Data maintenance through compaction
When processing writes, DataStax Enterprise (DSE) stores data on disk in immutable files called SSTables.
Because the database cannot edit existing SSTables, new writes are always written to new SSTables, regardless of the contents of existing SSTables. Over time, the SSTables can accumulate multiple versions of the same row, and partitions can be stored across multiple SSTables. The number of SSTables directly impacts read request latency because the database must access multiple files to retrieve a complete row.
To prevent unbounded SSTable growth and maintain read performance, the database periodically merges SSTables into fewer files by reconciling the writes and discarding redundant data. This process is called compaction.
To maintain data integrity during reads and compaction, all SSTable writes are timestamped, and deletes are marked with tombstones. This means the database can determine the most recent write, and deleted data is removed in a consistent and deliberate way.
How compaction works
Compaction runs on multiple SSTables. From these SSTables, compaction finds all versions of each uniquely identified row, and then assembles a complete, unified version of each row. Redundant mutations are resolved using the most recent write timestamp for each of the row’s columns.
The merge process is performant because rows are sorted by partition key within each SSTable and the merge process does not use random I/O.
The new version of each row is written to a new SSTable. The old versions, along with any rows that are ready for deletion, are left in the old SSTables, and are deleted when any pending reads are completed.
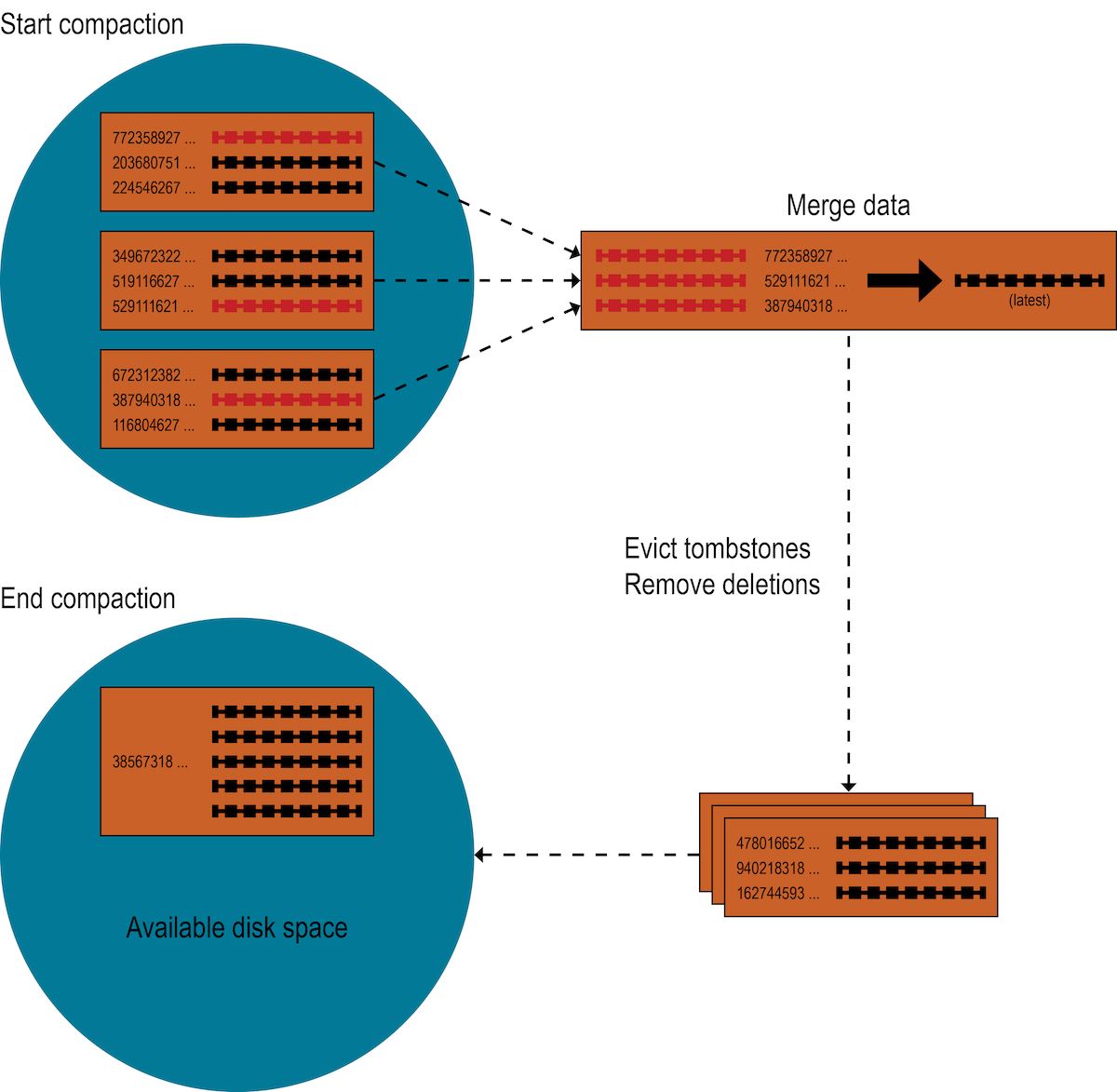
Compaction causes a temporary spike in disk space usage and disk I/O while old and new SSTables co-exist. As it completes, compaction frees up disk space occupied by old SSTables. It improves read performance by incrementally replacing old SSTables with compacted SSTables. The database can read data directly from the new SSTable even before it finishes writing, instead of waiting for the entire compaction process to finish.
DSE provides predictable high performance even under heavy load by replacing old SSTables with new ones in memory as it processes writes and reads. Caching the new SSTable, while directing reads away from the old one, is incremental and doesn’t cause a performance degradation event known as a dramatic cache miss storm.
Routine compaction maintenance on a per-table level is considered minor compaction.
When compaction runs on all tables in a keyspace, this is considered major compaction.
Major compactions can be extremely resource intensive and degrade performance if they run during peak periods.
Typically, a major compaction requires a specific triggering event, such as manually running nodetool compact.
Compaction strategies
Compaction strategies determine which SSTables are chosen for compaction and how the compacted rows are sorted into new SSTables.
DSE supports several compaction strategies. The ideal strategy depends on your data model, workloads, and tolerances for read and write amplification:
-
Read amplification: A determinant of database performance related to the number of SSTables that must be consulted to fulfill a read request. More SSTables generally means increased read amplification and increased read request latency.
-
Write amplification: A determinant of database performance, particularly during compaction, based on the number of times a piece of data must be rewritten during its lifetime.
UnifiedCompactionStrategy (UCS)
This strategy requires DSE 6.8.25 or later.
UnifiedCompactionStrategy (UCS) combines and builds on SizeTieredCompactionStrategy (STCS) and LeveledCompactionStrategy (LCS). Use this strategy for precise compaction behavior based on the table’s tolerance for read amplification and write amplification.
|
UCS is recommended for all workloads, including some time series and expiring TTL workloads. However, it isn’t designed as a complete replacement for TimeWindowCompactionStrategy (TWCS). If time series data is a concern, DataStax recommends that you compare UCS and TWCS before creating your tables. This is because TWCS must be enabled when you create a table. You cannot apply TWCS retroactively to existing tables that weren’t created with the proper time windowing layout. |
- Advantages
-
-
Useful for all workloads, especially clusters with vertically scaled nodes.
-
Uses sharding for independent, parallel compactions.
-
Configurable modes for preferred performance (low read amplification, low write amplification, or balanced) with tunable scaling factors and support for different modes at different SSTable hierarchy levels.
-
Dynamic reconfiguration with minimal recompaction for real-time adaptation to workload changes.
-
Lower disk space overhead compared to other strategies.
-
Stateless.
-
Good replacement for underperforming legacy compaction strategies when upgrading from an earlier version of DSE or Cassandra.
-
- Disadvantages
-
UCS can be used for time series and expiring TTL workloads, but it isn’t ideal for all such workloads. It isn’t designed as an alternative to TWCS for append-only time series data compaction.
- Compaction mode configuration
-
UCS has three primary modes:
-
Tiered: An improved STCS mode that prioritizes low write amplification.
-
Leveled: An improved LCS mode that prioritizes low read amplification.
-
Balanced: A neutral configuration where STCS and LCS are functionally the same. This mode doesn’t prioritize read or write amplification.
-
- Dynamic runtime tuning
-
You can change the scaling property dynamically at any time to adapt to shifting workloads:
-
Decrease the scaling property during read-heavy periods to reduce read request latency.
-
Increase the scaling property to reduce write amplification when compaction falls behind during write-heavy periods.
This change only triggers the minimum necessary compactions to reach the new state. Any previously completed compactions are preserved and reused.
To minimize performance impacts, adjust scaling incrementally.
-
- Parallel compaction (sharding)
-
UCS uses sharding to enable parallel compactions and reduce the size of a node’s largest SSTables. For example, a single 1 TB SSTable could be split into 10 shards, each containing 100 GB SSTables. The sharding strategy can be tuned by the table’s
compactionproperties.UCS defines shards by splitting a node’s token ranges into equal sized sections so that each shard contains only the data for its corresponding token range. Within each shard, the compaction hierarchy operates independently, allowing compactions to occur in parallel without affecting other shards. This is valuable for high-density nodes where serial compaction can fall behind.
SizeTieredCompactionStrategy (STCS)
The SizeTieredCompactionStrategy (STCS) triggers compaction when there are multiple similarly sized SSTables on disk. You can configure the number of SSTables and the strictness of the size range.
The size range is based on the dynamically calculated average size of all SSTables for a given table with configurable margins for deviation above and below the average. For each compaction cycle, the selected SSTables are compacted once into a single large SSTable. However, the average doesn’t consistently increase because memtable flushes create smaller SSTables in addition to the larger compacted SSTables. This means that, at any given time, several SSTables of various sizes are present on disk.
- Advantages
-
Efficient compaction for write-intensive workloads.
- Disadvantages
-
-
Slower reads due to the total number of SSTables and no guarantee that rows are kept together. This means there can be many SSTables containing different versions of the same row.
-
Doesn’t evict deleted data predictably, and stale data can linger for too long.
-
Mathematically, outliers (the smallest and largest SSTables) might never be selected for compaction.
-
Continuously increasing memory and storage requirements that can overwhelm the node’s capacity if not monitored and managed preemptively. Over time, STCS accumulates large SSTables, which increases the average and causes large SSTables to be selected for compaction into even larger SSTables. Therefore, the node must have enough overhead to support compaction of very large SSTables.
-
- Size range tuning
-
Depending on a table’s tolerance for resource utilization and read amplification, you can tune the compaction strategy properties for better performance and resource utilization. These properties determine the strictness of the size range, which directly impacts table performance with STCS:
-
If the range is too strict, more SSTables must accumulate before the average is large enough to include the minimum number of SSTables.
-
If the range is too broad, compaction might run too frequently, leading to increased I/O and resource usage.
-
LeveledCompactionStrategy (LCS)
The LeveledCompactionStrategy (LCS) uses a series of levels to progressively flush memtables and compact SSTables. This strategy creates SSTables that are roughly the same size at each level, starting with a relatively small size, such as 160 MB.
SSTables are grouped into zero-indexed levels (L0, L1, L2, … Ln) that follow a, roughly, logarithmic scale where each level is approximately 10 times larger than the previous level. SSTables are continuously compacted into progressively larger sizes stored at higher levels. By extension, resource requirements and disk I/O are more predictable and consistent at each additional level.
At L1 and higher, SSTables are guaranteed to have non-overlapping row keys with other SSTables at the same level. This can improve read performance because the database only needs to check one SSTable per level for a given row key in most cases. This isn’t guaranteed for L0 because L0 receives new, uncompacted SSTables from memtable flushes.
- Advantages
-
-
Ideal for read-intensive workloads.
-
Predictable disk requirements.
-
Predictable read latency.
-
Stale data is evicted more frequently.
-
Avoids some read amplification issues that can occur with STCS.
-
- Disadvantages
-
-
Significantly increased write amplification and potential I/O saturation due to frequent compactions. LCS isn’t recommended for write-heavy workloads.
-
Requires less memory for compaction compared to STCS, but write amplification consumes more I/O.
-
Can be problematic for tables with very large partitions because the LCS compaction algorithm enforces a single SSTable per level.
-
- Progressive, scaled compaction
-
The LeveledCompactionStrategy (LCS) uses a series of zero-indexed levels where SSTables are progressively compacted into larger and larger sizes. Each level above L0 is approximately 10 times larger than the preceding level. For example, L2 is 10 times the size of L1, and L3 is 100 times the size of L1.
-
All memtables flush new SSTables to L0 to await compaction to L1.
LCS compaction doesn’t run within L0. L0 is exclusively for receiving SSTables from memtable flushes. This means reads from L0 have less predictable performance than reads at higher levels. For more information, see Failsafes.
-
LCS compacts SSTables from L0 into L1.
At L1 and higher, LCS makes every attempt to enforce non-overlapping row key ranges across all SSTables in the same level. This means that reads at L1 and higher typically only need to access one SSTable per level for a given row key. When compacting from L0 to L1, LCS reconciles L0 SSTables with existing L1 SSTables by matching row key ranges. In the rare case that there are no SStables at L1, LCS creates net new SSTables with non-overlapping row key ranges.
Additionally, LCS attempts to create SSTables that are approximately the same size within each level (L1 and higher). The target size is configurable but it isn’t strict. LCS can create smaller or larger SSTables as needed to enforce non-overlapping row key ranges. For example, LCS creates larger SSTables to avoid splitting large partitions into multiple SSTables.
-
LCS continues to compact SSTables up to higher levels as needed to enforce the progressive scale of levels.
For example, when compactions from L0 to L1 exceed the maximum SSTable capacity at L1, SSTables are arbitrarily selected for compaction from L1 to L2 until L1 is at or below maximum capacity. Compaction at any level can trigger overflow compactions to one or more higher levels until the excess is absorbed by a level with sufficient capacity.
If compaction produces a single SSTable (such as a large partition) that exceeds the current level’s limit and the subsequent level’s limit, LCS bypasses mathematically incompatible levels until it reaches a level that might have sufficient capacity.
-
- Write amplification and disk requirements
-
In terms of write amplification, compactions from L0 to L1 almost always require rewriting every SSTable at L1 because the rows in L0 SSTables usually cross all partition ranges. In contrast, compactions at L2 and higher only rewrite SSTables with matching key ranges due to guaranteed non-overlapping key ranges.
LCS compaction operations must run more often in general to ensure low read amplification by storing the minimum possible number of SSTables. Due to non-overlapping row key ranges at L1 and higher, LCS requires much less disk space for compaction compared to a strategy like STCS that must reconcile overlapping row key ranges with every compaction. However, you must account for the use of STCS as a failsafe at L0, which requires more disk space for compaction. Furthermore, I/O saturation is possible when compacting at the highest levels due to progressively larger SSTables at each additional level.
When using LCS, the maximum overhead increases dramatically beyond L3 because each level is approximately 10 times larger than the preceding level. Additionally, the overhead for each additional level adds to the cumulative overhead of all previous levels. For example, if the target SSTable size is 160 MB, L1 to L5 have the following requirements:
L1: 10 x 160 MB = 1600 MB L2: 100 x 160 MB = 16000 MB = 16 GB L3: 1000 x 160 MB = 160000 MB = 160 GB L4: 10000 x 160 MB = 1600000 MB = 1.6 TB L5: 100000 x 160 MB = 16000000 MB = 16 TBThe cumulative requirement when all of these levels are in use is more than 17 TB (rounded down). After adding a margin for L0, this example requires at least 18 TB of disk space for SSTables. This doesn’t include the database’s other disk space requirements.
(L1 + L2 + L3 + L4 + L5) = (1600 MB + 16 GB + 160 GB + 1.6 TB + 16 TB) = 17.7616 TBIf LCS compaction becomes unsustainable, you can switch to STCS, and then add nodes or reduce SSTable sizes using
sstablesplit. You can also use UCS for a combined compaction strategy where lower levels user LCS and higher levels use STCS. - Importance of memtable tuning with LCS
-
It is important that you configure
memtableparameters appropriately for LCS to avoid unnecessary spikes in disk I/O, CPU usage, and read latency. Frequent memtable flushes can overload L0 with too many small SSTables.In all read-heavy use cases, DataStax recommends less frequent memtable flushes and fewer SSTables.
- Failsafes
-
There are scenarios where the database will override the normal LCS compaction cadence to protect read performance, data integrity, and system stability:
-
Too many flushed memtables: Because L0 receives all new SSTables from memtable flushes, L0 can contain any number of SSTables of varying sizes with overlapping row keys. This can make reads at L0 less performant than reads at higher levels. In an attempt to preemptively avoid excessive read performance degradation, the database runs STCS compaction at L0 only if L0 contains more than 32 SSTables.
-
Bootstrapping: While bootstrapping a new node into a cluster that uses LCS, compaction beyond L0 is disabled. To avoid overloading L0 with SSTables streamed from a remote node and new SSTables from flushed memtables, STCS compaction runs at L0 as needed during the bootstrapping process.
-
Starved SSTables: Misconfigured levelling creates starved SSTables, which are SSTables at higher levels that aren’t selected for compaction because SSTables at lower levels aren’t being compacted as expected. This can prevent SSTables at lower levels from dropping tombstones, among other issues. The database will deliberately add starved SSTables to a compaction operation if they are skipped by multiple consecutive compactions.
You can disable STCS at L0 with the startup option
-Dcassandra.disable_stcs_in_l0=true. -
TimeWindowCompactionStrategy (TWCS)
TimeWindowCompactionStrategy (TWCS) is designed for time series and expiring time-to-live (TTL) workloads.
TWCS manages SSTables using chronological, consecutive time windows. While a time window is open, TWCS runs minor compactions on SSTables flushed from memory using STCS. When a time window closes, TWCS runs a major compaction on all SSTables within that time window to compact them into one SSTable based on the maximum timestamp of the compacted SSTables. After major compaction, TWCS never recompacts that time window’s data. However, tombstone compaction can still run on SSTables after the major compaction threshold has passed. The cycle continues iteratively as each new time window opens and the previous time window closes.
For data with TTLs, SSTables can be dropped without compaction after all TTLs have passed, the gc_grace_seconds period has expired, and the droppable tombstone ratio is 100 percent.
- Advantages
-
Well-suited for time series data stored, specifically when the following are true:
-
All data has a TTL, either the table’s default TTL or a row-level TTL
-
The time-series data is written once and never updated.
-
The table has a clustering column that is time based.
-
Read operations are scoped to specific time-bounded ranges of data rather than the full history.
-
- Disadvantages
-
-
Not appropriate when out-of-sequence time data is required because SSTables won’t compact well.
-
Not appropriate for data without a TTL workload because storage will grow without bound.
-
- TWCS and STCS properties
-
Because TWCS uses STCS for minor compactions in the active time window, you can use all STCS properties to configure the minor compaction behavior for TWCS. However, the only required properties for TWCS are the time window unit and size. All other properties for TWCS, including STCS properties, use default values when not specified. For more information, see Configure compaction.
- Time window lifecycle
-
The following example uses 12-hour wall clock time for demonstration purposes. The actual configuration would be 60 minute time windows (
compaction_window_unit = 'minutes'andcompaction_window_size = 60).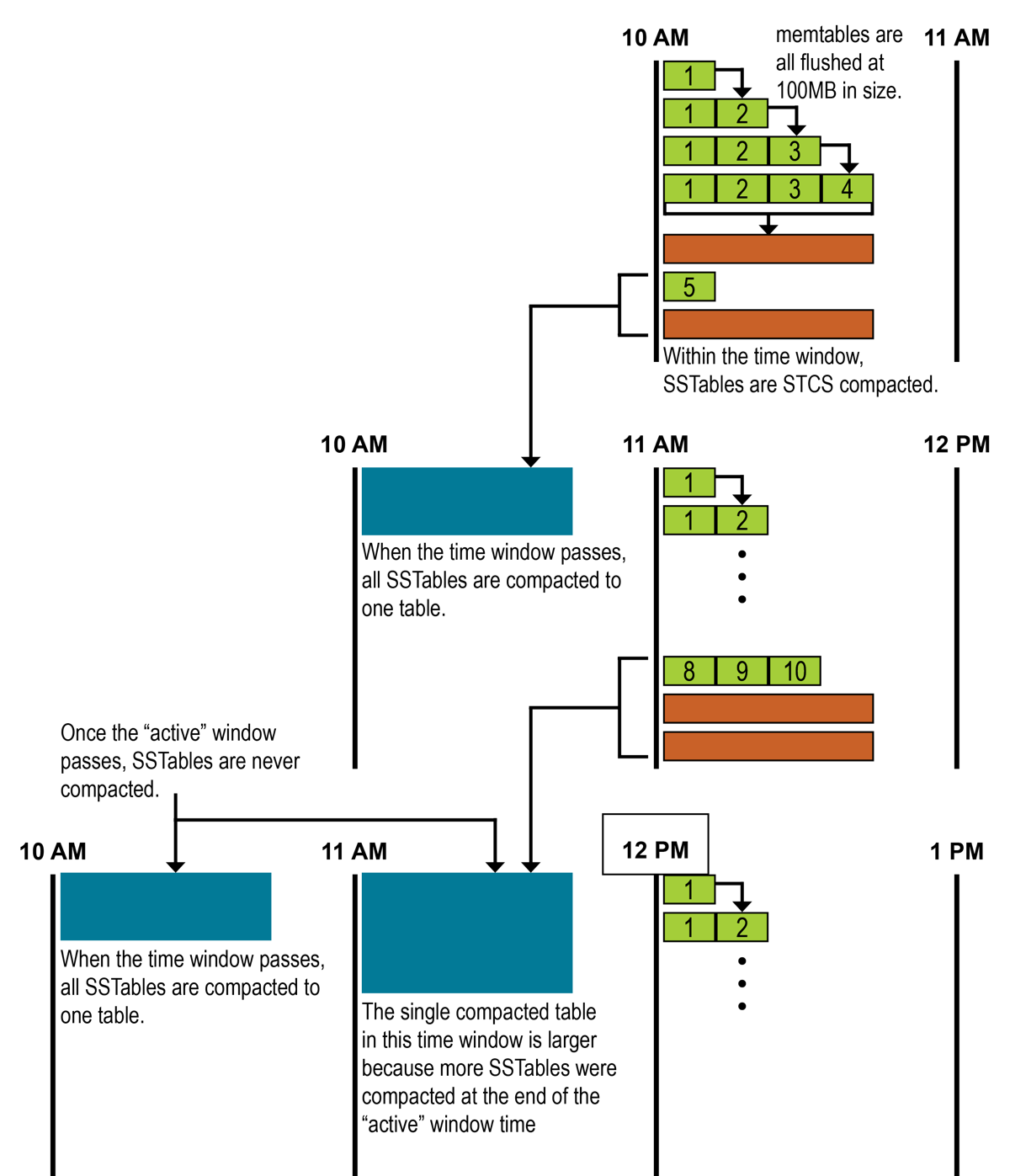 Example: TWCS window lifecycle
Example: TWCS window lifecycleDuring the first time window from 10 AM to 11 AM, memtables are flushed from memory into 100 MB SSTables, and STCS is used for minor compaction. At 11 AM, the first window closes, and major compaction merges all SSTables into a single SSTable that is never recompacted by TWCS. Simultaneously, the second window (11 AM to 12 PM) opens and begins accumulating small SSTables from memtable flushes and running minor compactions with STCS. At 12 PM, the second window closes, triggering major compaction of its SSTables, and the third window opens. The cycle continues iteratively as each new time window opens and the previous time window closes.
The size of a window’s final SSTable depends on the volume of writes during that window. Windows that cover more active periods inherently have the largest final SSTables.
DateTieredCompactionStrategy (DTCS) (deprecated)
This strategy is deprecated. Use TWCS or UCS in tiered mode instead. Compare to DTCS, TWCS offers a simplified configuration with fewer parameters.
The DateTieredCompactionStrategy (DTCS) was similar to STCS, but compaction was based on SSTable age rather than size. Because each column in an SSTable is marked with the write time timestamp, DTCS determined the age of the SSTable based on the earliest timestamp on any column in the SSTable.
Compaction strategy questionnaire
Use the following questions to help you choose the ideal compaction strategies for your tables:
- Does your table process time series data?
-
Use TWCS for time series and expiring time-to-live (TTL) workloads, especially when the following conditions are true:
-
The time-series data is written once and never updated.
-
The data has a clustering column that is time based.
-
Read operations are scoped to specific time-bounded ranges of data rather than the full history.
-
- Is the table accessed mostly for reads or mostly for writes?
-
-
Reads always exceed writes by a factor of two or more (
(Reads x 2+) > Writes): Use LCS when reads are significantly higher than writes, particularly randomized reads. You can also use UCS in leveled mode. -
Reads and writes are nearly equal (
Reads ≈ Writes): Because LCS can be overwhelmed by increased writes, the performance impact can outweigh the advantages of LCS. If writes tend to exceed reads or your workloads are highly latency sensitive, consider another strategy. -
Writes consistently exceed reads (
Writes > Reads): Because LCS can be overwhelmed by increased writes, LCS isn’t recommended for write-heavy workloads. Consider another strategy.
-
- How often does the data change?
-
If your data is static (written once and never updated), or there are few upserts, you can use STCS.
For static time series data, use TWCS.
- Do you require predictable levels of read or write activity?
-
LCS can maintain a predictable number and size of SSTables. You can also use UCS in leveled mode. This can be important for meeting Service Level Agreement (SLA) targets.
For example, if your table’s read-to-write ratio is small, and you have strict read latency requirements, the write performance penalty caused by LCS might be an acceptable tradeoff to ensure predictable read performance. Additionally, adding more nodes might reduce the impact on write performance.
- Is your table populated by a batch process?
-
For batched reads and writes, STCS performs better than LCS. You can also use UCS in tiered mode. Because batch operations cause little or no fragmentation, the benefits of leveled compaction aren’t realized, and batch writes can overwhelm leveled compaction operations.
- Is disk space a concern?
-
LCS handles disk space more efficiently than STCS. You can also use UCS in leveled mode.
In addition to disk space reserved for data, leveled compaction requires approximately 10 percent more space for compaction overhead. In contrast, STCS can require as much as 50 percent more space.
- Is I/O saturation a concern?
-
LCS is significantly more I/O intensive than STCS. If your workloads are already approaching the system’s I/O maximum capacity, or you want to avoid I/O saturation, don’t use LCS. Instead, use STCS or UCS in tiered mode.
