Vector Stores
|
This Langflow feature is currently in public preview. Development is ongoing, and the features and functionality are subject to change. Langflow, and the use of such, is subject to the DataStax Preview Terms. |
Vector databases store vector data, which backs AI workloads like chatbots and Retrieval Augmented Generation.
Vector database components establish connections to existing vector databases or create in-memory vector stores for storing and retrieving vector data.
Vector database components are distinct from memory components, which are built specifically for storing and retrieving chat messages from external databases.
Use a vector store component in a flow
Vector databases can be populated from within Langflow with document ingestion pipelines, like the following.
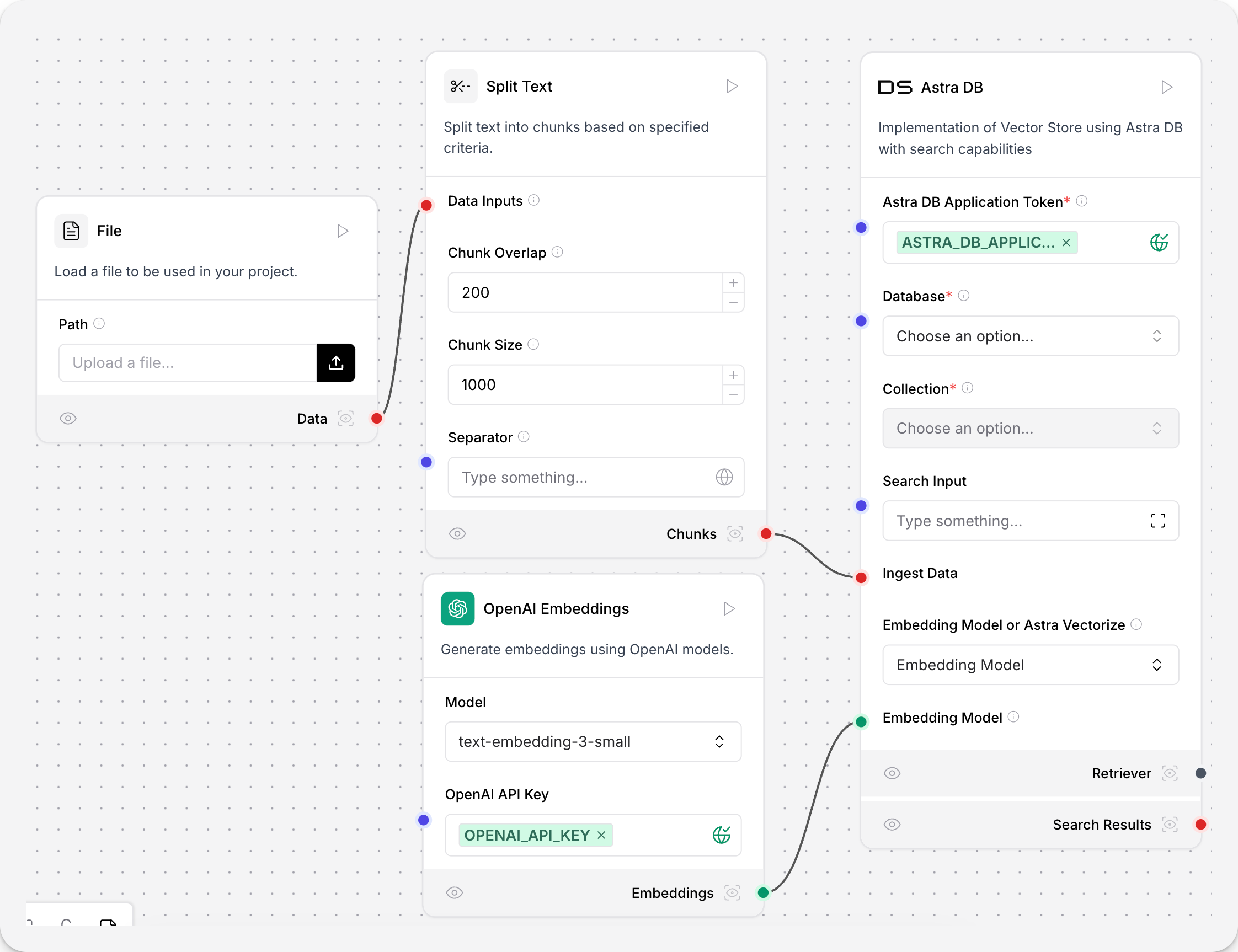
This example uses the Astra DB vector store component. Your vector store component’s parameters and authentication may be different, but the document ingestion workflow is the same. A document is loaded from a local machine and chunked. The Astra DB vector store generates embeddings with the connected model component, and stores them in the connected Astra DB database.
This vector data can then be retrieved for workloads like Retrieval Augmented Generation.
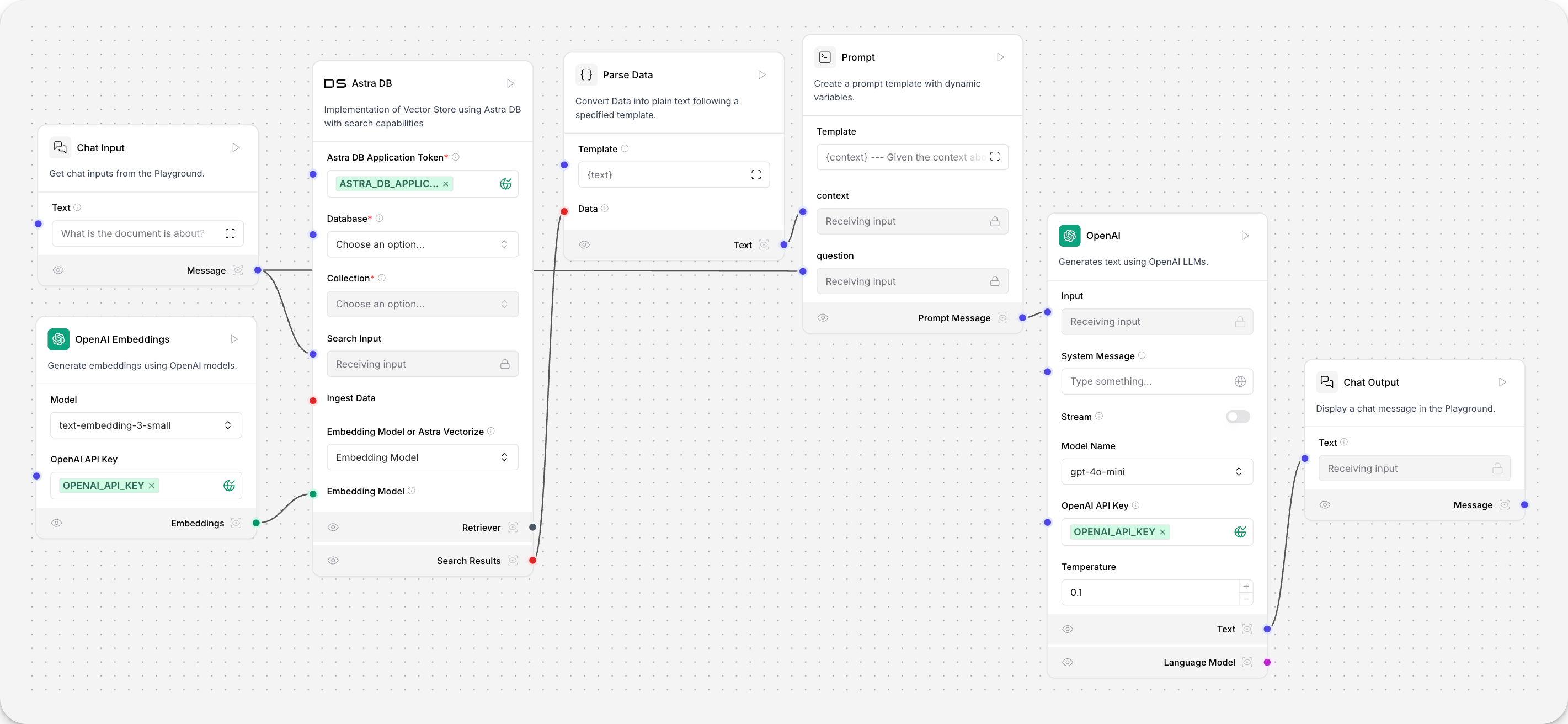
The user’s chat input is embedded and compared to the vectors embedded during document ingestion for a similarity search. The results are output from the vector database component as a Data object, and parsed into text. This text fills the {context} variable in the Prompt component, which informs the Open AI model component’s responses.
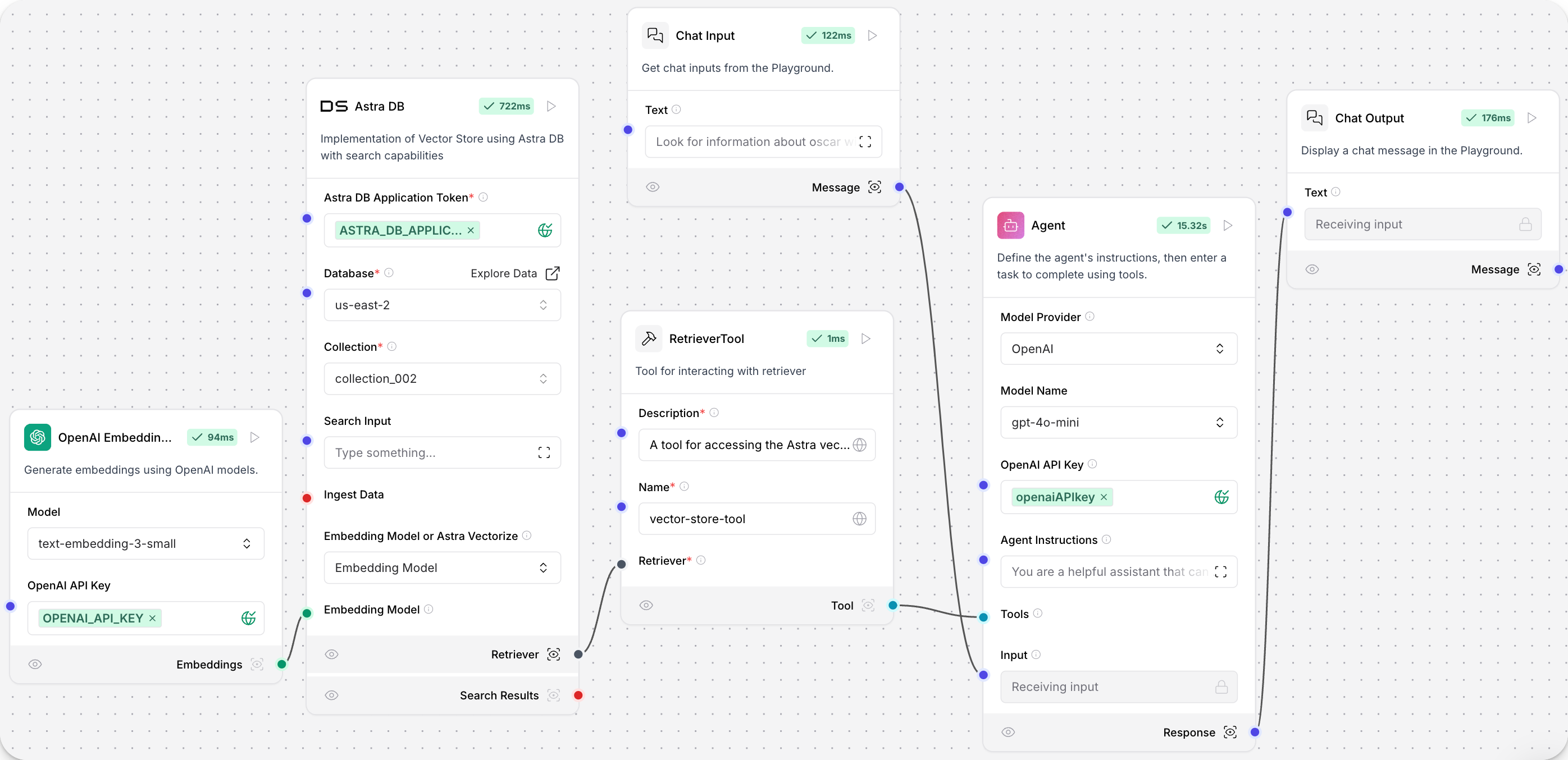
Alternatively, connect the vector database component’s Retriever port to a retriever tool, and then to an agent component. This enables the agent to use your vector database as a tool and make decisions based on the available data.
Astra DB Vector Store
This component implements a Vector Store using Astra DB Serverless with search capabilities.
Parameters
| Name | Display Name | Info |
|---|---|---|
token |
Astra DB Application Token |
The authentication token for accessing Astra DB. |
environment |
Environment |
The environment for the Astra DB API Endpoint. For example, |
database_name |
Database |
The database name for the Astra DB instance. |
api_endpoint |
Astra DB API Endpoint |
The API endpoint for the Astra DB instance. This supersedes the database selection. |
collection_name |
Collection |
The name of the collection within Astra DB where the vectors are stored. |
keyspace |
Keyspace |
An optional keyspace within Astra DB to use for the collection. |
embedding_choice |
Embedding Model or Astra Vectorize |
Choose an embedding model or use Astra vectorize. |
embedding_model |
Embedding Model |
Specify the embedding model. Not required for Astra vectorize collections. |
number_of_results |
Number of Search Results |
The number of search results to return (default: |
search_type |
Search Type |
The search type to use. The options are |
search_score_threshold |
Search Score Threshold |
The minimum similarity score threshold for search results when using the |
advanced_search_filter |
Search Metadata Filter |
An optional dictionary of filters to apply to the search query. |
autodetect_collection |
Autodetect Collection |
A boolean flag to determine whether to autodetect the collection. |
content_field |
Content Field |
A field to use as the text content field for the vector store. |
deletion_field |
Deletion Based On Field |
When provided, documents in the target collection with metadata field values matching the input metadata field value are deleted before new data is loaded. |
ignore_invalid_documents |
Ignore Invalid Documents |
A boolean flag to determine whether to ignore invalid documents at runtime. |
astradb_vectorstore_kwargs |
AstraDBVectorStore Parameters |
An optional dictionary of additional parameters for the AstraDBVectorStore. |
| Name | Display Name | Info |
|---|---|---|
vector_store |
Vector Store |
Built Astra DB Serverless vector store |
search_results |
Search Results |
Results of the similarity search as a list of Data objects |
Component code
astradb.py
404: Not FoundGenerate embeddings
The Astra DB Vector Store component offers two methods for generating embeddings.
-
Embedding Model: Use your own embedding model by connecting an embedding model component in Langflow.
-
Astra Vectorize: Use Astra DB’s built-in embedding generation service. When creating a new collection, choose the embeddings provider and models, including NVIDIA’s
NV-Embed-QAmodel hosted by DataStax.
|
The embedding model selection is made when creating a new collection and cannot be changed later. |
For an example of using the Astra DB Vector Store component with an embedding model, see the Vector Store RAG starter project.
For more information, see the Astra DB Serverless documentation.
Astra DB graph vector store
This component implements a Vector Store using Astra DB Serverless with graph capabilities.
Parameters
| Name | Type | Description |
|---|---|---|
token |
SecretString |
Authentication token for accessing Astra DB. |
api_endpoint |
SecretString |
API endpoint URL for the Astra DB service. |
collection_name |
String |
The name of the collection within Astra DB where vectors will be stored. |
embedding |
Handle |
Embedding model to use. |
search_input |
Multiline |
Input text for searching documents. |
ingest_data |
Data |
Data to be ingested into the vector store. |
| Name | Type | Description |
|---|---|---|
vector_store |
VectorStore |
An instance of AstraDBGraphVectorStore for storing and searching vectors. |
Component code
astradb_graph.py
404: Not FoundCassandra
This component creates a Cassandra Vector Store with search capabilities. For more information, see the Cassandra documentation.
Parameters
| Name | Type | Description |
|---|---|---|
database_ref |
String |
Contact points for the database or AstraDB database ID |
username |
String |
Username for the database (leave empty for AstraDB) |
token |
SecretString |
User password for the database or AstraDB token |
keyspace |
String |
Table Keyspace or AstraDB namespace |
table_name |
String |
Name of the table or AstraDB collection |
ttl_seconds |
Integer |
Time-to-live for added texts |
batch_size |
Integer |
Number of data to process in a single batch |
setup_mode |
String |
Configuration mode for setting up the Cassandra table |
cluster_kwargs |
Dict |
Additional keyword arguments for the Cassandra cluster |
search_query |
String |
Query for similarity search |
ingest_data |
Data |
Data to be ingested into the vector store |
embedding |
Embeddings |
Embedding function to use |
number_of_results |
Integer |
Number of results to return in search |
search_type |
String |
Type of search to perform |
search_score_threshold |
Float |
Minimum similarity score for search results |
search_filter |
Dict |
Metadata filters for search query |
body_search |
String |
Document textual search terms |
enable_body_search |
Boolean |
Flag to enable body search |
| Name | Type | Description |
|---|---|---|
vector_store |
Cassandra |
Cassandra vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
cassandra.py
404: Not FoundCassandra Graph Vector Store
This component implements a Cassandra Graph Vector Store with search capabilities.
Parameters
| Name | Display Name | Info |
|---|---|---|
database_ref |
Contact Points / Astra Database ID |
Contact points for the database or AstraDB database ID (required). |
username |
Username |
Username for the database (leave empty for AstraDB). |
token |
Password / AstraDB Token |
User password for the database or AstraDB token (required). |
keyspace |
Keyspace |
Table Keyspace or AstraDB namespace (required). |
table_name |
Table Name |
The name of the table or AstraDB collection where vectors will be stored (required). |
setup_mode |
Setup Mode |
Configuration mode for setting up the Cassandra table (options: "Sync", "Off", default: "Sync"). |
cluster_kwargs |
Cluster arguments |
Optional dictionary of additional keyword arguments for the Cassandra cluster. |
search_query |
Search Query |
Query string for similarity search. |
ingest_data |
Ingest Data |
Data to be ingested into the vector store (list of Data objects). |
embedding |
Embedding |
Embedding model to use. |
number_of_results |
Number of Results |
Number of results to return in similarity search (default: 4). |
search_type |
Search Type |
Search type to use (options: "Traversal", "MMR traversal", "Similarity", "Similarity with score threshold", "MMR (Max Marginal Relevance)", default: "Traversal"). |
depth |
Depth of traversal |
The maximum depth of edges to traverse (for "Traversal" or "MMR traversal" search types, default: 1). |
search_score_threshold |
Search Score Threshold |
Minimum similarity score threshold for search results (for "Similarity with score threshold" search type). |
search_filter |
Search Metadata Filter |
Optional dictionary of filters to apply to the search query. |
| Name | Display Name | Info |
|---|---|---|
vector_store |
Vector Store |
Built Cassandra Graph vector store. |
search_results |
Search Results |
Results of the similarity search as a list of Data objects. |
Component code
cassandra_graph.py
404: Not FoundChroma DB
This component creates a Chroma Vector Store with search capabilities. For more information, see the Chroma documentation.
Parameters
| Name | Type | Description |
|---|---|---|
collection_name |
String |
The name of the Chroma collection. Default: "langflow". |
persist_directory |
String |
The directory to persist the Chroma database. |
search_query |
String |
The query to search for in the vector store. |
ingest_data |
Data |
The data to ingest into the vector store (list of Data objects). |
embedding |
Embeddings |
The embedding function to use for the vector store. |
chroma_server_cors_allow_origins |
String |
CORS allow origins for the Chroma server. |
chroma_server_host |
String |
Host for the Chroma server. |
chroma_server_http_port |
Integer |
HTTP port for the Chroma server. |
chroma_server_grpc_port |
Integer |
gRPC port for the Chroma server. |
chroma_server_ssl_enabled |
Boolean |
Enable SSL for the Chroma server. |
allow_duplicates |
Boolean |
Allow duplicate documents in the vector store. |
search_type |
String |
Type of search to perform: "Similarity" or "MMR". |
number_of_results |
Integer |
Number of results to return from the search. Default: 10. |
limit |
Integer |
Limit the number of records to compare when Allow Duplicates is False. |
Component code
chroma.py
404: Not FoundClickhouse
This component implements a Clickhouse Vector Store with search capabilities using the LangChain framework.
Parameters
| Name | Display Name | Info |
|---|---|---|
host |
hostname |
Clickhouse server hostname (required, default: "localhost") |
port |
port |
Clickhouse server port (required, default: 8123) |
database |
database |
Clickhouse database name (required) |
table |
Table name |
Clickhouse table name (required) |
username |
The ClickHouse user name. |
Username for authentication (required) |
password |
The password for username. |
Password for authentication (required) |
index_type |
index_type |
Type of the index (options: "annoy", "vector_similarity", default: "annoy") |
metric |
metric |
Metric to compute distance (options: "angular", "euclidean", "manhattan", "hamming", "dot", default: "angular") |
secure |
Use https/TLS |
Overrides inferred values from the interface or port arguments (default: false) |
index_param |
Param of the index |
Index parameters (default: "'L2Distance',100") |
index_query_params |
index query params |
Additional index query parameters |
search_query |
Search Query |
Query string for similarity search |
ingest_data |
Ingest Data |
Data to be ingested into the vector store |
embedding |
Embedding |
Embedding model to use |
number_of_results |
Number of Results |
Number of results to return in similarity search (default: 4) |
score_threshold |
Score threshold |
Threshold for similarity scores |
| Name | Display Name | Info |
|---|---|---|
vector_store |
Vector Store |
Built Clickhouse vector store |
search_results |
Search Results |
Results of the similarity search as a list of Data objects |
Component code
clickhouse.py
404: Not FoundCouchbase
This component creates a Couchbase Vector Store with search capabilities. For more information, see the Couchbase documentation.
Parameters
| Name | Type | Description |
|---|---|---|
couchbase_connection_string |
SecretString |
Couchbase Cluster connection string (required). |
couchbase_username |
String |
Couchbase username (required). |
couchbase_password |
SecretString |
Couchbase password (required). |
bucket_name |
String |
Name of the Couchbase bucket (required). |
scope_name |
String |
Name of the Couchbase scope (required). |
collection_name |
String |
Name of the Couchbase collection (required). |
index_name |
String |
Name of the Couchbase index (required). |
search_query |
String |
The query to search for in the vector store. |
ingest_data |
Data |
The data to ingest into the vector store (list of Data objects). |
embedding |
Embeddings |
The embedding function to use for the vector store. |
number_of_results |
Integer |
Number of results to return from the search. Default: 4 (advanced). |
| Name | Type | Description |
|---|---|---|
vector_store |
CouchbaseVectorStore |
A Couchbase vector store instance configured with the specified parameters. |
Component code
couchbase.py
404: Not FoundElasticsearch
This component creates an Elasticsearch Vector Store with search capabilities. For more information, see the Elasticsearch vector store documentation.
Parameters
| Name | Type | Description |
|---|---|---|
elasticsearch_url |
String |
URL for self-managed Elasticsearch deployments, such as http://localhost:9200. |
cloud_id |
SecretString |
Elastic Cloud ID for cloud deployments. |
index_name |
String |
The index name where vectors will be stored in Elasticsearch cluster. |
search_input |
Multiline |
Search query for retrieving documents. |
username |
String |
Elasticsearch username for authentication. |
password |
SecretString |
Elasticsearch password for authentication. |
ingest_data |
Data |
Data to be ingested into the vector store. |
embedding |
Handle |
Embedding model to use. |
search_type |
Dropdown |
Type of search to perform (similarity or mmr). |
number_of_results |
Integer |
Number of results to return. |
search_score_threshold |
Float |
Minimum similarity score threshold for search results. |
api_key |
SecretString |
API Key for Elastic Cloud authentication. |
| Name | Type | Description |
|---|---|---|
vector_store |
VectorStore |
An instance of ElasticsearchStore for storing and searching vectors. |
Component code
elasticsearch.py
404: Not FoundFAISS
This component creates a FAISS Vector Store with search capabilities.
For more information, see the FAISS documentation.
Parameters
| Name | Type | Description |
|---|---|---|
index_name |
String |
The name of the FAISS index. Default: "langflow_index". |
persist_directory |
String |
Path to save the FAISS index. It will be relative to where Langflow is running. |
search_query |
String |
The query to search for in the vector store. |
ingest_data |
Data |
The data to ingest into the vector store (list of Data objects or documents). |
allow_dangerous_deserialization |
Boolean |
Set to True to allow loading pickle files from untrusted sources. Default: True (advanced). |
embedding |
Embeddings |
The embedding function to use for the vector store. |
number_of_results |
Integer |
Number of results to return from the search. Default: 4 (advanced). |
| Name | Type | Description |
|---|---|---|
vector_store |
FAISS |
A FAISS vector store instance configured with the specified parameters. |
Component code
faiss.py
404: Not FoundGraph RAG
This component performs Graph RAG (Retrieval Augmented Generation) traversal in a vector store, enabling graph-based document retrieval. For more information, see the Graph RAG documentation.
For an example flow, see the Graph RAG template.
Parameters
| Name | Display Name | Info |
|---|---|---|
embedding_model |
Embedding Model |
Specify the embedding model. This is not required for collections embedded with Astra vectorize. |
vector_store |
Vector Store Connection |
Connection to the vector store. |
edge_definition |
Edge Definition |
Edge definition for the graph traversal. For more information, see the GraphRAG documentation. |
strategy |
Traversal Strategies |
The strategy to use for graph traversal. Strategy options are dynamically loaded from available strategies. |
search_query |
Search Query |
The query to search for in the vector store. |
graphrag_strategy_kwargs |
Strategy Parameters |
Optional dictionary of additional parameters for the retrieval strategy. For more information, see the strategy documentation. |
| Name | Type | Description |
|---|---|---|
search_results |
List[Data] |
Results of the graph-based document retrieval as a list of data objects. |
Component code
graph_rag.py
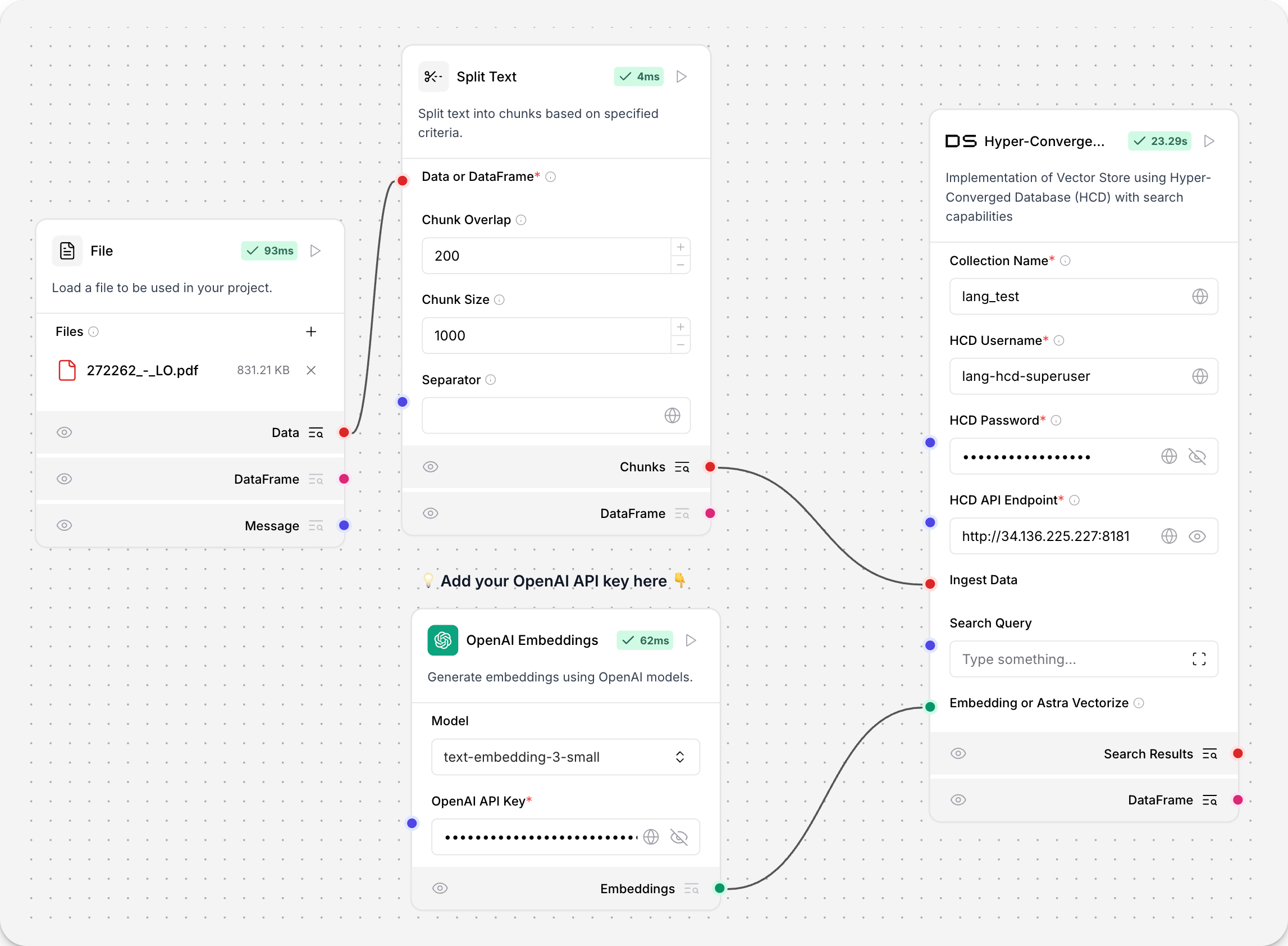
404: Not FoundHyper-Converged Database (HCD) Vector Store
This component implements a Vector Store using Hyper-Converged Database (HCD).
To use the HCD vector store, add your deployment’s collection name, username, password, and HCD Data API endpoint.
The endpoint must be formatted like http[s]://DOMAIN_NAME or IP_ADDRESS[:port], for example, http://192.0.2.250:8181.
Replace DOMAIN_NAME or IP_ADDRESS with the domain name or IP address of your HCD Data API connection.
To use the HCD vector store for embeddings ingestion, connect it to an embeddings model and a file loader:
Parameters
| Name | Display Name | Info |
|---|---|---|
collection_name |
Collection Name |
The name of the collection within HCD where the vectors will be stored (required) |
username |
HCD Username |
Authentication username for accessing HCD (default: "hcd-superuser", required) |
password |
HCD Password |
Authentication password for accessing HCD (required) |
api_endpoint |
HCD API Endpoint |
API endpoint URL for the HCD service (required) |
search_input |
Search Input |
Query string for similarity search |
ingest_data |
Ingest Data |
Data to be ingested into the vector store |
namespace |
Namespace |
Optional namespace within HCD to use for the collection (default: "default_namespace") |
ca_certificate |
CA Certificate |
Optional CA certificate for TLS connections to HCD |
metric |
Metric |
Optional distance metric for vector comparisons (options: "cosine", "dot_product", "euclidean") |
batch_size |
Batch Size |
Optional number of data to process in a single batch |
bulk_insert_batch_concurrency |
Bulk Insert Batch Concurrency |
Optional concurrency level for bulk insert operations |
bulk_insert_overwrite_concurrency |
Bulk Insert Overwrite Concurrency |
Optional concurrency level for bulk insert operations that overwrite existing data |
bulk_delete_concurrency |
Bulk Delete Concurrency |
Optional concurrency level for bulk delete operations |
setup_mode |
Setup Mode |
Configuration mode for setting up the vector store (options: "Sync", "Async", "Off", default: "Sync") |
pre_delete_collection |
Pre Delete Collection |
Boolean flag to determine whether to delete the collection before creating a new one |
metadata_indexing_include |
Metadata Indexing Include |
Optional list of metadata fields to include in the indexing |
embedding |
Embedding or Astra Vectorize |
Allows either an embedding model or an Astra Vectorize configuration |
metadata_indexing_exclude |
Metadata Indexing Exclude |
Optional list of metadata fields to exclude from the indexing |
collection_indexing_policy |
Collection Indexing Policy |
Optional dictionary defining the indexing policy for the collection |
number_of_results |
Number of Results |
Number of results to return in similarity search (default: 4) |
search_type |
Search Type |
Search type to use (options: "Similarity", "Similarity with score threshold", "MMR (Max Marginal Relevance)", default: "Similarity") |
search_score_threshold |
Search Score Threshold |
Minimum similarity score threshold for search results (default: 0) |
search_filter |
Search Metadata Filter |
Optional dictionary of filters to apply to the search query |
| Name | Display Name | Info |
|---|---|---|
vector_store |
Vector Store |
Built HCD vector store instance |
search_results |
Search Results |
Results of similarity search as a list of Data objects |
Component code
hcd.py
404: Not FoundLocal DB
This component is a local Vector Store (Chroma) with search capabilities.
Parameters
| Name | Display Name | Info |
|---|---|---|
mode |
Mode |
Select the operation mode. Options: ["Ingest", "Retrieve"]. Type: TabInput |
collection_name |
Collection Name |
Name of the collection. Default: "langflow". Type: MessageTextInput |
persist_directory |
Persist Directory |
Custom base directory to save the vector store. Collections are stored under '{directory}/vector_stores/{collection_name}'. Uses system’s cache folder if not specified. Type: MessageTextInput |
existing_collections |
Existing Collections |
Select a previously created collection to search through its stored data. Type: DropdownInput |
embedding |
Embedding |
Embedding model to use. Type: HandleInput (Embeddings) |
allow_duplicates |
Allow Duplicates |
If false, will not add documents that are already in the Vector Store. Type: BoolInput |
search_type |
Search Type |
Type of search to perform. Options: ["Similarity", "MMR"]. Default: "Similarity". Type: DropdownInput |
ingest_data |
Ingest Data |
Data to store. It will be embedded and indexed for semantic search. Type: HandleInput (Data, DataFrame) |
search_query |
Search Query |
Enter text to search for similar content in the selected collection. Type: MultilineInput |
number_of_results |
Number of Results |
Number of results to return. Default: 10. Type: IntInput |
limit |
Limit |
Limit the number of records to compare when Allow Duplicates is False. Type: IntInput |
| Name | Display Name | Info |
|---|---|---|
dataframe |
DataFrame |
The results as a DataFrame. Method: |
Component code
local_db.py
404: Not FoundMilvus
This component creates a Milvus Vector Store with search capabilities.
For more information, see the Milvus documentation.
Parameters
| Name | Type | Description |
|---|---|---|
collection_name |
String |
Name of the Milvus collection |
collection_description |
String |
Description of the Milvus collection |
uri |
String |
Connection URI for Milvus |
password |
SecretString |
Connection password (if required) |
connection_args |
Dict |
Additional connection arguments |
primary_field |
String |
Name of the primary field |
text_field |
String |
Name of the text field |
vector_field |
String |
Name of the vector field |
consistency_level |
String |
Consistency level for operations |
index_params |
Dict |
Parameters for indexing |
search_params |
Dict |
Parameters for searching |
drop_old |
Boolean |
Whether to drop old collection |
timeout |
Float |
Timeout for operations |
search_query |
String |
Query for similarity search |
ingest_data |
Data |
Data to be ingested into the vector store |
embedding |
Embeddings |
Embedding function to use |
number_of_results |
Integer |
Number of results to return in search |
| Name | Type | Description |
|---|---|---|
vector_store |
Milvus |
Milvus vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
milvus.py
404: Not FoundMongoDB Atlas
This component creates a MongoDB Atlas Vector Store with search capabilities. For more information, see the MongoDB Atlas documentation.
Parameters
| Name | Type | Description |
|---|---|---|
mongodb_atlas_cluster_uri |
SecretString |
MongoDB Atlas Cluster URI |
db_name |
String |
Database name |
collection_name |
String |
Collection name |
index_name |
String |
Index name |
search_query |
String |
Query for similarity search |
ingest_data |
Data |
Data to be ingested into the vector store |
embedding |
Embeddings |
Embedding function to use |
number_of_results |
Integer |
Number of results to return in search |
| Name | Type | Description |
|---|---|---|
vector_store |
MongoDBAtlasVectorSearch |
MongoDB Atlas vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
mongodb_atlas.py
404: Not FoundOpensearch
This component creates an OpenSearch Vector Store with search capabilities. For more information, see the Opensearch vector store documentation.
Parameters
| Name | Type | Description |
|---|---|---|
opensearch_url |
String |
URL for OpenSearch cluster, for example https://192.168.1.1:9200. |
index_name |
String |
The index name where the vectors will be stored in OpenSearch cluster. |
search_input |
Multiline |
Enter a search query. Leave empty to retrieve all documents. |
ingest_data |
Data |
Data to be ingested into the vector store. |
embedding |
Handle |
Embedding model to use. |
search_type |
Dropdown |
Search type to use (similarity, similarity_score_threshold, or mmr). |
number_of_results |
Integer |
Number of results to return. |
search_score_threshold |
Float |
Minimum similarity score threshold for search results. |
username |
String |
Username for OpenSearch authentication. |
password |
SecretString |
Password for OpenSearch authentication. |
use_ssl |
Boolean |
Whether to use SSL for connection. |
verify_certs |
Boolean |
Whether to verify SSL certificates. |
hybrid_search_query |
Multiline |
Custom hybrid search query in JSON format. |
| Name | Type | Description |
|---|---|---|
vector_store |
VectorStore |
An instance of OpenSearchVectorSearch for storing and searching vectors. |
Component code
opensearch.py
404: Not FoundPGVector
This component creates a PGVector Vector Store with search capabilities. For more information, see the PGVector documentation.
Parameters
| Name | Type | Description |
|---|---|---|
pg_server_url |
SecretString |
PostgreSQL server connection string |
collection_name |
String |
Table name for the vector store |
search_query |
String |
Query for similarity search |
ingest_data |
Data |
Data to be ingested into the vector store |
embedding |
Embeddings |
Embedding function to use |
number_of_results |
Integer |
Number of results to return in search |
| Name | Type | Description |
|---|---|---|
vector_store |
PGVector |
PGVector vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
pgvector.py
404: Not FoundPinecone
This component creates a Pinecone Vector Store with search capabilities.
For more information, see the Pinecone documentation.
Parameters
| Name | Type | Description |
|---|---|---|
index_name |
String |
Name of the Pinecone index |
namespace |
String |
Namespace for the index |
distance_strategy |
String |
Strategy for calculating distance between vectors |
pinecone_api_key |
SecretString |
API key for Pinecone |
text_key |
String |
Key in the record to use as text |
search_query |
String |
Query for similarity search |
ingest_data |
Data |
Data to be ingested into the vector store |
embedding |
Embeddings |
Embedding function to use |
number_of_results |
Integer |
Number of results to return in search |
| Name | Type | Description |
|---|---|---|
vector_store |
Pinecone |
Pinecone vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
pinecone.py
404: Not FoundQdrant
This component creates a Qdrant Vector Store with search capabilities. For more information, see the Qdrant documentation.
Parameters
| Name | Type | Description |
|---|---|---|
collection_name |
String |
Name of the Qdrant collection |
host |
String |
Qdrant server host |
port |
Integer |
Qdrant server port |
grpc_port |
Integer |
Qdrant gRPC port |
api_key |
SecretString |
API key for Qdrant |
prefix |
String |
Prefix for Qdrant |
timeout |
Integer |
Timeout for Qdrant operations |
path |
String |
Path for Qdrant |
url |
String |
URL for Qdrant |
distance_func |
String |
Distance function for vector similarity |
content_payload_key |
String |
Key for content payload |
metadata_payload_key |
String |
Key for metadata payload |
search_query |
String |
Query for similarity search |
ingest_data |
Data |
Data to be ingested into the vector store |
embedding |
Embeddings |
Embedding function to use |
number_of_results |
Integer |
Number of results to return in search |
| Name | Type | Description |
|---|---|---|
vector_store |
Qdrant |
Qdrant vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
qdrant.py
404: Not FoundRedis
This component creates a Redis Vector Store with search capabilities. For more information, see the Redis documentation.
Parameters
| Name | Type | Description |
|---|---|---|
redis_server_url |
SecretString |
Redis server connection string |
redis_index_name |
String |
Name of the Redis index |
code |
String |
Custom code for Redis (advanced) |
schema |
String |
Schema for Redis index |
search_query |
String |
Query for similarity search |
ingest_data |
Data |
Data to be ingested into the vector store |
number_of_results |
Integer |
Number of results to return in search |
embedding |
Embeddings |
Embedding function to use |
| Name | Type | Description |
|---|---|---|
vector_store |
Redis |
Redis vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
redis.py
404: Not FoundSupabase
This component creates a connection to a Supabase Vector Store with search capabilities.
For more information, see the Supabase documentation.
Parameters
| Name | Type | Description |
|---|---|---|
supabase_url |
String |
URL of the Supabase instance |
supabase_service_key |
SecretString |
Service key for Supabase authentication |
table_name |
String |
Name of the table in Supabase |
query_name |
String |
Name of the query to use |
search_query |
String |
Query for similarity search |
ingest_data |
Data |
Data to be ingested into the vector store |
embedding |
Embeddings |
Embedding function to use |
number_of_results |
Integer |
Number of results to return in search |
| Name | Type | Description |
|---|---|---|
vector_store |
SupabaseVectorStore |
Supabase vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
supabase.py
404: Not FoundUpstash
This component creates an Upstash Vector Store with search capabilities. For more information, see the Upstash documentation.
Parameters
| Name | Type | Description |
|---|---|---|
index_url |
String |
The URL of the Upstash index |
index_token |
SecretString |
The token for the Upstash index |
text_key |
String |
The key in the record to use as text |
namespace |
String |
Namespace for the index |
search_query |
String |
Query for similarity search |
metadata_filter |
String |
Filters documents by metadata |
ingest_data |
Data |
Data to be ingested into the vector store |
embedding |
Embeddings |
Embedding function to use (optional) |
number_of_results |
Integer |
Number of results to return in search |
| Name | Type | Description |
|---|---|---|
vector_store |
UpstashVectorStore |
Upstash vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
upstash.py
404: Not FoundVectara
This component creates a Vectara Vector Store with search capabilities. For more information, see the Vectara documentation.
Parameters
| Name | Type | Description |
|---|---|---|
vectara_customer_id |
String |
Vectara customer ID |
vectara_corpus_id |
String |
Vectara corpus ID |
vectara_api_key |
SecretString |
Vectara API key |
embedding |
Embeddings |
Embedding function to use (optional) |
ingest_data |
List[Document/Data] |
Data to be ingested into the vector store |
search_query |
String |
Query for similarity search |
number_of_results |
Integer |
Number of results to return in search |
| Name | Type | Description |
|---|---|---|
vector_store |
Vectara |
Vectara vector store instance |
search_results |
List[Data] |
Results of similarity search |
Component code
vectara.py
404: Not FoundVectara RAG
This component creates a Vectara RAG pipeline. For more information, see the Vectara documentation.
Parameters
| Name | Type | Description |
|---|---|---|
vectara_customer_id |
String |
Vectara customer ID |
vectara_corpus_id |
String |
Vectara corpus ID |
vectara_api_key |
SecretString |
Vectara API key |
search_query |
String |
The query to receive an answer on |
lexical_interpolation |
Float |
Hybrid search factor |
filter |
String |
Metadata filters for narrowing search |
reranker |
String |
Type of reranker to use |
reranker_k |
Integer |
Number of results to rerank |
diversity_bias |
Float |
Diversity bias for MMR reranker |
max_results |
Integer |
Maximum results to summarize |
response_lang |
String |
Language code for response |
prompt |
String |
Name of the summarizer prompt |
| Name | Type | Description |
|---|---|---|
answer |
Message |
Generated response from Vectara RAG |
Component code
vectara_rag.py
404: Not Found