Simple Traversals
Returning to the Food Graph, let’s consider some simple query traversals.
Exploring recipe ratings
What does John Doe, a reviewer, say about recipes?
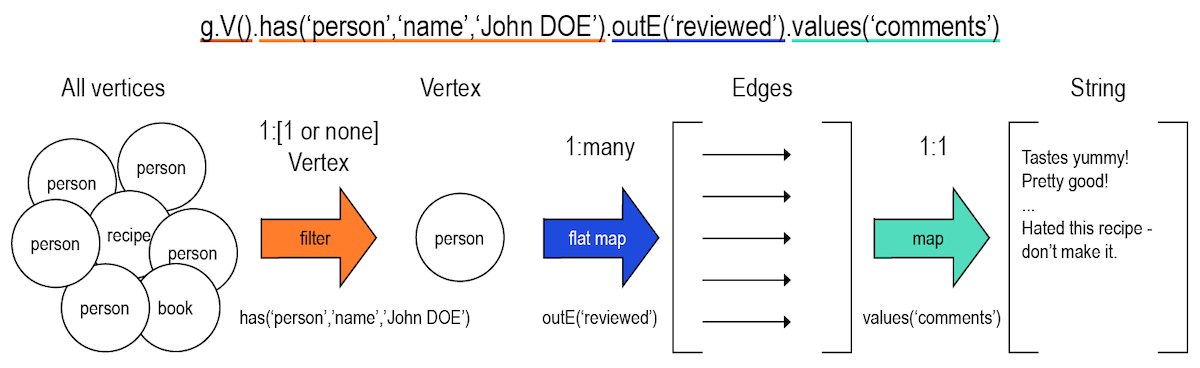
Use a query that identifies a vertex label as person with a name value of John Doe.
g.V().has('person', 'name','John DOE').outE('reviewed').values('comment')The use of the outgoing edges command outE('reviewed') to find all the recipes that John Doe has rated allows the value of the property comments to be retrieved:
==>Pretty tasty!
==>Really spicy - be careful!It might be nice to know which recipes John Doe reviewed, so another traversal can be created.
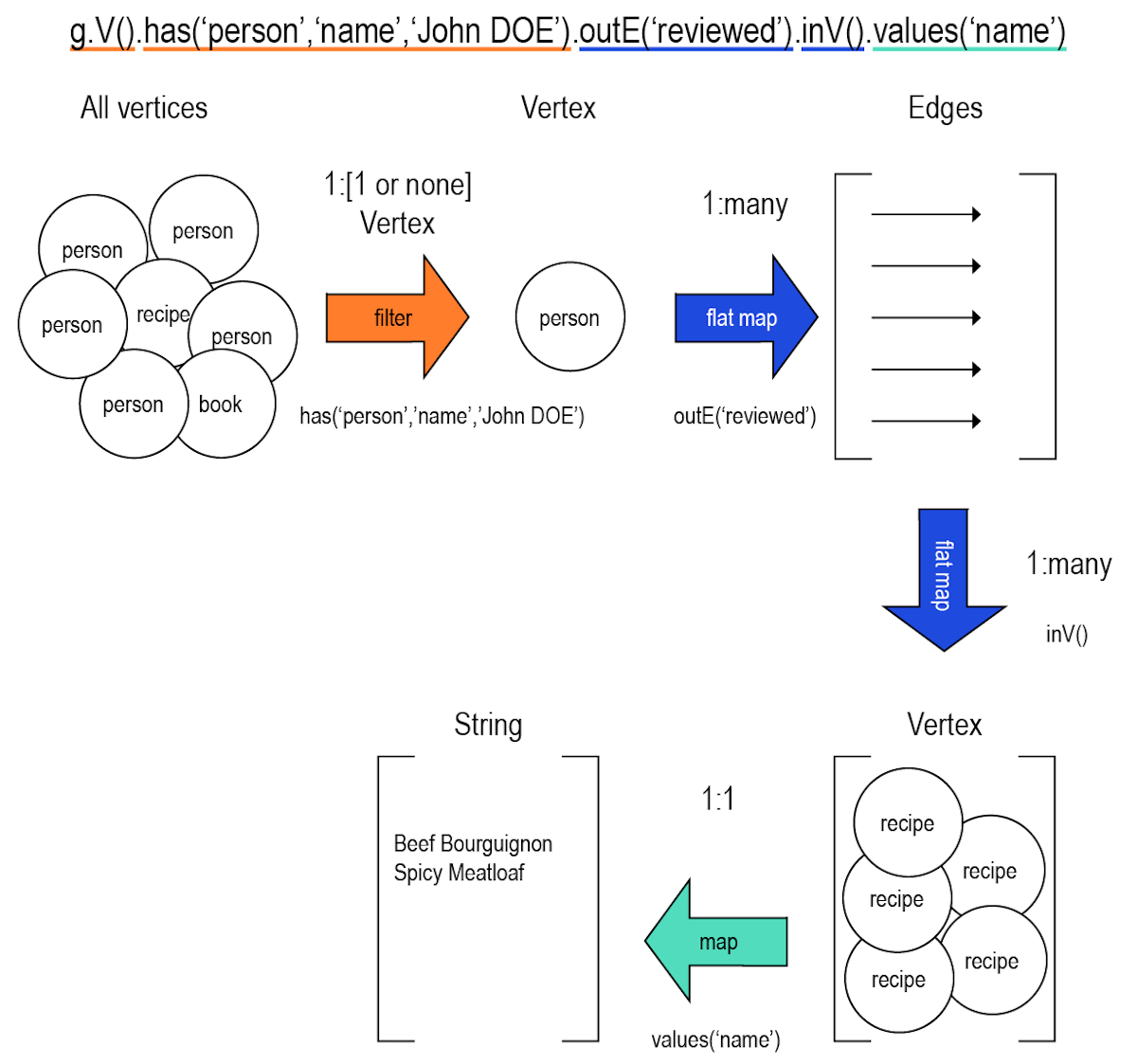
This query traverses from the comments to the recipes:
g.V().has('person', 'name','John DOE').outE('reviewed').inV().values('name')resulting in:
==>Beef Bourguignon
==>Spicy MeatloafThe use of inV() traverses to the incoming vertices that are connected to John DOE by reviewed edges.
Another reasonable question is ask is: What are all the reviews that give a recipe more than 3 stars?
Try a traversal using gt(3), or greater than 3 to filter the stars values:
g.E().hasLabel('reviewed').has('stars', gt(3)).valueMap()results in:
==>{year=2014-01-23, stars=4, time=12:00}
==>{year=2014-02-01, comment=Yummy!, stars=5, time=12:00}
==>{year=2015-12-30, comment=Loved this soup! Yummy vegetarian!, stars=5, time=12:00}
==>{year=2014-01-01, comment=Pretty tasty!, stars=5, time=12:00}
==>{year=2015-12-31, comment=Really spicy - be careful!, stars=4, time=12:00}The traversal shown finds each edge that is labeled reviewed and filters the edges found to output only those edges with a star rating of 4 or 5.
But this traversal doesn’t output the answer to the original question.
The traversal needs modification to get the incoming vertices with inV(), and to list those incoming vertices by name with values('name'):
g.E().hasLabel('reviewed').has('stars', gt(3)).inV().values('name')results in:
==>Carrot Soup
==>Spicy Meatloaf
==>Beef Bourguignon
==>Beef Bourguignon
==>Beef BourguignonThe results indicate that Beef Bourguignon has been reviewed three times, although we don’t have any reviewer information, just duplication of the recipe title in the list.
Returning to the previous query, let’s look for more recent reviews.
Adding an additional traversal step to filter by the time can find the 4 and 5 star ratings using gte(4) or greater than or equal to 4, with a review date of Jan 1, 2015 or later.
g.E().hasLabel('reviewed').
has('stars',gte(4)).
has('year', gte('2015-01-01' as LocalDate)).
has('time', '00:00:00' as LocalTime).
valuesMap()results in:
==>[comment:Loved this soup! Yummy vegetarian!, timestamp:2015-12-30T00:00:00Z, stars:5]
==>[comment:Really spicy - be careful!, timestamp:2015-12-31T00:00:00Z, stars:4]Chaining traversal steps together can yield very exacting results.
For instance, if we added the inV().values('name') to the last query, we’d now refine the results to find all 4-5 star reviews since the beginning of the year 2015.
Turning in another direction with queries, let’s take a look at using statistical functions.
For instance, what is the mean value of all the recipe ratings?
g.E().hasLabel('reviewed').values('stars').mean()results in:
==>4.142857142857143The results show that the reviewers like the recipes they reviewed (high mean), and establishes that reviewers in this sample did not write reviews for recipes that they did not like.
Perhaps a prolific reviewer would have a wider range of reviews. Find the maximum number of reviews that a single reviewer has written.
g.V().hasLabel('person').map(outE('reviewed').count()).max()results in:
==>2This traversal maps all the outgoing 'reviewededges of each reviewer and counts them, then determines which count has the highest value using max().
The map() step allows the process to be done for each reviewer.
Another measure that can be investigated is the mean rating of each reviewer. This traversal query uses a number of Apache TinkerPop™ traversal steps.
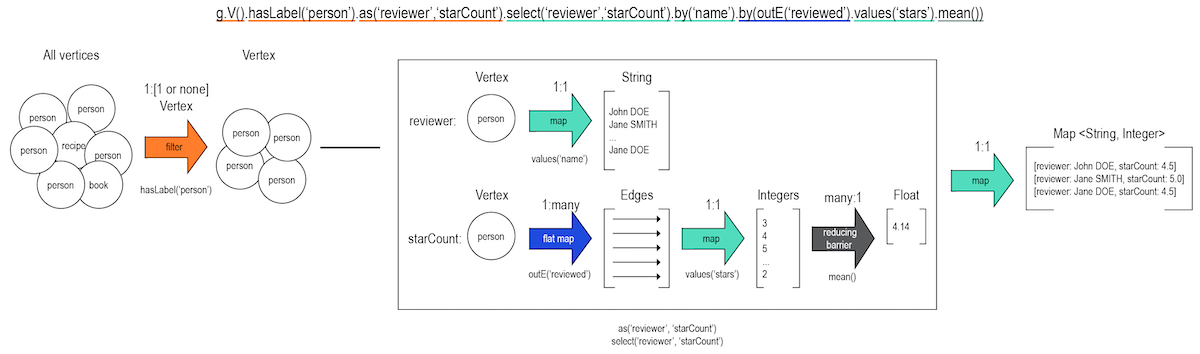
The as() step allows display labels to be created for the two items that will be lists, the reviewer’s name and the mean stars value for each reviewer.
These display labels, reviewer and starCount are then used in a select() step that gets each value, first the reviewer’s name using by('name')and then the starCount using by(outE('reviewed').values('stars').mean().
The select() step checks each reviewer vertex and then traverses to discover the associated starCount value.
g.V().hasLabel('person').where(out('reviewed')).as('reviewer','starCount').
select('reviewer','starCount').
by('name').
by(outE('reviewed').values('stars').mean())results in:
==>{reviewer=John Smith, starCount=4.0}
==>{reviewer=Jane DOE, starCount=5.0}
==>{reviewer=Sharon SMITH, starCount=3.0}
==>{reviewer=John DOE, starCount=4.5}Notice that people who have not reviewed any recipes are not included in the results.
The key to excluding non-reviewers is the where(out('reviewed')) that filters and continues the traversal with only the people who have reviewed edges to recipes.
Ordering the results by the starCount, or mean star rating, can allow the highest rater and the lowest rater to be discovered.
Here, the traversal steps order().by(select('starCount').decr() uses the output of the select('starCount') step to order the display in decremental order.
g.V().hasLabel('person').where(out('reviewed')).as('reviewer','starCount').
select('reviewer','starCount').
by('name').
by(outE('reviewed').values('stars').mean()).
order().by(select('starCount'), decr)results in:
==>{reviewer=Jane DOE, starCount=5.0}
==>{reviewer=John DOE, starCount=4.5}
==>{reviewer=John Smith, starCount=4.0}
==>{reviewer=Sharon SMITH, starCount=3.0}If we were interested in only returning the highest rater, we could add a traversal step limit(1)to the traversal and get the highest rater, Jane DOE.
Suppose we want a list of all people, whether or not they have reviewed a recipe?
A tricky traversal step, coalesce(), is used to allow zero values by setting any missing stars values to a constant of zero:
g.V().hasLabel('person').as('reviewer','starCount').
select('reviewer','starCount').
by('name').
by(coalesce(outE('reviewed').values('stars'),constant(0)).mean()).
order().by(select('starCount'), decr)results in:
==>{reviewer=Jane DOE, starCount=5.0}
==>{reviewer=John DOE, starCount=4.5}
==>{reviewer=John Smith, starCount=4.0}
==>{reviewer=Sharon SMITH, starCount=3.0}
==>{reviewer=James BEARD, starCount=0.0}
==>{reviewer=Fritz STREIFF, starCount=0.0}
==>{reviewer=Kelsie KERR, starCount=0.0}
==>{reviewer=Alice WATERS, starCount=0.0}
==>{reviewer=Simone BECK, starCount=0.0}
==>{reviewer=Julia CHILD, starCount=0.0}
==>{reviewer=Louisette BERTHOLIE, starCount=0.0}
==>{reviewer=Emeril LAGASSE, starCount=0.0}
==>{reviewer=Betsy JONES, starCount=0.0}
==>{reviewer=Patricia CURTAN, starCount=0.0}
==>{reviewer=Patricia SIMON, starCount=0.0}All people who have not reviewed recipe have starCount=0.0.
Note that the where() step was omitted from this query, to capture all person information.
Let’s step back a bit and find the star rating each valud reviewer has given to recipes:
g.V().hasLabel('person').where(out('reviewed')).as('reviewer','rating').
out().as('recipe').
select('reviewer','rating','recipe').
by('name').
by(outE('reviewed').values('stars')).
by(values('name'))results in:
==>{reviewer=Jane DOE, rating=5, recipe=Beef Bourguignon}
==>{reviewer=Jane DOE, rating=5, recipe=Carrot Soup}
==>{reviewer=Sharon SMITH, rating=3, recipe=Beef Bourguignon}
==>{reviewer=Sharon SMITH, rating=3, recipe=Spicy Meatloaf}
==>{reviewer=John Smith, rating=4, recipe=Beef Bourguignon}
==>{reviewer=John DOE, rating=5, recipe=Beef Bourguignon}
==>{reviewer=John DOE, rating=5, recipe=Spicy Meatloaf}Note how the recipe name is traversed with out() and named with the step modulator as('recipe') after the reviewer and rating are labeled from the reviewer vertices with as('reviewer','rating').
Also, look at the versatility of the select()...by() combination to get values from both vertex and edge properties.
In general, the most interesting question answers how many people rated a particular recipe, and what the mean rating is for that particular recipe.Most people looking to discover recipes they want to make are looking for popular, well-rated recipes.
The graph traversal starts from a recipe vertex this time, and retrieves the recipe name, the number of reviews by counting the incoming edges with inE('reivewed').count(), and the mean value of the incoming edges with inE('reviewed').values('stars').mean().
g.V().hasLabel('recipe').where(inE('reviewed')).as('recipe','numberOfReviews','meanRating').
select('recipe','numberOfReviews','meanRating').
by('name').
by(inE('reviewed').count()).
by(inE('reviewed').values('stars').mean())results in:
==>{recipe=Spicy Meatloaf, numberOfReviews=2, meanRating=3.5}
==>{recipe=Carrot Soup, numberOfReviews=1, meanRating=5.0}
==>{recipe=Beef Bourguignon, numberOfReviews=4, meanRating=4.25}Looking at the results, we see that Carrot Soup has the highest mean rating, but only one review.
Beef Bourguignon, on the other hand, has a pretty high rating and a larger number of reviews.
Note that we could modify this query to find all recipes, even if the number of reviews are zero by including the coalesce() step used in an earlier query on this page.
Searching recipes
A common query for recipes is finding recipes that contain a certain ingredient:
g.V().hasLabel('recipe').
out().has('name','beef').
in().hasLabel('recipe').
values('name')results in:
==>Beef BourguignonA modification allows a query that includes either one ingredient or another:
g.V().hasLabel('recipe').
out().has('name',within('beef','carrots')).
in().hasLabel('recipe').
values('name')results in:
==>Beef Bourguignon
==>Carrot SoupFinding all the ingredients for a particular recipe is a common query:
g.V().
match(
__.as('a').hasLabel('ingredient'),
__.as('a').in('includes').has('name','Beef Bourguignon')).
select('a').
by('name').
fold()results in:
==>[butter, mashed garlic, onion, tomato paste, beef]This query uses a match() step to find a match for the ingredients used to make Beef Bourguignon.
The traversal starts by filtering all vertices to find the ingredients, then traverses to the recipe vertices along the includes edges using in('includes').
This query also uses a Groovy double underscore variable as a private variable for the match method.
The fold() step is used to put all the whole shopping list of ingredients into a single array.
Although inside() is most commonly used for geospatial searches, the method can be used to find anything that falls within a particular range of values.
An example is finding books that have a publishing date between 1960 and 1970 (represented by integers):
g.V().has('book', 'publish_year', inside(1960, 1970)).valueMap()results in:
==>{publish_year=[1961], name=[The Art of French Cooking, Vol. 1], book_id=[1001], category=[[French, cooking, general]]}
==>{publish_year=[1968], isbn=[0-394-40135-2], name=[The French Chef Cookbook], book_id=[1003], category=[[French, cooking]], book_discount=[10%]}This is useful to discover any records within a range of values.
Grouping output
Group output from a graph traversal using the group() traversal step.
For example, display all the vertices by name, grouped by vertex label:
g.V().group().by(label).by('name')results in:
The property does not exist as the key has no associated value for the provided element:
v[dseg:/fridge_sensor/45/300/66665/1]:nameWait - why did this query get an error?
Looking at the error message, there is at least one vertex label that doesn’t use the property name.
How can this query be modified?
It is possible to get all vertex labels that do not include name using the without() step:
g.V().hasLabel(without('fridge_sensor', 'meal')).
group().by(label).by('name').
unfold()results in:
==>meal_item=[taco, iced tea, burrito]
==>ingredient=[celery, carrots, butter, mashed garlic, egg noodles, fennel, thyme, ground beef, onion, tomato paste, eggplant, beef, pork loin, olive oil, yellow onion, tuna, mushrooms, oyster, tomato, Pernod, green beans, shallots, red wine, green bell pepper, pork sausage, parsley, hard-boiled egg, chervil, bacon, zucchini, chicken broth]
==>person=[James BEARD, Fritz STREIFF, John Smith, Kelsie KERR, Jane DOE, Sharon SMITH, Alice WATERS, Simone BECK, Julia CHILD, Louisette BERTHOLIE, Emeril LAGASSE, Betsy JONES, Patricia CURTAN, Patricia SIMON, John DOE]
==>book=[The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution, The Art of French Cooking, Vol. 1, The French Chef Cookbook, Simca's Cuisine: 100 Classic French Recipes for Every Occasion]
==>recipe=[Salade Nicoise, Spicy Meatloaf, Oysters Rockefeller, Carrot Soup, Beef Bourguignon, Rataouille, Wild Mushroom Stroganoff, Roast Pork Loin]
==>location=[Dublin, London, Jane's house, New York, Los Angeles, New Orleans, Zippy Mart, Tokyo, Paris, Mamma's Grocery, test location, Quik Station, Aachen, John Smith's place, Mary's house, Chicago]
==>store=[Zippy Mart, Quik Station, Mamma's Grocery]
==>home=[Jane's house, John Smith's place, Mary's house]While two of the vertex labels are not included, the rest are displayed nicely, with the different vertex types grouped together.
We could get all the vertex label information, including the fridge sensors and meals by deleting the by('name') step.
However, the resulting data will display the vertex ids, a less readable result.
Try to see that you get!
Similarly, you can group by edge label, replacing V() with E(), but edge labels rarely have names, and the resulting return can be useful but messy to read.
Another example groups all books by publishing year and displays a listing of each year books were published followed by the book titles:
g.V().hasLabel('book').
group().
by('publish_year').
by('name').
unfold()results in:
==>1968=[The French Chef Cookbook]
==>1972=[Simca's Cuisine: 100 Classic French Recipes for Every Occasion]
==>2007=[The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution]
==>1961=[The Art of French Cooking, Vol. 1]Grouping for processing using local()
Oftentimes, it is critical to do local processing for a particular step in the graph traversal.
The next two examples use the limit() command to show how local() can change the processing from the whole stream entering the query to a portion of the query.
First, find just two authors and the year that they have published books:
g.V().hasLabel('person').as('author').
out('authored').properties('publish_year').as('year').
select('author','year').
by('name').
by().
limit(2)results in:
==>{author=Fritz STREIFF, year=vp[publish_year->2007]}
==>{author=Julia CHILD, year=vp[publish_year->1961]}This query returns the first two records in the database.
Using local(), change this query to find the first two books that each author in the graph has published:
g.V().hasLabel('person').as('author').
local(out('authored').properties('publish_year').as('year').limit(2)).
select('author','year').
by('name').
by()results in:
==>{author=Fritz STREIFF, year=vp[publish_year->2007]}
==>{author=Kelsie KERR, year=vp[publish_year->2007]}
==>{author=Alice WATERS, year=vp[publish_year->2007]}
==>{author=Simone BECK, year=vp[publish_year->1961]}
==>{author=Simone BECK, year=vp[publish_year->1972]}
==>{author=Julia CHILD, year=vp[publish_year->1961]}
==>{author=Julia CHILD, year=vp[publish_year->1968]}
==>{author=Patricia CURTAN, year=vp[publish_year->2007]}
==>{author=Patricia SIMON, year=vp[publish_year->1972]}Note that up to two books are displayed for each author.
The traversal step local() has many applications for processing a subsection of a graph within a graph traversal to return results before moving on to further processing.
User-defined type (UDT) retrieval without search indexes
UDTs fields can be retrieved with queries, but not modified.
Using unfold() allows the UDTs to be traversed but not mutated.
For the schema for two UDTs plus a vertex label that uses them:
schema.type('address').
ifNotExists().
property('address1', Text).
property('address2', Text).
property('city_code', Text).
property('state_code', Text).
property('zip_code', Text).
create()
schema.type('location_details').
ifNotExists().
property('loc_address', frozen(typeOf('address'))).
property('telephone', listOf(Text)).
create()
schema.vertexLabel('location').
ifNotExists().
partitionBy('loc_id', Text).
property('name', Text).
property('loc_details', frozen(typeOf('location_details'))).
property('geo_point', Point).
create()Insert the following data:
g.addV('location').
property('loc_id', 'g13').
property('name', 'Zippy Mart').
property('loc_details', [ loc_address: [address1:'213 F St', city_code:'Winston', state_code:'CA', zip_code:'93001'] as address, telephone: ['530-555-3455', '916-446-2211'] ] as location_details).
property('geo_point', 'POINT(37.880727 -122.27003)' as Point).
iterate();
g.addV('location').
property('loc_id', 'g14').
property('name', 'Quik Station').
property('loc_details', [ loc_address: [address1:'500 C St', city_code:'Winston', state_code:'CA', zip_code:'93001'] as address, telephone: ['530-555-3454', '916-446-1111'] ] as location_details).
property('geo_point', 'POINT(37.871695 -122.273304)' as Point).
iterate();
g.addV('location').
property('loc_id', 'g15').
property('name', "Mamma's Grocery").
property('loc_details', [ loc_address: [address1:'1000 A St', city_code:'Winston', state_code:'CA', zip_code:'93001'] as address, telephone: ['530-555-1212', '916-444-3454'] ] as location_details).
property('geo_point', 'POINT(37.882641 -122.306542)' as Point).
iterate();
Using values(), query to find the locations, ordered by the city_code value :
g.V().hasLabel('location').
values('loc_details').
values('loc_address').
order().by(values('city_code'))results in:
==>{address1:'757 Jay St',address2:NULL,city_code:'Arbuckle',state_code:'CA',zip_code:'95691'}
==>{address1:'213 F St',address2:NULL,city_code:'Winston',state_code:'CA',zip_code:'93001'}
==>{address1:'1000 A St',address2:NULL,city_code:'Winston',state_code:'CA',zip_code:'93001'}
==>{address1:'500 C St',address2:NULL,city_code:'Winston',state_code:'CA',zip_code:'93001'}Using values() along with unfold() query will instead, retrieve only the city_code values:
g.V().hasLabel('location').
values('loc_details').
unfold().
values('loc_address').
values('city_code')results in:
==>Winston
==>Winston
==>Winston
==>Arbuckle