Blog Writer
Build a Blog Writer flow for a one-shot application using OpenAI.
This flow extends the Basic Prompting flow with the URL and Parse data components that fetch content from multiple URLs and convert the loaded data into plain text.
OpenAI uses this loaded data to generate a blog post, as instructed by the Text input and Prompt components.
Open Langflow and start a new project
-
In the Astra Portal header, switch your active app from Astra DB Serverless to Langflow.
-
In Langflow, click New Project, and then select the Blog Writer project.
This opens a starter project with the necessary components to run a one-shot application using OpenAI.
Blog Writer flow
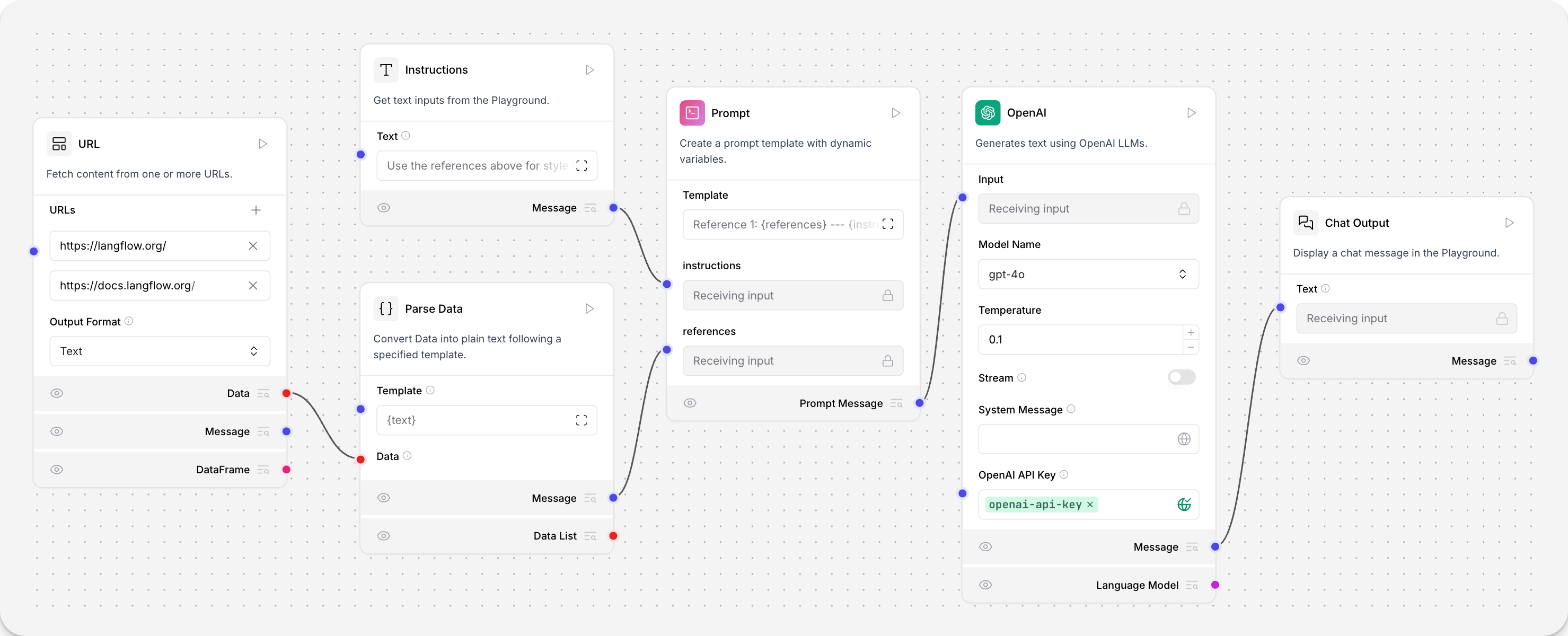
The Blog Writer flow consists of these components:
-
The Text Input component accepts text input.
-
The Prompt component combines the user input with a user-defined prompt.
-
The OpenAI model component sends the user input and prompt to the OpenAI API and receives a response.
-
The Chat Output component prints the flow’s output to the chat.
-
The URL component fetches web content from multiple URLs.
-
The Data to message component parses and converts data into plain text. Prior to Langflow version 1.1.3, this component was named Parse Data.
Run the Blog Writer flow
-
Add your credentials to the Open AI component. The fastest and most secure way to add credentials is with Langflow’s Global Variables.
-
Click Settings, and then click Global Variables.
-
Click Add New.
-
Name your variable. Paste your API key in the Value field.
-
In the Apply To Fields field, select the field you want to globally apply this variable to.
-
Click Save Variable.
-
-
Click Playground to view the flow’s output.
Based on the instructions from the Text input component, the flow generates a blog post with data from the URL component. Now that your query has completed the journey from Text input to Chat output, you have completed the Blog Writer flow.
