入門 - DataStax Studioのクイック・スタート
データを挿入して探索を実行します。
グラフ・データベースは、オブジェクト間の簡素な関係や複雑な関係を検出するために便利です。オブジェクトが他のオブジェクトと、およびその環境とどのように相互に作用するのかは、関係に左右されます。グラフ・データベースは、オブジェクト間の関係を完璧に表現することができます。
- 頂点
- 頂点は、人、場所、自動車、レシピなどのオブジェクトで、名詞と考えられるあらゆるものがあります。
- 辺
- 辺は、2つの頂点間の関係を定義します。人はソフトウェアを作成し、著者は本を記述します。辺を定義するのは動詞と考えてください。
- プロパティ
- 頂点または辺いずれかの属性を記述したキーと値のペア。プロパティ・キーは、キーと値のペアでキーを記述するために使用します。DSE Graphではすべてのプロパティはグローバルです。これは、プロパティがどの頂点についても使用できることを意味します。たとえば、グラフ内のすべての頂点に対して"name"というプロパティを使用できます。
プロパティ・グラフは一般的に大規模なグラフですが、プロパティ・グラフに対するクエリーの性質は、グラフに多数の頂点があるのか、辺があるのか、頂点と辺の両方があるのかによって異なります。手始めに、グラフ・データベースの概念を把握するために、わかりやすいように サンプル・グラフを例にとってみましょう。ここでは、食べ物の分野を探索する例を使用します。
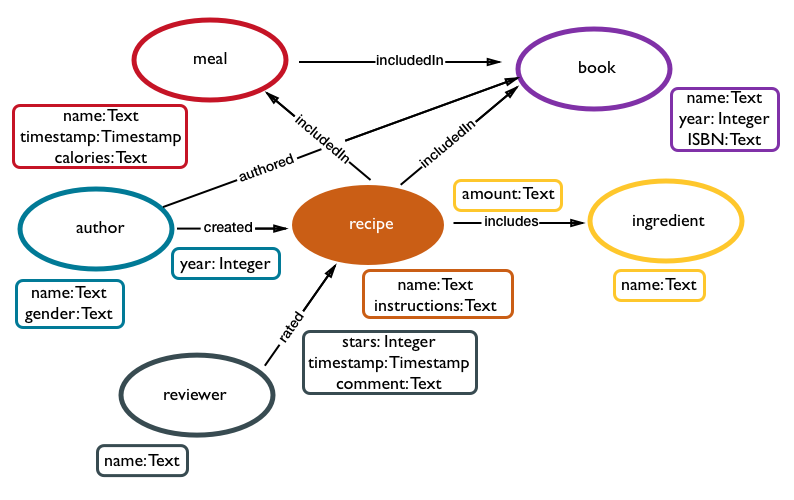
要素には、頂点ラベルおよび辺ラベルを使用して、グラフ・データベース内の頂点および辺のタイプを区別するためのラベルが付けられます。author(著者)というラベルが付いている頂点は、著者に関する情報を保持します。authorとbook(本)間の辺には、authored(執筆)というラベルが付いています。適切なラベルを指定することは、グラフ・データ・モデリングにおける重要なステップです。
頂点と辺は通常、プロパティを持っています。たとえば、author頂点は、name(名前)とgender(性別)というプロパティを持つことができます。辺もプロパティを持つことができます。created(創作)辺は、隣接するrecipe(レシピ)頂点が作成された年を識別するyear(年)プロパティを持つことができます。
グラフ・データベース内の情報は、グラフ探索を使用して取得します。グラフ探索では、結果が返されるまで、定義された開始点から1つまたは一連の探索手順 によってグラフを「巡回」し、各ステップをフィルターします。
グラフ探索を使用して情報を取得するには、最初にデータを挿入する必要があります。以下のセクションに記載する手順に従うと、最小限の構成とスキーマ作成でDSE Graphの基本知識を身に付けることができます。
手順
-
グラフ内に存在する頂点の数を確認するには、探索ステップ
count()を使用します。現時点ではまだデータを追加していないため、頂点の数はゼロです。すべての頂点を取得するにはグラフ探索gをV() に連結し、頂点の数を計算するにはcount() に連結します。連結することによって、最も効率の良い順序でシーケンシャルな探索手順が実行されます。g.V().count()
 注意:
注意:g.V().count()を使用して完全グラフスキャンを行うクエリーは、大規模グラフに対しては実行しないでください。複数のDSEノードが構成されている場合、この探索ステップは、集中的に、クラスター内のすべてのノードのすべてのパーティションに対して巡回を行います。
簡単な例
それでは、簡単なレシピ・データ・モデル例から始めましょう。このデータは2つの頂点で構成されます。1つはauthor(Julia Child)、もう1つはbook(The Art of French Cooking, Vol. 1)です。これらの頂点の間には辺があり、Julia Childがその本を書いたことを表しています。 スキーマを一切作成せずに、これら3つの要素を下記のように作成できます。ただし、DSE Graphは、後述するように、最も妥当なスキーマを推定します。
-
まず、Julia Childの頂点を作成します。頂点ラベルはauthorで、nameとgenderについてはプロパティ・キーと値の2つのペアを作成します。ラベルは、頂点ラベルを設定するキーと値のペアのキーを指定することに注意してください。下記のコマンドを実行し、Raw(原型)、Table(テーブル)、およびGraph(グラフ)の各ビューを表示するボタンを使用して結果を確認します。
juliaChild = graph.addVertex(label,'author', 'name','Julia Child', 'gender','F')
 各ビューには同じ情報が表示されます。
各ビューには同じ情報が表示されます。- member_id、community_id、およびlabelで構成される自動生成のid
グラフ・ストレージ構造内のmember_id頂点およびcommunity_idグループの頂点(グラフ探索の構造を参照)
- 頂点ラベル
- プロパティであるname、gender、およびそれらの値
次のコマンドを実行してbook(本)頂点を作成します。コマンドは、どれであっても再実行しないようにしてください。再実行すると、グラフ内に頂点が重複して作成されてしまいます。
- member_id、community_id、およびlabelで構成される自動生成のid
-
グラフ内にbook頂点を作成します。
artOfFrenchCookingVolOne = graph.addVertex(label, 'book','name', 'The Art of French Cooking, Vol. 1', 'year', 1961)
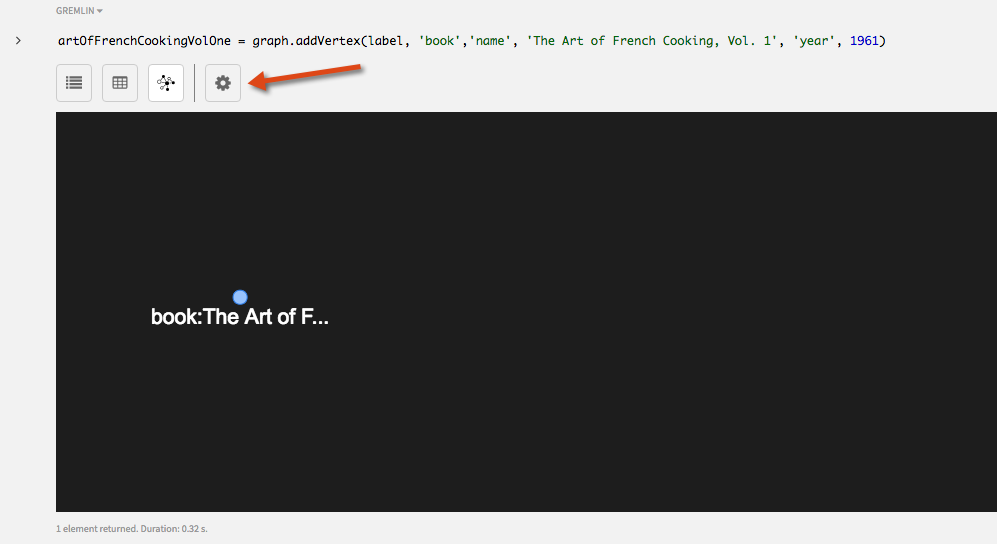
author頂点と同様に、作成したbook頂点に関するすべての情報を表示できます。Graph(グラフ)ビューで、設定ボタン(歯車アイコン)を使用し、
Chef {{name}}を入力してauthorの表示ラベルを変更します。{{label}}:{{name}}を使用してbookの表示ラベルを変更します。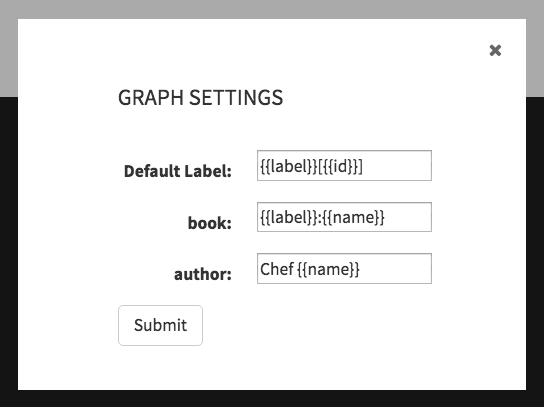
-
次の2つのコマンドを実行します。最初のコマンドは、author頂点とbook頂点間の辺を作成します。2つ目のコマンドは、2つの頂点とそれらを結ぶ辺を取得するグラフ探索です。関係を表示するには、Graph(グラフ)ビューを使用します。詳細情報を表示するには、要素上をスクロールします。
juliaChild.addEdge('authored', artOfFrenchCookingVolOne) g.V()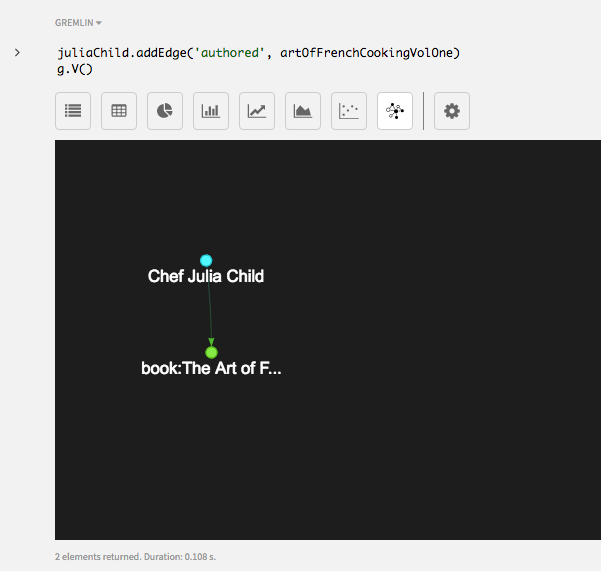
データが追加されました。
-
著者について挿入されたデータが正しいことを、頂点ラベル
authorとプロパティname = Julia Childを使用し、has()ステップをチェックすることによって確認します。具体的な情報によってグラフの検索が絞り込まれるので、このグラフ探索は、さらに複雑な探索の基本的な開始点となります。g.V().has('author', 'name', 'Julia Child')結果を表示するために、Raw(原型)ビューよりもはるかに見やすいTable(テーブル)ビュー を使用します。
Julia Childのauthor頂点の頂点情報が表示されます。頂点ラベルは頂点の種類を指定し、キーと値のペアは、nameとgenderのプロパティ・キーとその値を指定します。自動的に生成されるidは、1つの頂点ラベルと、グラフ内のその頂点の位置に関連付けられた2つの構成要素で構成されます。「グラフ探索の構造」では、そのidの構成要素について解説しています。 -
もう1つの有用な探索は、指定された頂点のプロパティ値ごとにキーと値のリストを出力する
valueMap()です。g.V().hasLabel('author').valueMap()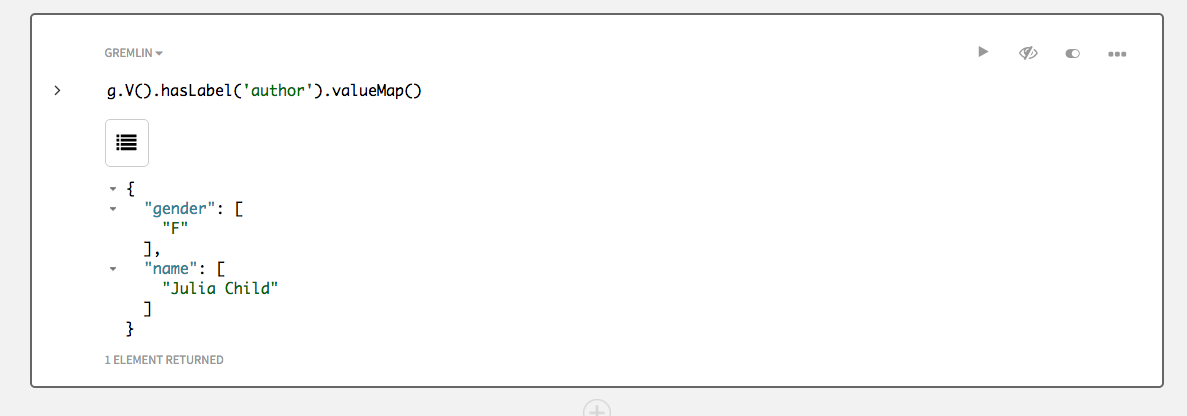
-
特定のプロパティ・キーの値のみ必要な場合は、
values()探索ステップを使用してください。次の例は、すべての頂点のnameを取得します。g.V().values('name')存在する頂点は2つなので、2つの結果が返されます。複数の頂点が存在する場合は、
nameを持つすべての頂点の結果がこの探索ステップによって返されます。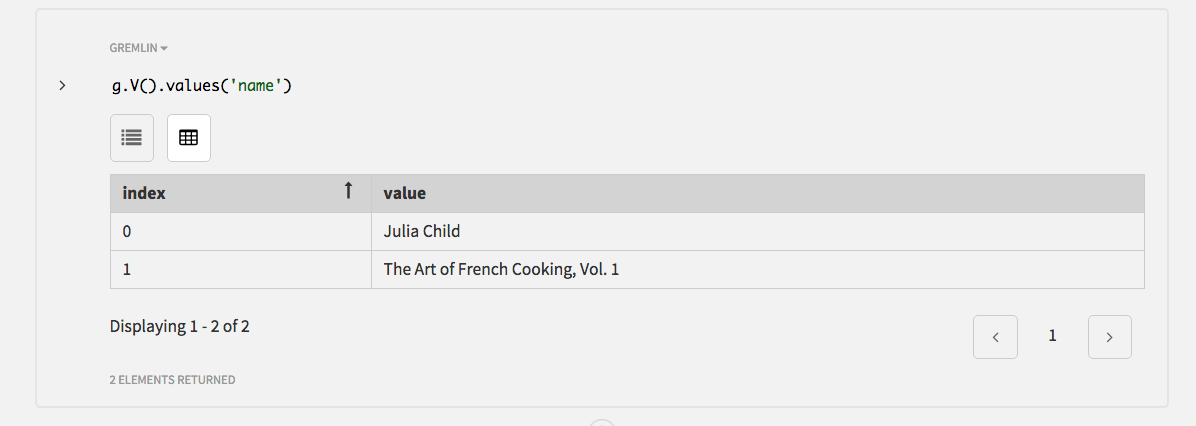
-
探索ステップ
count()は、頂点と辺の数をカウントするのに便利です。辺数をカウントするには、V()をE()に置き換えてください。辺は1つになるはずです。g.E().count()
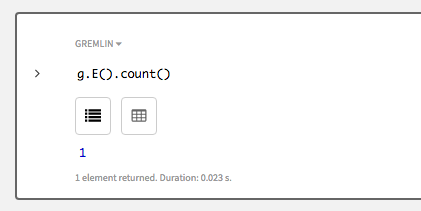
-
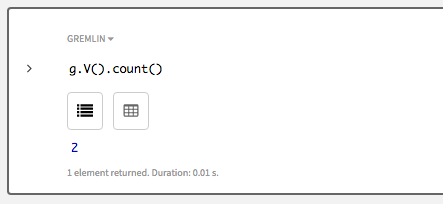
このチュートリアルの冒頭で行った頂点のカウント数探索を再実行すると、今度は、2つの頂点が返されるはずです。
g.V().count()
スキーマの作成
グラフにデータを追加する前に、スキーマについて少し説明します。スキーマは、グラフのプロパティとそのデータ型を定義します。これらのプロパティはさらに、頂点ラベルおよび辺ラベルの定義に使用します。スキーマ作成における最終的な重要ステップはインデックス作成です。インデックスは、グラフ探索の効率化および高速化に重要な役割を果たします。詳細については、スキーマの作成とインデックスの作成を参照してください。
最初に、プロパティ・キーのスキーマを作成しましょう。次の2つのセルでは、最初のコマンドは、以前に作成された頂点と辺のスキーマを消去します。スキーマ作成が完了したら、次のステップで、要素のデータを長いスクリプトで再入力します。
-
新しいスキーマを作成します。
-
スキーマを消去します。
schema.clear()
-
新しいプロパティ・キーのスキーマを作成します。
// プロパティ・キー // ifNotExists()を使用して、作成済みのプロパティ・キーがあるかどうかを確認します。 schema.propertyKey('name').Text().ifNotExists().create() schema.propertyKey('gender').Text().create() schema.propertyKey('instructions').Text().create() schema.propertyKey('category').Text().create() schema.propertyKey('year').Int().create() schema.propertyKey('timestamp').Timestamp().create() schema.propertyKey('ISBN').Text().create() schema.propertyKey('calories').Int().create() schema.propertyKey('amount').Text().create() schema.propertyKey('stars').Int().create() // single()はオプションです(デフォルトのため) schema.propertyKey('comment').Text().single().create() // 複数の値を指定できる複数プロパティの例 // schema.propertyKey('nickname').Text().multiple().create() // 次の2行は2つのプロパティを定義した後、'country'に対するメタプロパティ'livedIn'を作成します //メタプロパティとは、プロパティのプロパティです // 例:'livedIn':'1999-2005' 'country':'Belgium' schema.propertyKey('livedIn').Text().create() schema.propertyKey('country').Text().multiple().properties('livedIn').create()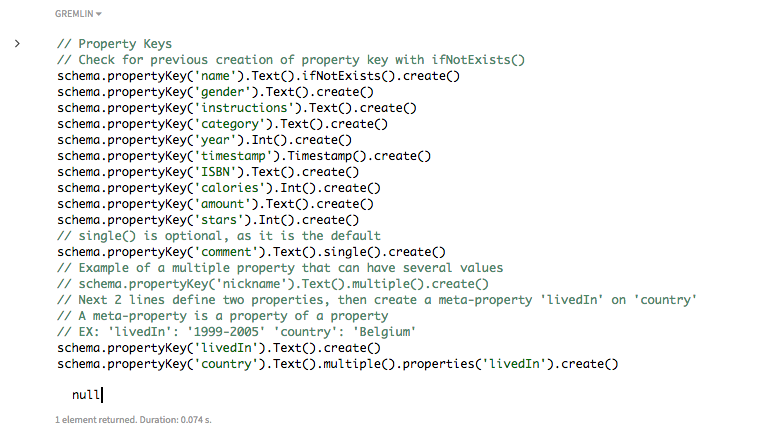
各プロパティは、データ型を使用して定義する必要があります。DSE Graphのデータ型は、Cassandraのデータ型と連動しています。ここで使用するデータ型はText、Int、およびTimestampです。デフォルトでは、プロパティにはカーディナリティが1つありますが、複数のカーディナリティを使用してプロパティを定義することができます。複数のカーディナリティを使用すると、プロパティに複数の値を割り当てることができます。
また、プロパティはそれ自身のプロパティ、つまり、メタプロパティを持つことができます。メタプロパティは、1段だけ深くネストすることができ、個々のプロパティに情報を割り当てるのに重宝します。プロパティ・キーは、
ifNotExists()メソッドを追加して作成できます。このメソッドでは、すでに存在する定義の上書きを防ぐことができます。プロパティ・キーを作成した後、頂点ラベルと辺ラベルを定義できます。
-
スキーマを消去します。
-
頂点ラベルと辺ラベルのスキーマを作成します。
// 頂点ラベル schema.vertexLabel('author').ifNotExists().create() schema.vertexLabel('recipe').create() // プロパティを含む頂点ラベルの作成例 // schema.vertexLabel('recipe').properties('name','instructions').create() // 以前に作成した頂点ラベルへのプロパティの追加例 // schema.vertexLabel('recipe').properties('name','instructions').add() schema.vertexLabel('ingredient').create() schema.vertexLabel('book').create() schema.vertexLabel('meal').create() schema.vertexLabel('reviewer').create() // カスタム頂点IDの例: // schema.propertyKey('city_id').Int().create() // schema.propertyKey('sensor_id').Uuid().create() // schema().vertexLabel('FridgeSensor').partitionKey('city_id').clusteringKey('sensor_id').create() // 辺ラベル schema.edgeLabel('authored').ifNotExists().create() schema.edgeLabel('created').create() schema.edgeLabel('includes').create() schema.edgeLabel('includedIn').create() schema.edgeLabel('rated').connection('reviewer','recipe').create()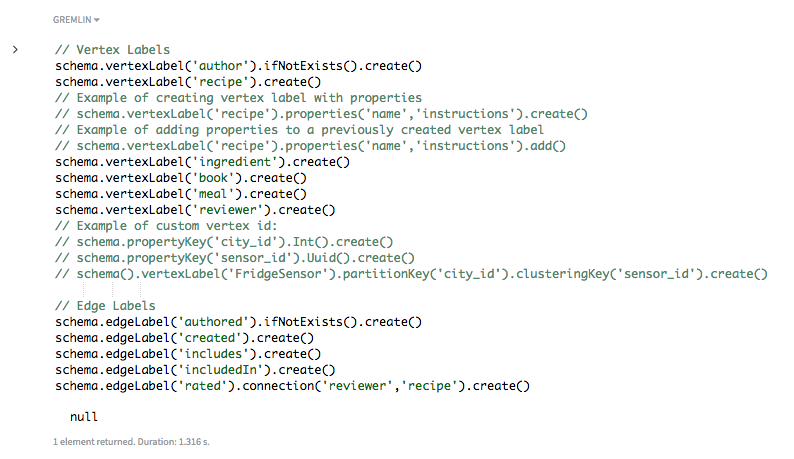
頂点ラベルのスキーマは、ラベルtypeを定義し、この頂点ラベルに関連付けられたプロパティを任意で定義します。プロパティと頂点ラベルの関連付けを定義する方法は2つあります。1つはスキーマ作成時、もう1つは頂点ラベルの追加後にプロパティを追加する方法です。どのようなスキーマの作成にも
ifNotExists()を使用できます。頂点IDは自動的に作成されますが、カスタム頂点IDは必要に応じて作成できます。以下に示す、カスタム頂点IDの例は、パーティション・キーとクラスター化キーを定義します。
辺ラベルのスキーマは、ラベルtypeを定義し、辺ラベルによって接続されている2つの頂点ラベルを任意で定義します。
rated辺ラベルは、頂点ラベルreviewerおよびrecipeを持つ隣接頂点間の辺を定義します。 -
インデックス・スキーマを作成します。
// 頂点インデックス // 二次インデックス schema.vertexLabel('author').index('byName').secondary().by('name').add() // マテリアライズド・インデックス schema.vertexLabel('recipe').index('byRecipe').materialized().by('name').add() schema.vertexLabel('meal').index('byMeal').materialized().by('name').add() schema.vertexLabel('ingredient').index('byIngredient').materialized().by('name').add() schema.vertexLabel('reviewer').index('byReviewer').materialized().by('name').add() // サーチ // schema.vertexLabel('recipe').index('search').search().by('instructions').asText().add() // schema.vertexLabel('recipe').index('search').search().by('instructions').asString().add() // 複数のプロパティ・キーにサーチ・インデックスが付いている場合 // schema.vertexLabel('recipe').index('search').search().by('instructions').asText().by('category').asString().add() // メタプロパティ'livedIn'を使用したプロパティ・インデックス: schema.vertexLabel('author').index('byLocation').property('country').by('livedIn').add() // 辺インデックス schema.vertexLabel('reviewer').index('ratedByStars').outE('rated').by('stars').add()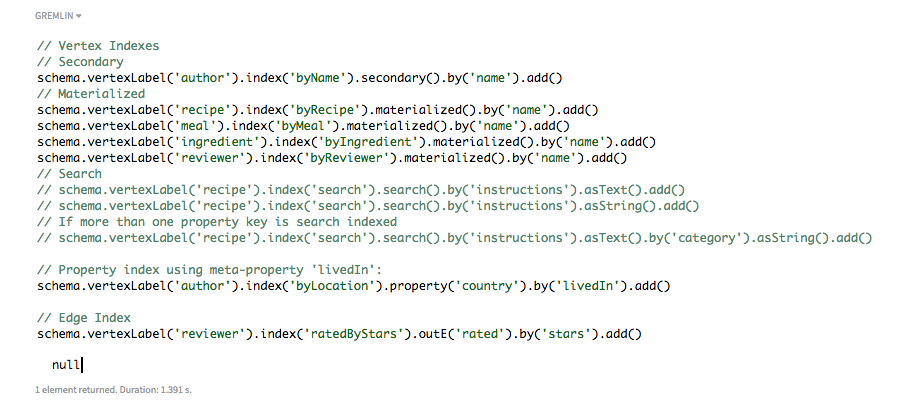
インデックス作成 は、複雑で非常に重要なテーマです。ここでは、いくつかの種類のインデックスを作成します。二次インデックスとマテリアライズド・インデックスは、簡潔にいうと、Cassandra組み込みインデックス作成を使用した2種類のインデックスです。 サーチ・インデックスは、SolrベースのDSE Searchを使用します。頂点ラベルごとに作成できるサーチ・インデックスは1つだけですが、複数のプロパティを含めることができます。プロパティ・インデックスを使用すると、メタプロパティにインデックスを作成できます。辺インデックスを使用すると、辺上のプロパティにインデックスを作成できます。以前に作成した頂点ラベルにインデックスを追加するには、
add()を使用します。 -
スキーマを確認します。
schema.describe()

schema.describe()コマンドは、入力したスキーマの再作成に使用できるスキーマを表示します。スキーマを作成せずにデータを入力する場合は、このコマンドを使用して、プロパティごとに設定されているデータ型を確認できます。現在、DSE Graphでは、一度作成したスキーマは変更できません。プロパティ、頂点ラベル、辺ラベル、およびインデックスは追加作成できますが、プロパティのデータ型などは変更できません。スキーマを作成せずにデータを入力する方法は、開発および学習時には有効です。この方法は、実際の適用においてはお勧めしないことを強調しておきます。Productionモードでは、データが一度ロードされた後にスキーマを作成することはできません。
-
describe()リスト内の特定のタイプの項目のスキーマだけを見つけるには、次のコマンドを使用します。schema.describe().split('\n').grep(~/.*index.*/)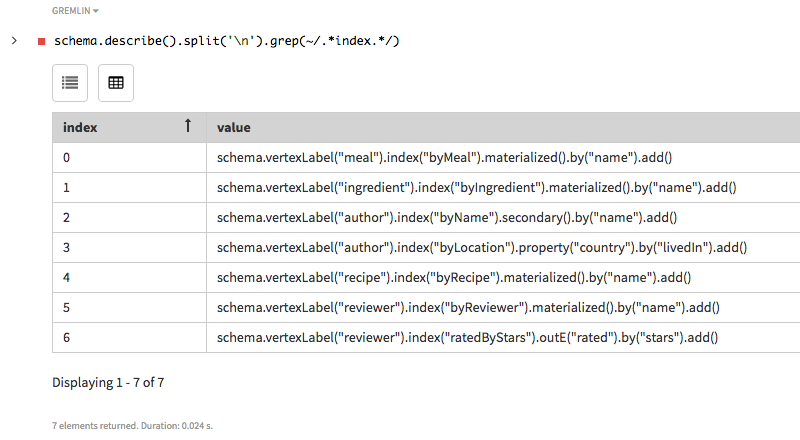
ステップを追加すると、出力が改行で分割して表示し、
indexで示されるような文字列を検索できます。ここで使用するGremlinバリアントは、Apache Groovyをベースとしているため、グラフ探索の操作にはどのようなGroovyコマンドでも使用できます。 Apache Groovyは、Javaを円滑に統合してスクリプト記述機能を提供する言語です。
データの追加
-
スキーマが作成されました。次は、レシピ・データ・モデル内でさらに接続を探索するために次のスクリプトを使用してグラフに頂点と辺を追加入力します。1つのDataStax Studioセル内に次の行を入力して実行します。 最初のコマンド、
g.V().drop().iterate()は、新しいデータを読み込む前にすべての頂点および辺データを削除します。スクリプト実行後は、必ず、Graph(グラフ)ビューを選択してください。// generateRecipe.groovy // Recipe(レシピ)のすべての頂点および辺を追加します g.V().drop().iterate() // author(著者)頂点 juliaChild = graph.addVertex(label, 'author', 'name','Julia Child', 'gender', 'F') simoneBeck = graph.addVertex(label, 'author', 'name', 'Simone Beck', 'gender', 'F') louisetteBertholie = graph.addVertex(label, 'author', 'name', 'Louisette Bertholie', 'gender', 'F') patriciaSimon = graph.addVertex(label, 'author', 'name', 'Patricia Simon', 'gender', 'F') aliceWaters = graph.addVertex(label, 'author', 'name', 'Alice Waters', 'gender', 'F') patriciaCurtan = graph.addVertex(label, 'author', 'name', 'Patricia Curtan', 'gender', 'F') kelsieKerr = graph.addVertex(label, 'author', 'name', 'Kelsie Kerr', 'gender', 'F') fritzStreiff = graph.addVertex(label, 'author', 'name', 'Fritz Streiff', 'gender', 'M') emerilLagasse = graph.addVertex(label, 'author', 'name', 'Emeril Lagasse', 'gender', 'M') jamesBeard = graph.addVertex(label, 'author', 'name', 'James Beard', 'gender', 'M') // book(本)頂点 artOfFrenchCookingVolOne = graph.addVertex(label, 'book', 'name', 'The Art of French Cooking, Vol. 1', 'year', 1961) simcasCuisine = graph.addVertex(label, 'book', 'name', "Simca's Cuisine:100 Classic French Recipes for Every Occasion", 'year', 1972, 'ISBN', '0-394-40152-2') frenchChefCookbook = graph.addVertex(label, 'book', 'name','The French Chef Cookbook', 'year', 1968, 'ISBN', '0-394-40135-2') artOfSimpleFood = graph.addVertex(label, 'book', 'name', 'The Art of Simple Food:Notes, Lessons, and Recipes from a Delicious Revolution', 'year', 2007, 'ISBN', '0-307-33679-4') // recipe(レシピ)頂点 beefBourguignon = graph.addVertex(label, 'recipe', 'name', 'Beef Bourguignon', 'instructions', 'Braise the beef.玉ねぎと人参を炒めます。ワインを入れたら、厚手鍋で220度で1時間調理します') ratatouille = graph.addVertex(label, 'recipe', 'name', 'Rataouille', 'instructions', 'Peel and cut the egglant.ナスは縦に、幅2.5cm、長さ7.5cm、厚さ1cmに切ります') saladeNicoise = graph.addVertex(label, 'recipe', 'name', 'Salade Nicoise', 'instructions', '供する直前にサラダ・ボウルか大皿にレタスの葉を並べます。レタスにオリーブオイルをたらし、塩を振りかけます。') wildMushroomStroganoff = graph.addVertex(label, 'recipe', 'name', 'Wild Mushroom Stroganoff', 'instructions', 'パッケージに記載された説明に従って卵めんを茹でて温かくしておきます。大きめのソテー・パンに大さじ1と1/2のオリーブオイルを入れ、強めの中火で熱します。') spicyMeatloaf = graph.addVertex(label, 'recipe', 'name', 'Spicy Meatloaf', 'instructions', 'オーブンを190度に予熱します。大きなスキレットにベーコンを入れ、脂が出てカリッとするまで8〜10分中火で炒めます。') oystersRockefeller = graph.addVertex(label, 'recipe', 'name', 'Oysters Rockfeller', 'instructions', 'エシャロット、セロリ、ハーブ、調味料を大さじ3杯のバターで3分間炒めます。クレソンを入れてしんなりさせます。') carrotSoup = graph.addVertex(label, 'recipe', 'name', 'Carrot Soup', 'instructions', '厚手の鍋にバターを溶かします。バターが泡立ってきたら玉ねぎ、タイムを加え、柔らかくなるまで約10分間、中火で炒めます。') roastPorkLoin = graph.addVertex(label, 'recipe', 'name', 'Roast Pork Loin', 'instructions', '前日に骨端の約2.5cm手前で止めて肉を骨から分離しておきます。豚肉にまんべんなく塩コショウをふって染み込ませ一晩冷蔵庫に入れて置きます。') // ingredient(材料)頂点 beef = graph.addVertex(label, 'ingredient', 'name', 'beef') onion = graph.addVertex(label, 'ingredient', 'name', 'onion') mashedGarlic = graph.addVertex(label, 'ingredient', 'name', 'mashed garlic') butter = graph.addVertex(label, 'ingredient', 'name', 'butter') tomatoPaste = graph.addVertex(label, 'ingredient', 'name', 'tomato paste') eggplant = graph.addVertex(label, 'ingredient', 'name', 'eggplant') zucchini = graph.addVertex(label, 'ingredient', 'name', 'zucchini') oliveOil = graph.addVertex(label, 'ingredient', 'name', 'olive oil') yellowOnion = graph.addVertex(label, 'ingredient', 'name', 'yellow onion') greenBean = graph.addVertex(label, 'ingredient', 'name', 'green beans') tuna = graph.addVertex(label, 'ingredient', 'name', 'tuna') tomato = graph.addVertex(label, 'ingredient', 'name', 'tomato') hardBoiledEgg = graph.addVertex(label, 'ingredient', 'name', 'hard-boiled egg') eggNoodles = graph.addVertex(label, 'ingredient', 'name', 'egg noodles') mushroom = graph.addVertex(label, 'ingredient', 'name', 'mushrooms') bacon = graph.addVertex(label, 'ingredient', 'name', 'bacon') celery = graph.addVertex(label, 'ingredient', 'name', 'celery') greenBellPepper = graph.addVertex(label, 'ingredient', 'name', 'green bell pepper') groundBeef = graph.addVertex(label, 'ingredient', 'name', 'ground beef') porkSausage = graph.addVertex(label, 'ingredient', 'name', 'pork sausage') shallot = graph.addVertex(label, 'ingredient', 'name', 'shallots') chervil = graph.addVertex(label, 'ingredient', 'name', 'chervil') fennel = graph.addVertex(label, 'ingredient', 'name', 'fennel') parsley = graph.addVertex(label, 'ingredient', 'name', 'parsley') oyster = graph.addVertex(label, 'ingredient', 'name', 'oyster') pernod = graph.addVertex(label, 'ingredient', 'name', 'Pernod') thyme = graph.addVertex(label, 'ingredient', 'name', 'thyme') carrot = graph.addVertex(label, 'ingredient', 'name', 'carrots') chickenBroth = graph.addVertex(label, 'ingredient', 'name', 'chicken broth') porkLoin = graph.addVertex(label, 'ingredient', 'name', 'pork loin') redWine = graph.addVertex(label, 'ingredient', 'name', 'red wine') // meal(食事)頂点 // timestampは、Instant.parse()抜きで'2015-01-01'と入力することもできます。 SaturdayFeast = graph.addVertex(label, 'meal', 'name', 'Saturday Feast', 'timestamp', '2015-11-30', 'calories', 1000) EverydayDinner = graph.addVertex(label, 'meal', 'name', 'EverydayDinner', 'timestamp', '2016-01-14', 'calories', 600) JuliaDinner = graph.addVertex(label, 'meal', 'name', 'JuliaDinner', 'timestamp', '2016-01-14', 'calories', 900) // authorとbook間の辺 juliaChild.addEdge('authored', artOfFrenchCookingVolOne) simoneBeck.addEdge('authored', artOfFrenchCookingVolOne) louisetteBertholie.addEdge('authored', artOfFrenchCookingVolOne) simoneBeck.addEdge('authored', simcasCuisine) patriciaSimon.addEdge('authored', simcasCuisine) juliaChild.addEdge('authored', frenchChefCookbook) aliceWaters.addEdge('authored', artOfSimpleFood) patriciaCurtan.addEdge('authored', artOfSimpleFood) kelsieKerr.addEdge('authored', artOfSimpleFood) fritzStreiff.addEdge('authored', artOfSimpleFood) // author - recipe間の辺 juliaChild.addEdge('created', beefBourguignon, 'year', 1961) juliaChild.addEdge('created', ratatouille, 'year', 1965) juliaChild.addEdge('created', saladeNicoise, 'year', 1962) emerilLagasse.addEdge('created', wildMushroomStroganoff, 'year', 2003) emerilLagasse.addEdge('created', spicyMeatloaf, 'year', 2000) aliceWaters.addEdge('created', carrotSoup, 'year', 1995) aliceWaters.addEdge('created', roastPorkLoin, 'year', 1996) jamesBeard.addEdge('created', oystersRockefeller, 'year', 1970) // recipe - ingredient間の辺 beefBourguignon.addEdge('includes', beef, 'amount', '2 lbs') beefBourguignon.addEdge('includes', onion, 'amount', '1 sliced') beefBourguignon.addEdge('includes', mashedGarlic, 'amount', '2 cloves') beefBourguignon.addEdge('includes', butter, 'amount', '3.5 Tbsp') beefBourguignon.addEdge('includes', tomatoPaste, 'amount', '1 Tbsp') ratatouille.addEdge('includes', eggplant, 'amount', '1 lb') ratatouille.addEdge('includes', zucchini, 'amount', '1 lb') ratatouille.addEdge('includes', mashedGarlic, 'amount', '2 cloves') ratatouille.addEdge('includes', oliveOil, 'amount', '4-6 Tbsp') ratatouille.addEdge('includes', yellowOnion, 'amount', '1 1/2 cups or 1/2 lb thinly sliced') saladeNicoise.addEdge('includes', oliveOil, 'amount', '2-3 Tbsp') saladeNicoise.addEdge('includes', greenBean, 'amount', '1 1/2 lbs blanched, trimmed') saladeNicoise.addEdge('includes', tuna, 'amount', '8-10 ozs oil-packed, drained and flaked') saladeNicoise.addEdge('includes', tomato, 'amount', '3 or 4 red, peeled, quartered, cored, and seasoned') saladeNicoise.addEdge('includes', hardBoiledEgg, 'amount', '8 halved lengthwise') wildMushroomStroganoff.addEdge('includes', eggNoodles, 'amount', '16 ozs wmyIde') wildMushroomStroganoff.addEdge('includes', mushroom, 'amount', '2 lbs wild or exotic, cleaned, stemmed, and sliced') wildMushroomStroganoff.addEdge('includes', yellowOnion, 'amount', '1 cup thinly sliced') spicyMeatloaf.addEdge('includes', bacon, 'amount', '3 ozs diced') spicyMeatloaf.addEdge('includes', onion, 'amount', '2 cups finely chopped') spicyMeatloaf.addEdge('includes', celery, 'amount', '2 cups finely chopped') spicyMeatloaf.addEdge('includes', greenBellPepper, 'amount', '1/4 cup finely chopped') spicyMeatloaf.addEdge('includes', porkSausage, 'amount', '3/4 lbs hot') spicyMeatloaf.addEdge('includes', groundBeef, 'amount', '1 1/2 lbs chuck') oystersRockefeller.addEdge('includes', shallot, 'amount', '1/4 cup chopped') oystersRockefeller.addEdge('includes', celery, 'amount', '1/4 cup chopped') oystersRockefeller.addEdge('includes', chervil, 'amount', '1 tsp') oystersRockefeller.addEdge('includes', fennel, 'amount', '1/3 cup chopped') oystersRockefeller.addEdge('includes', parsley, 'amount', '1/3 cup chopped') oystersRockefeller.addEdge('includes', oyster, 'amount', '2 dozen on the half shell') oystersRockefeller.addEdge('includes', pernod, 'amount', '1/3 cup') carrotSoup.addEdge('includes', butter, 'amount', '4 Tbsp') carrotSoup.addEdge('includes', onion, 'amount', '2 medium sliced') carrotSoup.addEdge('includes', thyme, 'amount', '1 sprig') carrotSoup.addEdge('includes', carrot, 'amount', '2 1/2 lbs, peeled and sliced') carrotSoup.addEdge('includes', chickenBroth, 'amount', '6 cups') roastPorkLoin.addEdge('includes', porkLoin, 'amount', '1 bone-in, 4-rib') roastPorkLoin.addEdge('includes', redWine, 'amount', '1/2 cup') roastPorkLoin.addEdge('includes', chickenBroth, 'amount', '1 cup') // book - recipe間の辺 beefBourguignon.addEdge('includedIn', artOfFrenchCookingVolOne) saladeNicoise.addEdge('includedIn', artOfFrenchCookingVolOne) carrotSoup.addEdge('includedIn', artOfSimpleFood) // meal - recipe間の辺 beefBourguignon.addEdge('includedIn', SaturdayFeast) carrotSoup.addEdge('includedIn', SaturdayFeast) oystersRockefeller.addEdge('includedIn', SaturdayFeast) carrotSoup.addEdge('includedIn', EverydayDinner) roastPorkLoin.addEdge('includedIn', EverydayDinner) beefBourguignon.addEdge('includedIn', JuliaDinner) saladeNicoise.addEdge('includedIn', JuliaDinner) // meal – book間の辺 EverydayDinner.addEdge('includedIn', artOfSimpleFood) SaturdayFeast.addEdge('includedIn', simcasCuisine) JuliaDinner.addEdge('includedIn', artOfFrenchCookingVolOne) g.V()レシピ・サンプル・グラフのデータ 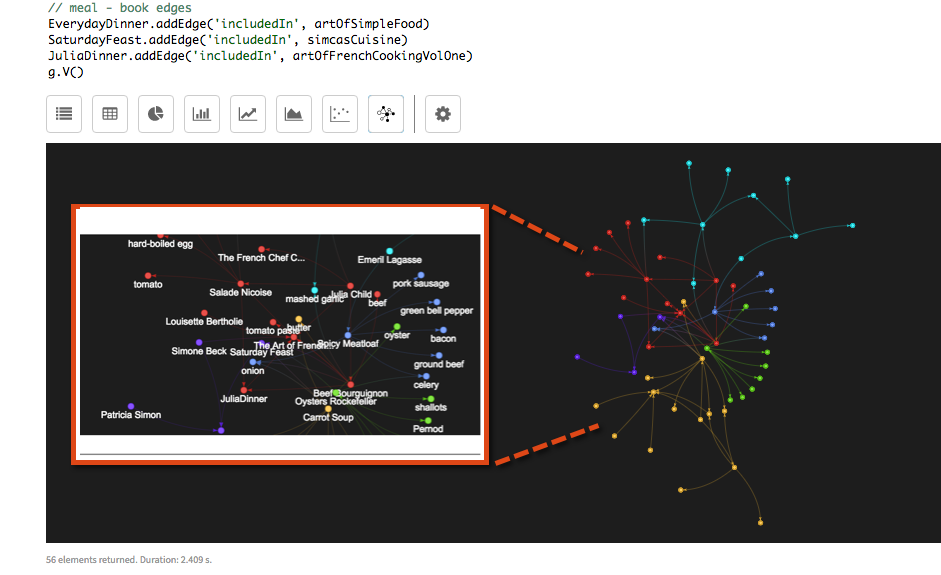
プロパティ
timestampは、 Cassandraの有効なtimestampデータ型に相当するTimestampデータ型です。スクリプトの最後にある
g.V()コマンドは、作成されたすべての頂点を表示します。 -
頂点カウントを実行すると、頂点のカウント数が56に増えます。頂点カウントを再実行します。
g.V().count()

データを投入するためのスクリプト記述には、DSE Graph Loaderが便利です。これは、データの投入にお勧めの方法です。
グラフ探索を使ってグラフを探索すると、興味深い結論に至る場合があります。
-
グラフ内に複数のauthor頂点がある場合に特定の頂点を見つけるには、具体的な
nameを指定してください。この探索では、Julia Childというnameを持つ(has)頂点について格納されている頂点情報が取得されます。また、この探索はhas句のauthor頂点による制約も受けます。g.V().has('author','name','Julia Child')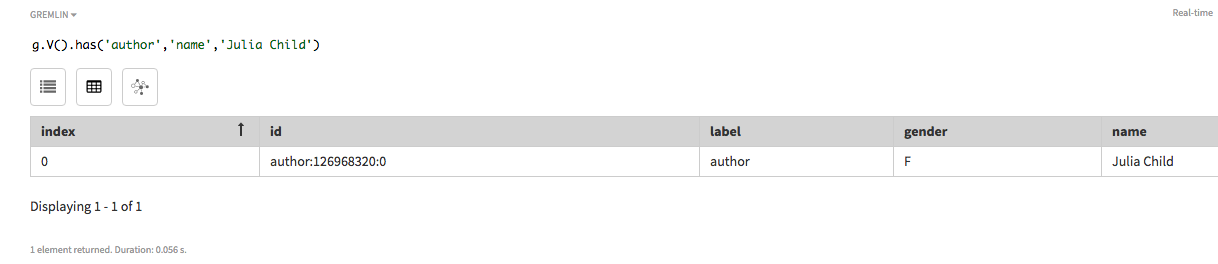
-
次の探索では、
has()は、name = Julia Childによってフィルターされた頂点情報を取得します。探索ステップoutE()は、authoredラベルを持つ頂点から発信される(外向き)辺を見つけます。g.V().has('name','Julia Child').outE('authored')DataStax Studioでは、Raw(原型)ビュー辺情報のリスト、
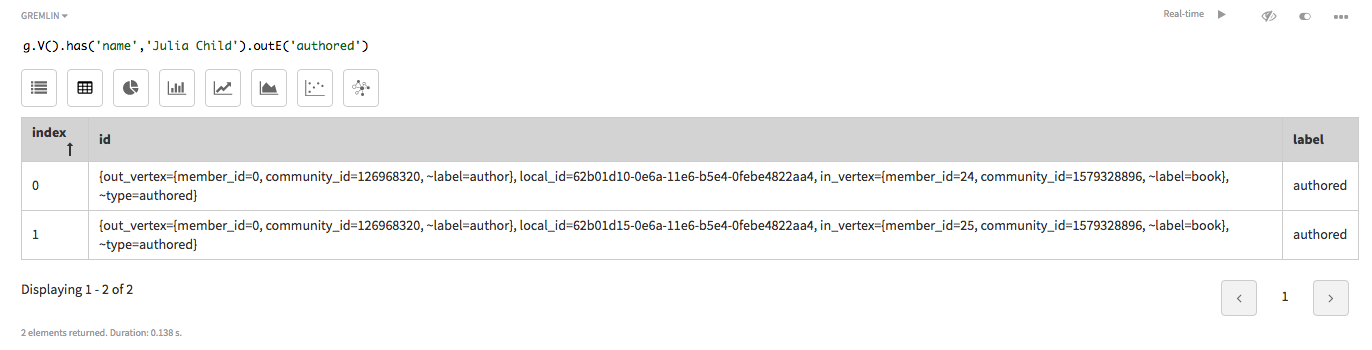
または、頂点を横切ると詳細情報が表示される、視覚化されたGraph(グラフ)ビューのグラフ。
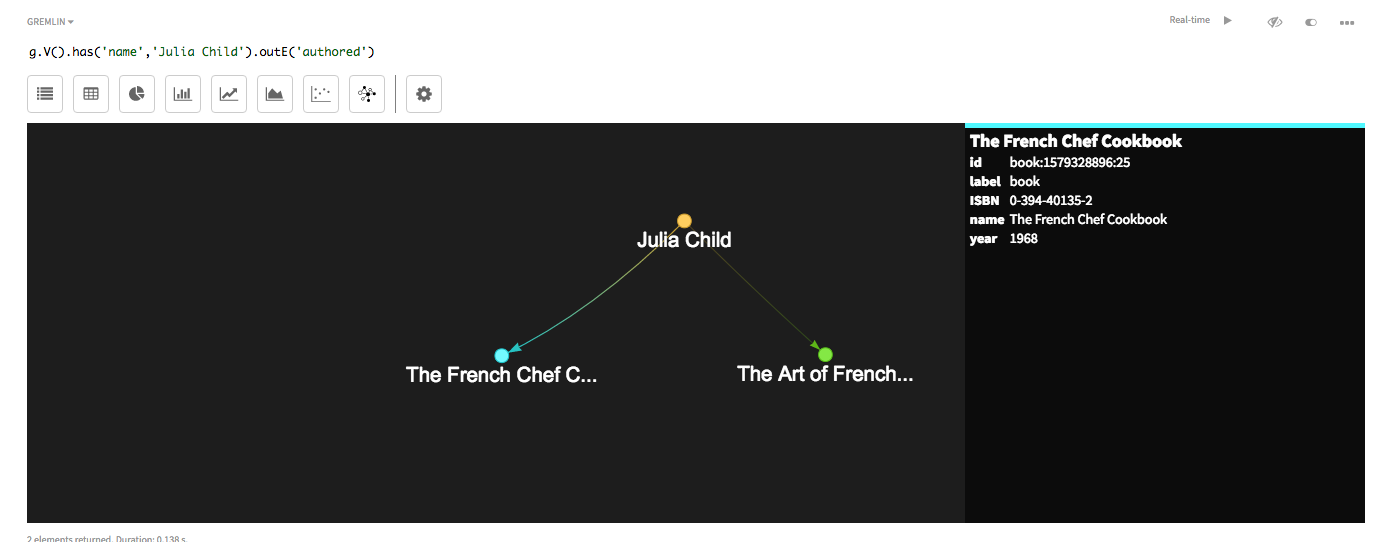
-
すべての著者が著した本に対してクエリーを実行する場合は、クエリーを変更する必要があります。前の例では辺を取得しましたが、隣接するbook頂点は取得しませんでした。探索ステップ
inV()を追加して、外向き辺に接続するすべての頂点を見つけ、さらにこれらの頂点の書名を出力します。探索ステップを連結して、V().outE().inV()を使用して頂点から外向きの辺を経由して隣接頂点に向かって移動しているところに注目してください。外向き辺には、具体的なフィルター値、authoredが割り当てられています。g.V().outE('authored').inV().values('name')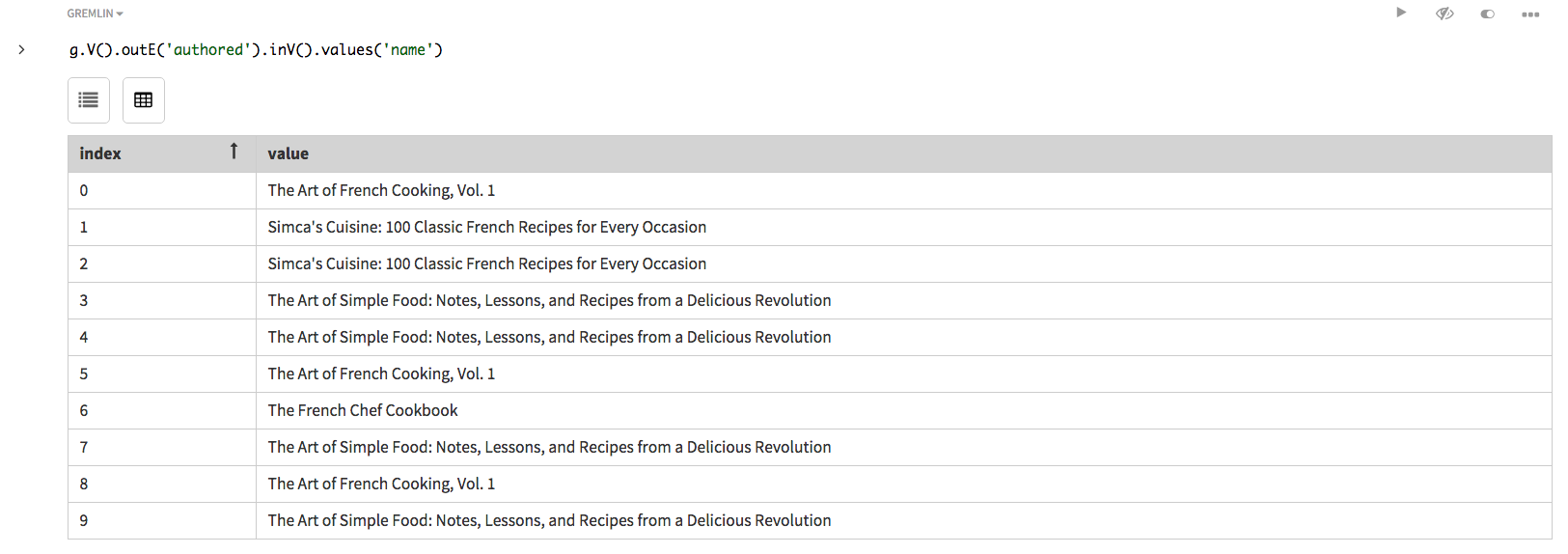
-
書名は、生成リストで重複して表示されます。これは、著者ごとにリストが返されるためです。本に3人の著者がある場合は、3つのリストが返されます。探索ステップ
dedup()は重複を排除できます。g.V().outE('authored').inV().values('name').dedup()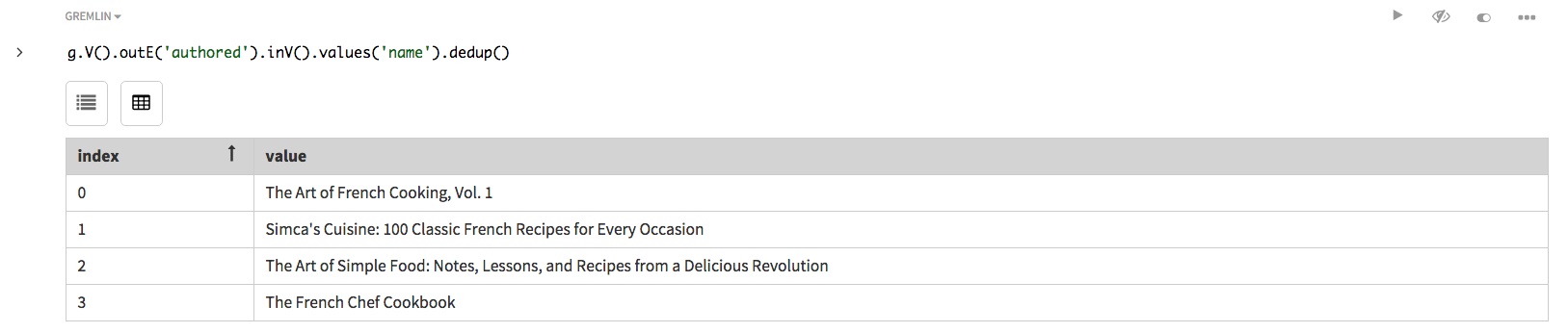
-
特定の著者について
has()ステップを再び挿入して探索を絞り込みます。Julia Childが著したすべての本を見つけます。g.V().has('name','Julia Child').outE('authored').inV().values('name')
-
前の例とこの例では、同じ結果が返されます。ただし、探索ステップの数と探索ステップのタイプがパフォーマンスに影響します。探索ステップ
outE()は、辺が明示的に必要な場合にのみ使用してください。この例では、辺を探索して接続されている頂点に関する情報を取得しますが、クエリーにとってこの辺情報は重要ではありません。g.V().has('name','Julia Child').out('authored').values('name')
探索ステップ
out()は、辺情報を取得せずに辺ラベルauthoredに基づいて接続しているbook頂点を取得します。大規模グラフの探索では、探索のこのような微妙な違いはレイテンシー問題に発展します。 -
探索ステップを追加するたびに、結果は微調整されていきます。別の連結された
has探索ステップを追加すると、Julia Childによって書かれ、1967年以降に出版された本のみ検出されます。この例では、gt、つまり、greater than(大なり)関数を使用しています。g.V().has('name','Julia Child').out('authored').has('year', gt(1967)).values('name')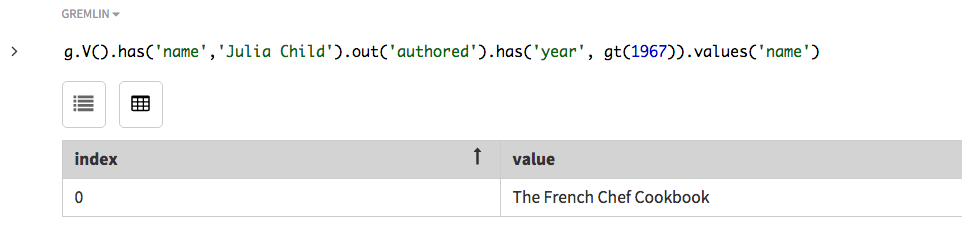
-
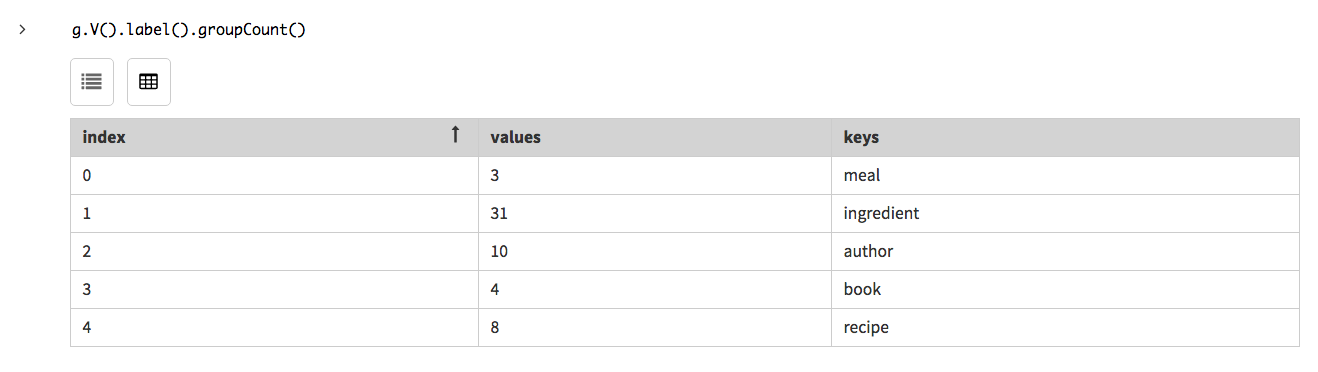
開発またはテスト時、各頂点ラベルを持つ頂点の数をチェックすると、そのデータが読み込まれたことを確認できます。頂点ラベルごとに頂点の数を見つけるには、探索ステップ
label()の後ろに探索ステップgroupCount()を続けたものを使用します。ステップgroupCount()は、前のステップで得られた結果を集計するのに便利です。g.V().label().groupCount()
-
情報を保存または交換するには、出力ファイルにデータを書き込みます。Gryoファイルは、データをDSE Graphにリロードできるバイナリー形式ファイルです。次のコマンドのグラフI/Oは、グラフ全体をファイルに書き込みます。
gryo()をgraphml()またはgraphson()で置き換えることによって、他のファイル形式に書き込むことができます。graph.io(gryo()).writeGraph("/tmp/recipe.gryo")
-
Gryoファイルを読み込むには、読み込みコマンドを使用します。
graph.io(gryo()).readGraph("/tmp/recipe.gryo")
次のタスク
おめでとうございます!これで、あなたは、DSE Graphを使用してデータ探索することができるようになりました。
探索に関する他の情報については、探索を使用したクエリーの作成を参照してください。さまざまなロード・オプションに関する情報については、DSE Graph Loaderまたは DSE Graphの使用を参照してください。