |
SecretStrInput |
JSON string containing OAuth 2.0 access token information for service account access |
label_ids |
MessageTextInput |
Comma-separated list of label IDs to filter emails |
max_results |
MessageTextInput |
Maximum number of emails to load |
| Output | Type | Description |
|---|---|---|
data |
Data |
Loaded email data |
Google Drive loader
Google components are available in the Components menu under Bundles.
This component loads documents from Google Drive using provided credentials and a single document ID. For more information about creating a service account JSON, see Service Account JSON.
Parameters
| Input | Type | Description |
|---|---|---|
json_string |
SecretStrInput |
JSON string containing OAuth 2.0 access token information for service account access |
document_id |
MessageTextInput |
Single Google Drive document ID |
| Output | Type | Description |
|---|---|---|
docs |
Data |
Loaded document data |
Google Drive search
Google components are available in the Components menu under Bundles.
This component searches Google Drive files using provided credentials and query parameters. For more information about creating a service account JSON, see Service Account JSON.
Parameters
| Input | Type | Description |
|---|---|---|
token_string |
SecretStrInput |
JSON string containing OAuth 2.0 access token information for service account access |
query_item |
DropdownInput |
The field to query |
valid_operator |
DropdownInput |
Operator to use in the query |
search_term |
MessageTextInput |
The value to search for in the specified query item |
query_string |
MessageTextInput |
The query string used for searching (can be edited manually) |
| Output | Type | Description |
|---|---|---|
doc_urls |
List[str] |
URLs of the found documents |
doc_ids |
List[str] |
IDs of the found documents |
doc_titles |
List[str] |
Titles of the found documents |
Data |
Data |
Document titles and URLs in a structured format |
SQL Query
This component executes SQL queries on a specified database.
Parameters
| Name | Display Name | Info |
|---|---|---|
query |
Query |
The SQL query to execute. |
database_url |
Database URL |
The URL of the database. |
include_columns |
Include Columns |
Include columns in the result. |
passthrough |
Passthrough |
If an error occurs, return the query instead of raising an exception. |
add_error |
Add Error |
Add the error to the result. |
| Name | Display Name | Info |
|---|---|---|
result |
Result |
The result of the SQL query execution. |
URL
The URLComponent fetches content from one or more URLs, processes the content, and returns it in various formats. It supports output in plain text, raw HTML, or JSON, with options for cleaning and separating multiple outputs.
Parameters
| Name | Display Name | Info |
|---|---|---|
urls |
URLs |
Enter one or more URLs. URLs are automatically validated and cleaned. |
format |
Output Format |
Output Format. Use Text to extract text from the HTML, Raw HTML for the raw HTML content, or JSON to extract JSON from the HTML. |
separator |
Separator |
Specify the separator to use between multiple outputs. The default separator for Text is |
clean_extra_whitespace |
Clean Extra Whitespace |
Controls whether to clean excessive blank lines in the text output. This option only applies to |
| Name | Display Name | Info |
|---|---|---|
data |
Data |
List of data objects containing fetched content and metadata. |
text |
Text |
Fetched content as formatted text, with applied separators and cleaning. |
dataframe |
DataFrame |
Content formatted as a data object. |
Webhook
This component defines a webhook trigger that runs a flow when it receives an HTTP POST request.
If the input is not valid JSON, the component wraps it in a payload object so that it can be processed and still trigger the flow. The component does not require an API key.
When a Webhook component is added to the workspace, the Endpoint field in the Webhook component tab contains an endpoint for triggering the webhook component.
To use the webhook component, copy the endpoint URL and paste it into a POST request. The request must include your Astra DB application token in the header.
curl -X POST \
"http://127.0.0.1:7860/api/v1/webhook/**YOUR_FLOW_ID**" \
-H 'Content-Type: application/json'\
-H 'Authorization: Bearer AstraCS:...' \
-d '{"any": "data"}'To test the webhook component:
-
Add a Webhook component to the flow.
-
Connect the Webhook component’s Data output to the Data input of a Parser component.
-
Connect the Parser component’s Parsed Text output to the Text input of a Chat output component.
-
To send a POST request, copy the URL from the Endpoint field and paste it into a POST request. The request must include your Astra DB application token in the header.
-
Send the POST request.
-
Open the Playground. Your JSON data is posted to the Chat output component, which indicates that the webhook component is correctly triggering the flow.
Parameters
| Name | Type | Description |
|---|---|---|
data |
Payload |
Receives a payload through HTTP POST requests. |
curl |
cURL |
|
The cURL command template for making requests to this webhook. |
endpoint |
|
Endpoint |
The endpoint URL where the webhook component receives requests. |
| Name | Type | Description |
|---|---|---|
output_data |
Data |
Outputs processed data from the webhook input, and returns an empty data object if no input is provided.
If the input is not valid JSON, the component wraps it in a |
