Loaders
|
This Langflow feature is currently in public preview. Development is ongoing, and the features and functionality are subject to change. Langflow, and the use of such, is subject to the DataStax Preview Terms. |
|
As of Langflow 1.1, loader components are now found in the Components menu under Bundles. |
Loaders fetch data into Langflow from various sources, such as databases, websites, and local files.
Use a loader component in a flow
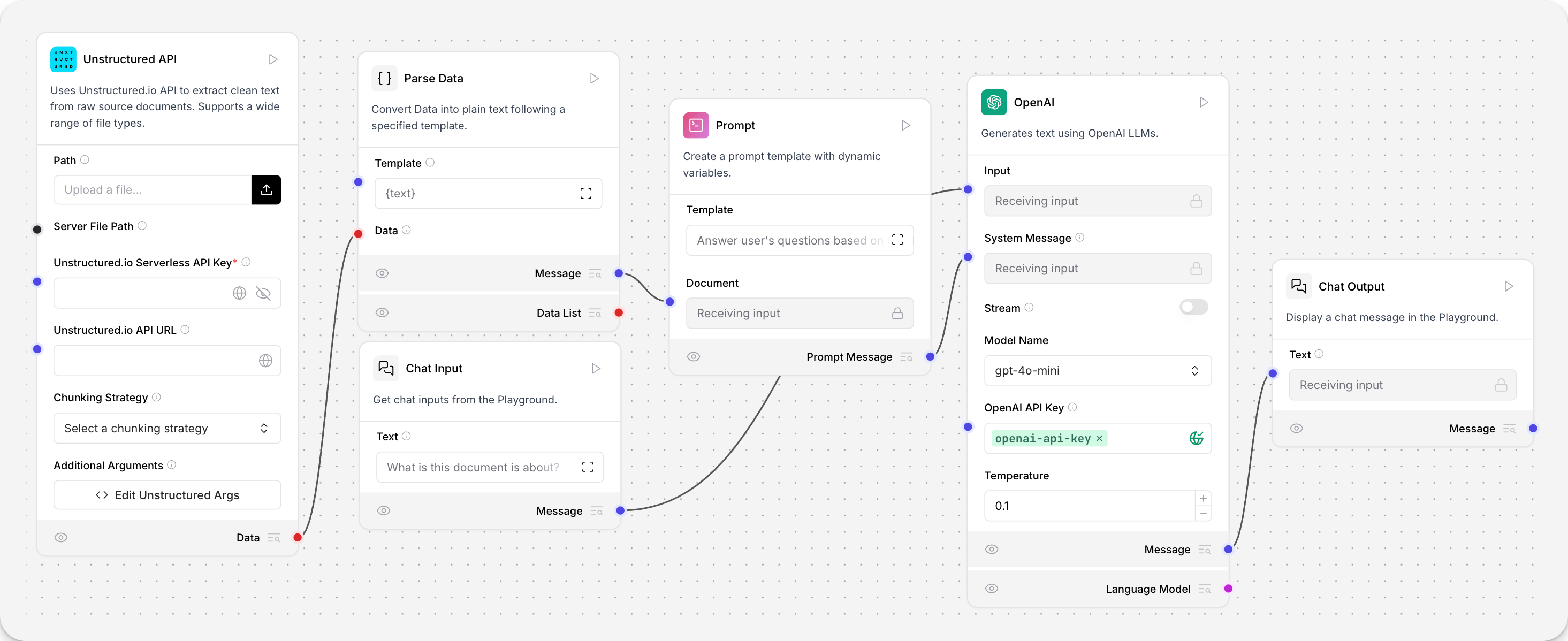
This flow creates a question-and-answer chatbot for documents that are loaded into the flow.
The Unstructured.io loader component loads files from your local machine, and then parses them into a list of structured Data objects. This loaded data informs the Open AI component’s responses to your questions.
Confluence
The component integrates with Confluence, a wiki collaboration platform, to load and process documents. It uses the ConfluenceLoader from LangChain to fetch content from a specified Confluence space.
Parameters
| Name | Display Name | Info |
|---|---|---|
url |
Site URL |
The base URL of the Confluence Space (e.g., https://<company>.atlassian.net/wiki) |
username |
Username |
Atlassian User E-mail (e.g., email@example.com) |
api_key |
API Key |
Atlassian API Key (Create at: https://id.atlassian.com/manage-profile/security/api-tokens) |
space_key |
Space Key |
The key of the Confluence space to access |
cloud |
Use Cloud? |
Whether to use Confluence Cloud (default: true) |
content_format |
Content Format |
Specify content format (default: STORAGE) |
max_pages |
Max Pages |
Maximum number of pages to retrieve (default: 1000) |
| Name | Display Name | Info |
|---|---|---|
data |
Data |
List of Data objects containing the loaded Confluence documents |
GitLoader
This component utilizes the GitLoader from LangChain to fetch and load documents from a specified Git repository.
Parameters
| Name | Display Name | Info |
|---|---|---|
repo_path |
Repository Path |
The local path to the Git repository |
clone_url |
Clone URL |
The URL to clone the Git repository from (optional) |
branch |
Branch |
The branch to load files from (default: 'main') |
file_filter |
File Filter |
Patterns to filter files (e.g., '.py' to include only .py files, '!.py' to exclude .py files) |
content_filter |
Content Filter |
A regex pattern to filter files based on their content |
| Name | Display Name | Info |
|---|---|---|
data |
Data |
List of Data objects containing the loaded Git repository documents |
Unstructured
This component uses the Unstructured Serverless API to load and parse PDF, DOCX, and TXT files into structured data.
This component does not work with the Unstructured open-source library.
Parameters
| Name | Display Name | Info |
|---|---|---|
file |
File |
The path to the file to be parsed (supported types: pdf, docx, txt) |
api_key |
API Key |
Unstructured API Key |
| Name | Display Name | Info |
|---|---|---|
data |
Data |
List of Data objects containing the parsed content from the input file |
