Mapping script
Regardless of the file format selected, the main body of the mapping script is the same. After setting configuration and adding a data input source, the mapping commands are specified.
-
Vertices are loaded from
authorInput, with the vertex labelauthorand the property keynamewhich uniquely identifies a vertex listed for thekey. Note that, in this example, ifgenderwere chosen for the key, it would not be unique enough to load each record from the data file. Using the configuration settingload_new: truecan significantly speed up the loading process, but a duplicate vertex will be created if the record already exists. All other property keys will be loaded, but do not have to be identified in the loading script. Forauthorvertices,genderwill also be loaded.load(authorInput).asVertices { label "author" key "name" }If more than 256 property key values are present in the input file, see important information on the
max_query_paramsvalue in thedse.yamlfile.One load statement must be created for each vertex loaded, even if the same file is reused for one or more vertices. When using the same input file for multiple vertices, sometimes a field exists in the input file that should be ignored for a particular vertex. See the instructions for ignoring a field. If an input file includes multiple types of lines, for instance,
authorsandreviewers, that should be read into different vertex labels, see the instructions forlabelField. -
Loading the book vertices follows a similar pattern. Note that both vertex labels
authorandbookusenameas the unique key for identifying a vertex. This declares that the vertex record does not yet exist in the graph at the beginning of the loading process.load(bookInput).asVertices { label "book" key "name" } -
After vertices are loaded, edges are loaded. Similar to the vertex mapping, an edge label is specified. In addition, the outgoing vertex (
outV) and incoming vertex (inV) for the edge must be identified. For each vertex inoutVorinV, the vertex label is specified withlabel, and the unique key is specified withkey.load(authorBookInput).asEdges { label "authored" outV "aname", { label "author" key "name" } inV "bname", { label "book" key "name" } }Note the naming convention used for the
outVandinVdesignations. Because both the outgoing vertex and the incoming vertex keys are listed asname, the designatorsanameandbnameare used to distinguish between the author name and the book name as the field names in the input file. -
An alternative to the definitions shown above is to specify the mapping logic with variables, and then list the load statements separately.
authorMapper = { label "author" key "name"} bookMapper = { label "book" key "name" } authorBookMapper = { label "authored" outV "aname", { label "author" key "name" } inV "bname", { label "book" key "name" } } load(authorInput).asVertices(authorMapper) load(bookInput).asVertices(bookMapper) load(authorBookInput).asEdges(authorBookMapper)
Ignoring a field in input file
If the input file includes a field that should be ignored for a particular vertex load, use ignore.
-
Create a map script that ignores the field
restaurant:// authorInput includes name, gender, and restaurant // but restaurant is not loaded /* Sample input: name|gender|restaurant Alice Waters|F|Chez Panisse */ load(authorInput).asVertices { label "author" key "name" ignore "restaurant" } -
An additional example shows the use of
ignorewhere two different types of vertices are created,bookandauthor, using the same input file./* Sample input: name|gender|bname Julia Child|F|The French Chef Cookbook Simone Beck|F|The Art of French Cooking, Vol. 1 */ //inputfiledir = '/tmp/TEXT/' authorInput = File.text("author.dat"). delimiter("|"). header('name', 'gender','bname') //Specifies what data source to load using which mapper (as defined inline) load(authorInput).asVertices { label "book" key "bname" ignore "name" ignore "gender" } load(authorInput).asVertices { label "author" key "name" outV "book", "authored", { label "book" key "bname" } }
Using labelField to parse input into different vertex labels
Oftentimes, an input file includes a field that is used to identify the vertex label.
In order to load the file and create different vertex labels on-the-fly, labelField is used to identify that particular field.
-
Create a map to input both authors and reviewers from the same file using
labelField:/* SAMPLE INPUT The input personInput includes type of person, name, gender; type can be either author or reviewer. type::name::gender author::Julia Child::F reviewer::Jane Doe::F */ personInput = File.text('people.dat'). delimiter("::"). header('type','name','gender') load(personInput).asVertices{ labelField "type" key "name" }Running this map script using the sample data results in two different vertex labels, with one record for each.
g.V().hasLabel('author').valueMap() {gender=[F], name=[Julia Child]} g.V().hasLabel('reviewer').valueMap() {gender=[F], name=[Jane Doe]}
Using compressed files to load data
Compressed files can be loaded using DSE Graph Loader to load both vertices and edges. This example loads vertices and edges, as well as edge properties, using gzipped files.
-
Create a map script that specifies the input files as compressed *.gz files:
/* SAMPLE INPUT rev_name|recipe_name|timestamp|stars|comment John Doe|Beef Bourguignon|2014-01-01|5|comment */ // CONFIGURATION // Configures the data loader to create the schema config create_schema: false, load_new: false // DATA INPUT // Define the data input source (a file which can be specified via command line arguments) // inputfiledir is the directory for the input files that is given in the commandline // as the "-filename" option inputfiledir = '/tmp/CSV/' // This next file is not required if the reviewers already exist reviewerInput = File.csv(inputfiledir + "reviewers.csv.gz"). gzip(). delimiter('|') // This next file is not required if the recipes already exist recipeInput = File.csv(inputfiledir +"recipes.csv.gz"). gzip(). delimiter('|') // This is the file that is used to create the edges with edge properties reviewerRatingInput = File.csv(inputfiledir + "reviewerRatings.csv.gz"). gzip(). delimiter('|') //Specifies what data source to load using which mapper (as defined inline) load(reviewerInput).asVertices { label "reviewer" key "name" } load(recipeInput).asVertices { label "recipe" key "name" } load(reviewerRatingInput).asEdges { label "rated" outV "rev_name", { label "reviewer" key "name" } inV "recipe_name", { label "recipe" key "name" } // properties are automatically added from the file, using the header line as property keys // from previously created schema }The compressed files are designated as
.gzfiles, followed by agzip()step for processing. Edge properties are loaded from one of the input files based on the header identifying the property keys to use for the values listed in each line of the CSV file. The edge properties populate aratededge between areviewervertex and arecipevertex with the propertiestimestamp,stars, andcomment.
Mapping data with a composite custom id
Data with a composite primary key requires some additional definition when specifying the key for loading, if the custom id uses multiple keys for definition (either partitionKeys and/or clusteringKeys).
-
Inserting data for vertices with a composite custom id requires the declaration of two or more keys:
/* SAMPLE INPUT cityId|sensorId|fridgeItem santaCruz|93c4ec9b-68ff-455e-8668-1056ebc3689f|asparagus */ load(fridgeItemInput).asVertices { label "fridgeSensor" // The vertexLabel schema for fridgeSensor includes two keys: // partition key: cityId and clustering key: sensorId key cityId: "cityId", sensorId: "sensorId" }The schema for the composite custom id must be created prior to using DSE Graph Loader, and cannot be inferred from the data. In addition, create a search index that includes all properties in the composite key. The search index is required to use DSE Graph Loader for inserting composite custom id data.
Check the vertex id results with
id()to retrieve the full primary key definition:gremlin> g.V().hasLabel('fridgeSensor').id() ==>{~label=fridgeSensor, sensorId=93c4ec9b-68ff-455e-8668-1056ebc3689f, cityId=santaCruz} ==>{~label=fridgeSensor, sensorId=9c23b683-1de2-4c97-a26a-277b3733732a, cityId=sacramento} ==>{~label=fridgeSensor, sensorId=eff4a8af-2b0d-4ba9-a063-c170130e2d84, cityId=sacramento}Each vertex stores
fridgeItemas data:gremlin> g.V().valueMap() ==>{fridgeItem=[asparagus]} ==>{fridgeItem=[ham]} ==>{fridgeItem=[eggs]} -
To load edges based on a composite key, a transformation is required:
/* SAMPLE EDGE DATA cityId|sensorId|name santaCruz|93c4ec9b-68ff-455e-8668-1056ebc3689f|asparagus */ the_edges = File.csv(inputfiledir + "fridgeItemEdges.csv").delimiter('|') the_edges = the_edges.transform { it['fridgeSensor'] = [ 'cityId' : it['cityId'], 'sensorId' : it['sensorId'] ]; it['ingredient'] = [ 'name' : it['name'] ]; it } load(the_edges).asEdges { label "contains" outV "ingredient", { label "ingredient" key "name" } inV "fridgeSensor", { label "fridgeSensor" key cityId:"cityId", sensorId:"sensorId" } }The edge file transforms the partition key and clustering key into a map of
cityIdandsensorId. This map can then be used to designate the key for afridgeSensorvertex when the edges are loaded.The resulting map shows the edges created between ingredient and fridgeSensor vertices.
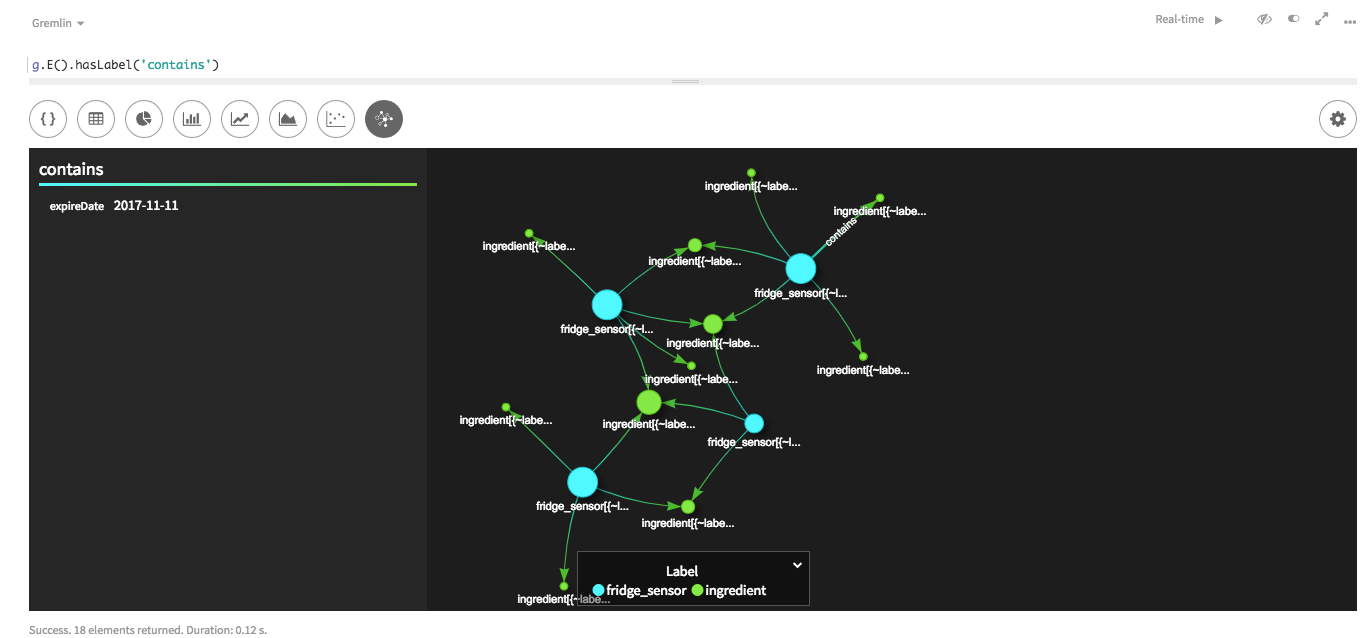
-
For DSE 5.1.3 and later, an alternative method of loading edge data from CSV files can be used:
/* SAMPLE EDGE DATA cityId|sensorId|homeId 100|001|9001 */ isLocatedAt_fridgeSensor = File.csv(/tmp/data/edges/" + "isLocatedAt_fridgeSensor.csv").delimiter('|') load(isLocatedAt_fridgeSensor).asEdges { label "isLocatedAt" outV { label "fridgeSensor" key cityId: "cityId", sensorId: "sensorId" exists() ignore "homeId" } inV { label "home" key "homeId" exists() ignore "cityId" ignore "sensorId" } ignore "cityId" ignore "sensorId" ignore "homeId" }In this example, no transform is required, but
ignorestatements are required in both theinVandoutVdeclarations, as well as the edge properties section. Removing theexists()statement in the incoming and outgoing vertex declarations can enable loading the vertices as well as the edges in this mapping script.There is a new subtle change in the
inVandoutVdeclarations. An input field name is no longer used, such asinV "home", {, due to the requirement to support multiple-key custom ids.The resulting map:
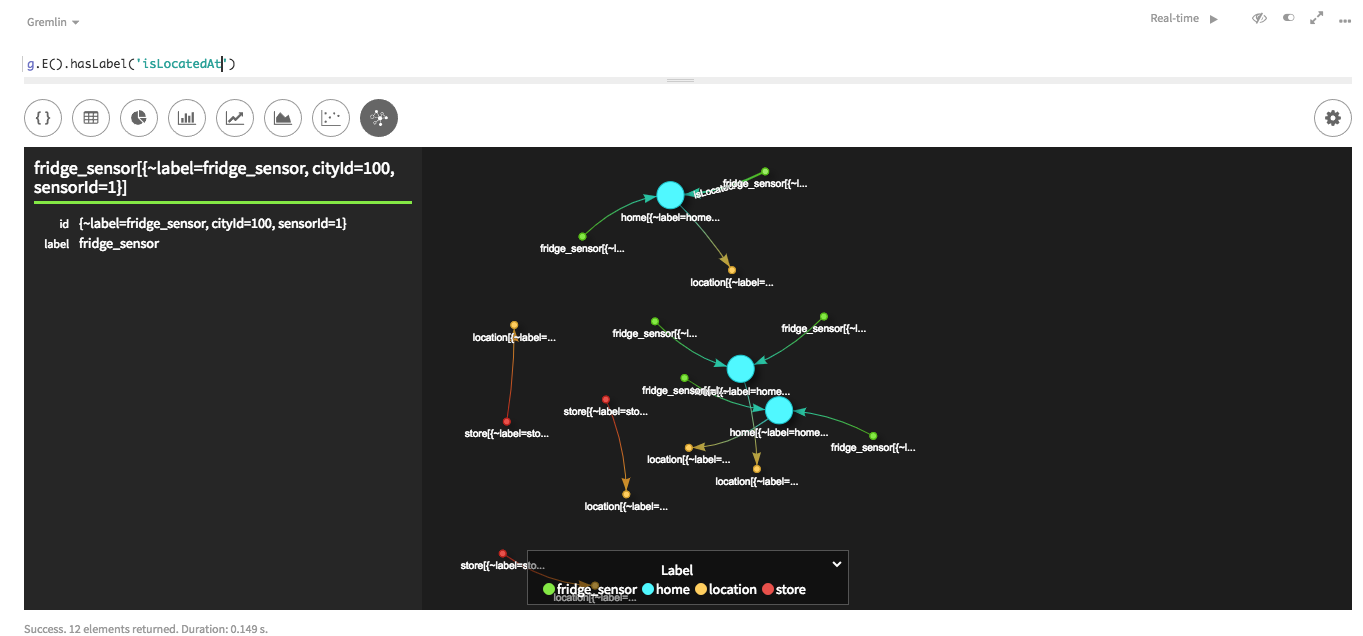
Mapping multi-cardinality edges
Multiple cardinality edges are a common type of data that is inserted into graphs. Often, the input file has both vertex and edge information for loading.
-
Inserting vertices and multi-cardinal edges can be accomplished from one file with judicious use of
ignorewhile loading vertices:/* SAMPLE INPUT authorCity: author|city|dateStart|dateEnd Julia Child|Paris|1961-01-01|1967-02-10 */ // CONFIGURATION // Configures the data loader to create the schema config dryrun: false, preparation: true, create_schema: false, load_new: true, schema_output: 'loader_output.txt' // DATA INPUT // Define the data input source (a file which can be specified via command line arguments) // inputfiledir is the directory for the input files inputfiledir = '/tmp/multiCard/' authorCityInput = File.csv(inputfiledir + "authorCity.csv").delimiter('|') //Specifies what data source to load using which mapper (as defined inline) // Ignore city, dateStart, and dateEnd when creating author vertices load(authorCityInput).asVertices { label "author" key "author" ignore "city" ignore "dateStart" ignore "dateEnd" } // Ignore author, dateStart, and dateEnd when creating city vertices load(authorCityInput).asVertices { label "city" key "city" ignore "author" ignore "dateStart" ignore "dateEnd" } // create edges from author -> city and include the edge properties dateStart and dateEnd load(authorCityInput).asEdges { label "livedIn" outV "author", { label "author" key "author" } inV "city", { label "city" key "city" } }
Mapping meta-properties
If the input file includes meta-properties, or properties that have properties, use vertexProperty.
The schema for this data load should be created prior to running graphloader
// PROPERTY KEYS
schema.propertyKey('name').Text().single().create()
schema.propertyKey('gender').Text().single().create()
schema.propertyKey('badge').Text().single().create()
schema.propertyKey('since').Int().single().create()
// Create the meta-property since on the property badge
schema.propertyKey('badge').properties('since').add()
// VERTEX LABELS
schema.vertexLabel('reviewer').properties('name','gender','badge').create()
// INDEXES
schema.vertexLabel('reviewer').index('byname').materialized().by('name').add()-
The mapping script uses
vertexPropertyto identifybadgeas a vertex property. Note the structure of the nested fields forbadgein the JSON file.* SAMPLE INPUT reviewer: { "name":"Jon Doe", "gender":"M", "badge" : { "value": "Gold Badge","since" : 2012 } } */ // CONFIGURATION // Configures the data loader to create the schema config dryrun: false, preparation: true, create_schema: true, load_new: true, load_vertex_threads: 3, schema_output: 'loader_output.txt' // DATA INPUT // Define the data input source (a file which can be specified via command line arguments) // inputfiledir is the directory for the input files inputfiledir = '/tmp/' reviewerInput = File.json(inputfiledir + "reviewer.json") //Specifies what data source to load using which mapper (as defined inline) load(reviewerInput).asVertices{ label "reviewer" key "name" vertexProperty "badge", { value "value" } }Running this mapping script using the sample data results in a
reviewervertex where the propertybadgehas a meta-propertysince.g.V().valueMap() {badge=[Gold Badge], gender=[M], name=[Jane Doe]} g.V().properties('badge').valueMap() {since=2012}
Mapping multiple meta-properties
If the input file includes multiple meta-properties, or properties that have multiple properties, use vertexProperty.
The schema for this data load should be created prior to running graphloader
// PROPERTY KEYS
schema.propertyKey('badge').Text().multiple().create()
schema.propertyKey('gender').Text().single().create()
schema.propertyKey('name').Text().single().create()
schema.propertyKey('since').Int().single().create()
// VERTEX LABELS
schema.vertexLabel('reviewer').properties('name', 'gender', 'badge').create()
schema.propertyKey('badge').properties('since').add()
// INDEXES
schema.vertexLabel('reviewer').index('byname').materialized().by('name').add()-
The mapping script uses
vertexPropertyto identifybadgeas a vertex property. Note the structure of the nested fields forbadgein the JSON file./* SAMPLE INPUT reviewer: { "name":"Jane Doe", "gender":"F", "badge" : [{ "value": "Gold Badge", "since" : 2012 }, { "value": "Silver Badge", "since" : 2005 }] } */ // CONFIGURATION // Configures the data loader to create the schema config dryrun: false, preparation: true, create_schema: false, load_new: true, load_vertex_threads: 3, schema_output: 'loader_output.txt' // DATA INPUT // Define the data input source (a file which can be specified via command line arguments) // inputfiledir is the directory for the input files inputfiledir = '/tmp/' reviewerInput = File.json(inputfiledir + "reviewerMultiMeta.json") //Specifies what data source to load using which mapper (as defined inline) load(reviewerInput).asVertices{ label "reviewer" key "name" vertexProperty "badge", { value "value" } }Optionally, the data can be loaded from a CSV file if a transform is used before loading:
/* SAMPLE INPUT name|gender|value|since Jane Doe|F|Gold Badge|2011 Jane Doe|F|Silver Badge|2005 Jon Doe|M|Gold Badge|2012 */ // CONFIGURATION // Configures the data loader to create the schema config dryrun: false, preparation: true, create_schema: false, load_new: true, load_vertex_threads: 3, schema_output: 'loader_output.txt' // DATA INPUT // Define the data input source (a file which can be specified via command line arguments) // inputfiledir is the directory for the input files inputfiledir = '/tmp/' reviewerInput = File.csv(inputfiledir + "reviewerMultiMeta.csv").delimiter('|') //Specifies what data source to load using which mapper (as defined inline) reviewerInput = reviewerInput.transform { badge1 = [ "value": it.remove("value"), "since": it.remove("since") ] it["badge"] = [badge1] it } load(reviewerInput).asVertices{ label "reviewer" key "name" vertexProperty "badge", { value "value" } }Running this mapping script using the sample data results in a
reviewervertex where the propertybadgehas multiple values.dglMapScript1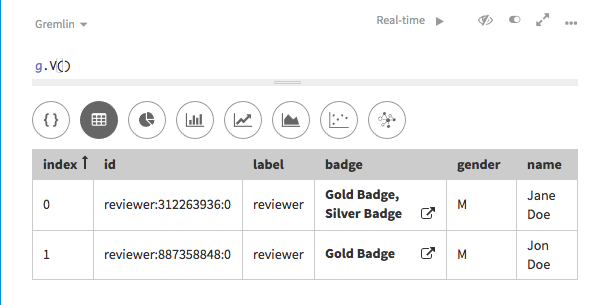
Choosing the pop-up link for
badgereveals the meta-property values:dglMapScript2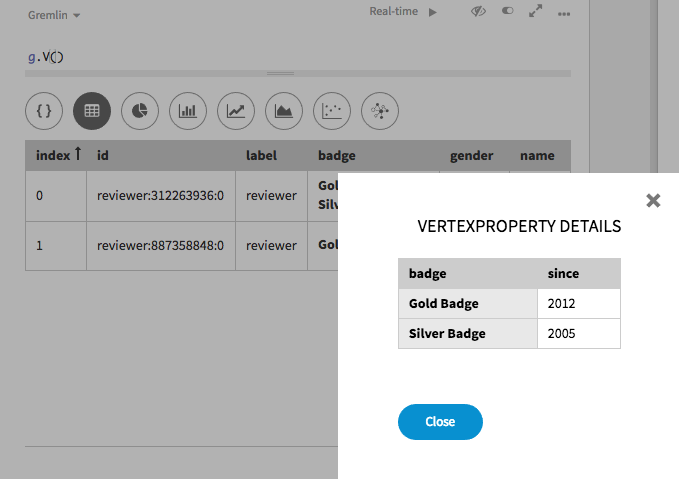
Mapping geospatial and Cartesian data
Geospatial and Cartesian data can be loaded with DSE Graph Loader.
The DSE Graph Loader is not capable of creating schema for geospatial and Cartesian data, so schema must be created before loading and the create_schema configuration must be set to false.
An example of geospatial schema for the example:
//SCHEMA
schema.propertyKey('name').Text().create()
schema.propertyKey('point').Point().withGeoBounds().create()
schema.vertexLabel('location').properties('name','point').create()
schema.propertyKey('line').Linestring().withGeoBounds().create()
schema.vertexLabel('lineLocation').properties('name','line').create()
schema.propertyKey('polygon').Polygon().withGeoBounds().create()
schema.vertexLabel('polyLocation').properties('name','polygon').create()
schema.vertexLabel('location').index('byname').materialized().by('name').add()
schema.vertexLabel('lineLocation').index('byname').materialized().by('name').add()
schema.vertexLabel('polyLocation').index('byname').materialized().by('name').add()
schema.vertexLabel('location').index('search').search().by('point').add()
schema.vertexLabel('lineLocation').index('search').search().by('line').add()
schema.vertexLabel('polyLocation').index('search).search().by('polygon').add()Search indexes must be used for geospatial and Cartesian points, linestrings or polygons in graph queries. DSE Graph uses one index per query, and because geospatial data consists of latitude and longitude (two parameters), only search indexes can be used to optimize query performance.
-
If desired, add configuration to the mapping script.
-
Specify the data input directory. The variable
inputfiledirspecifies the directory for the input files. Each of the identified files will be used for loading./* SAMPLE DATA name|point New York|POINT(74.0059 40.7128) Paris|POINT(2.3522 48.8566) */ // DATA INPUT // Define the data input source (a file which can be specified via command line arguments) // inputfiledir is the directory for the input files inputfiledir = '/tmp/geo_dgl/data/' ptsInput = File.csv(inputfiledir + "vertices/place.csv").delimiter('|') linesInput = File.csv(inputfiledir + "vertices/place_lines.csv").delimiter('|') polysInput = File.csv(inputfiledir + "vertices/place_polys.csv").delimiter('|') //Specifies what data source to load using which mapper (as defined inline) load(ptsInput).asVertices { label "location" key "name" } import com.datastax.driver.dse.geometry.Point ptsInput = ptsInput.transform { it['point'] = Point.fromWellKnownText(it['point']); return it; } load(linesInput).asVertices { label "lineLocation" key "name" } import com.datastax.driver.dse.geometry.LineString linesInput = linesInput.transform { it['line'] = LineString.fromWellKnownText(it['line']); return it; } load(polysInput).asVertices { label "polyLocation" key "name" } import com.datastax.driver.dse.geometry.Polygon polysInput = polysInput.transform { it['polygon'] = Polygon.fromWellKnownText(it['polygon']); return it; }A transformation of the input data is required, converting the point from the WKT format into the format DSE Graph stores. For a point, the transformation imports a Point library and uses the
fromWellKnownTextmethod:import com.datastax.driver.dse.geometry.Point ptsInput = ptsInput.transform { it['point'] = Point.fromWellKnownText(it['point']); return it; }Linestrings and polygons use the same library and method, respectively.
-
To run DSE Graph Loader for CSV loading from a directory, use the following command:
graphloader geoMap.groovy -graph testGeo -address localhost
Mapping Gryo data generated from DSE Graph
Inserting Gryo binary data requires a slightly modified map script.
To load Gryo data, allow DSE Graph Loader to create schema and load new data.
Loading will require a graph schema_mode set to Development.
-
Create a map script for DSE Graph generated Gryo input:
//Need to specify a keymap to show how to identify vertices vertexKeyMap = VertexKeyMap.with('meal','name').with('ingredient','name').with('author','name').with('book','name') .with('recipe','name').build(); inputfiledir = '/tmp/Gryo/' recipeInput = com.datastax.dsegraphloader.api.Graph.file(inputfiledir + 'recipesDSEG.gryo').gryo().dse() load(recipeInput.vertices()).asVertices { labelField '~label' key 'name' } load(recipeInput.edges()).asEdges { labelField '~label' outV 'outV', { labelField '~label' key 'name' : 'name', 'personId' : 'personId' } inV 'inV', { labelField '~label' key 'name' : 'name', 'bookId' : 'bookId' } }The Gryo data format will include
~labelandnamefield values that must be used to create the vertices. For instance, a record that is an author will have a~labelofpersonand propertyname. For the edges, notice that a custom vertex ID consisting of bothnameandbookIdis used to identify the vertex to use as the incoming vertex for the edge.
Mapping Gryo data generated with TinkerGraph
Inserting Gryo binary data requires a slightly modified map script.
To load Gryo data, allow DSE Graph Loader to create schema and load new data.
Loading will require a graph schema_mode set to Development.
-
Create a map script for TinkerGraph generated Gryo input:
//Specifies what data source to load using which mapper (as defined inline) load(recipeInput.vertices()).asVertices { labelField "~label" key "~id", "id" } load(recipeInput.edges()).asEdges { labelField "~label" outV "outV", { labelField "~label" key "~id", "id" } inV "inV", { labelField "~label" key "~id", "id" } }The Gryo data format will include
~labelandnamefield values that must be used to create the vertices and edges. For instance, a record that is an author will have a~labelofauthorand propertyname. ThevertexKeyMapcreates a map of each vertex label to a unique property. This map is used to create unique keys used while loading vertices from the binary file.
Mapping GraphML binary data
Inserting GraphML binary data requires a slightly modified map script.
To load GraphML data, allow DSE Graph Loader to create schema and load new data.
Loading will require a graph schema_modeset to Development.
-
Create a map script for GraphML data:
//Specifies what data source to load using which mapper (as defined inline) load(recipeInput.vertices()).asVertices { labelField "~label" key "~id", "id" } load(recipeInput.edges()).asEdges { labelField "~label" outV "outV", { labelField "~label" key "~id", "id" } inV "inV", { labelField "~label" key "~id", "id" } }The GraphML data format will include
~labeland~idfield values that must be used to create the label and key for each record loaded. For instance, a record that is an author will have a~labelofauthor. The~idwill similarly be set in the record, a difference from other data. The difference can be seen by looking at a record and noting the presence of theidfield, based on the second item in eachkeysetting in the mapping script:g.V().hasLabel('author').valueMap() {gender=[F], name=[Julia Child], id=[0]} {gender=[F], name=[Simone Beck], id=[3]}
Mapping GraphSON binary data
Inserting GraphSON data requires a slightly modified map script.
To load GraphSON data, allow DSE Graph Loader to create schema and load new data.
Loading will require a graph schema_modeset to Development.
-
Create a map script for GraphML data:
//Specifies what data source to load using which mapper (as defined inline) load(recipeInput.vertices()).asVertices { labelField "~label" key "~id", "id" } load(recipeInput.edges()).asEdges { labelField "~label" outV "outV", { labelField "~label" key "~id", "id" } inV "inV", { labelField "~label" key "~id", "id" } }The GraphSON data format will include
~labeland~idfield values that must be used to create the label and key for each record loaded. For instance, a record that is an author will have a~labelofauthor. The~idwill similarly be set in the record, a difference from other data. The difference can be seen by looking at a record and noting the presence of theidfield, based on the second item in eachkeysetting in the mapping script:g.V().hasLabel('author').valueMap() {gender=[F], name=[Julia Child], id=[0]} {gender=[F], name=[Simone Beck], id=[3]}
