Weather Sensorデモの実行
Weather Sensorデモでは、さまざまな都市の多数の気象センサーに関する集計データに対してHiveクエリーとShark SQLクエリーを実行するのにかかる時間を比較します。
Weather Sensorデモを使用すると、さまざまな都市の多数の気象センサーに関する集計データに対してHiveクエリーとShark SQLクエリーを実行するのにかかる時間を比較できます。たとえば、温度や湿度などのさまざまなメトリクスを使用してレポートを表示し、日次ロールアップを取得できます。
カスタムのShark SQLクエリーやHiveクエリーは、さまざまなメトリクスや日付を使用して実行します。CQLテーブルをクエリーすることに加え、Shark SQLクエリーとHiveクエリーにかかる時間を、Cassandraファイル・システム(CFS)内のデータと比較します。
前提条件
デモを実行する前に、以下のソース・コードとツールがインストールされていることを確認します。
- Python 2.7
- DebianおよびUbuntu
$ sudo apt-get install python2.7-dev - RedHatまたはCentOS
$ sudo yum install python27 - Mac OS XにはPython 2.7がすでにインストールされています。
- DebianおよびUbuntu
- pip installer tool
- DebianおよびUbuntu
$ sudo apt-get install python-pip - RedHatまたはCentOS
$ sudo yum install python-pip - Mac OS X
$ sudo easy_install pip
- DebianおよびUbuntu
- libsasl2-devパッケージ
- DebianおよびUbuntu
sudo apt-get install libsasl2-dev
- DebianおよびUbuntu
- 必要なPythonパッケージ:
tarボール、またはGUI-no servicesオプションを使用してDatastax Enterpriseをインストールした場合は、PATH環境変数をDataStax Enterpriseインストールの/binディレクトリーに設定します。
export PATH=$PATH:install_location/bin以下が必要です:
DataStax Enterpriseの起動とデータのインポート
DataStax EnterpriseをSparkで起動し、その後で、気象センサー・データ・モデルのスキーマを作成するスクリプトを実行します。このスクリプトによって、CSVファイルからCassandra CQLテーブルへの集計データのインポートも行われます。このスクリプトでは、CSVファイルをCassandraファイル・システム内に配置するためにhadoop fsコマンドが使用されます。- DataStax EnterpriseをSparkモードで起動します。
- create-and-load CQLスクリプトをweather_sensors/resourcesディレクトリーで実行します。たとえば、Linuxでは以下のようにします。
$ cd install_location/demos/weather_sensors $ bin/create-and-loadスクリプトによってデータがCQLにインポートされ、ファイルがCFSにコピーされたことが、出力で確認されます。. . . 10 rows imported in 0.019 seconds. 2590 rows imported in 2.211 seconds. 76790 rows imported in 33.522 seconds. + echo 'Copy csv files to Hadoop...' Copy csv files to Hadoop... + dse hadoop fs -mkdir /datastax/demos/weather_sensors/
PATHを設定して、再試行してください。Spark SQL ThriftサーバーとHiveの起動
競合を防ぐため、Shark SQL Thriftサーバー・サービスとHiveサービスは特定のポートで起動します。これらのサービスの起動には、ローカル・ユーザー・アカウントを使用します。sudoは使用しないでください。
- Shark SQL Thriftサーバーをポート5588で起動します。Linuxでは、たとえば以下のように入力します。
$ cd install_location $ bin/dse start-spark-sql-thriftserver --hiveconf hive.server2.thrift.port=5588 - 新しいターミナルを開いて、DSEのHiveサービスをポート5587で起動します。
$ bin/dse hive --service hiveserver2 --hiveconf hive.server2.thrift.port=5587"The blist library is not available, so a pure python list-based set will,"という警告メッセージが表示される場合は、メッセージを無視してかまいません。
Webアプリの起動とデータのクエリー
- 別のターミナルを開いて、Webインターフェイスを制御するPythonサービスを起動します。
$ cd install_location/demos/weather_sensors $ python web/weather.py - ブラウザーを開いて、
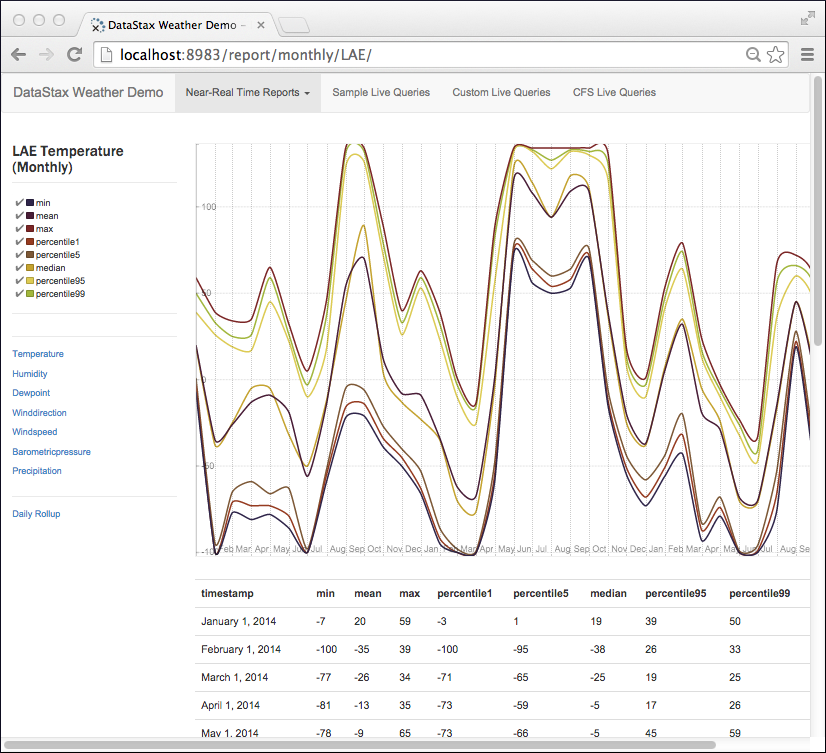
http://localhost:8983/というURLに移動します。気象センサー・アプリが表示されます。横方向のメニューで[Near Real-Time Reports]を選択します。気象観測ステーションのドロップダウン・リストが表示されます。

- ドロップダウンから気象観測ステーションを選択し、グラフを表示して、ページ左側の縦方向メニューからさまざまなメトリクスを選択します。
- 横方向のメニューで、[Sample Live Queries]をクリックして、サンプル・スクリプトを選択します。[Shark SQL]ボタンをクリックしてから[Submit]をクリックします。
Sparkを使用して結果を読み込むのにかかった時間が表示されます。

- [Hive]ボタンをクリックして、Hiveでの結果の読み込みにかかった時間を確認します。

- 縦方向のメニューから[Custom Live Queries]をクリックします。曜日、メトリクス(風向きなど)の順にクリックします。[Recalculate Query]をクリックします。選択内容がクエリーに反映されます。
- 縦方向のメニューから[CFS Live Queries]をクリックします。[Spark SQL]をクリックします。Shark SQLを使用してCFSから結果を読み込むのにかかった時間が表示されます。

クリーンアップ
生成されたデータをすべて削除するには、以下のコマンドを実行します。
$ cd install_location/demos/weather_sensors
$ bin/cleanup$ echo "DROP KEYSPACE weathercql;" | cqlsh