Run the Weather Sensor demo
Using the Weather Sensor demo, you can compare how long it takes to run Spark SQL queries against aggregated data for a number of weather sensors in various cities. For example, you can view reports using different metrics, such as temperature or humidity, and get a daily roll up.
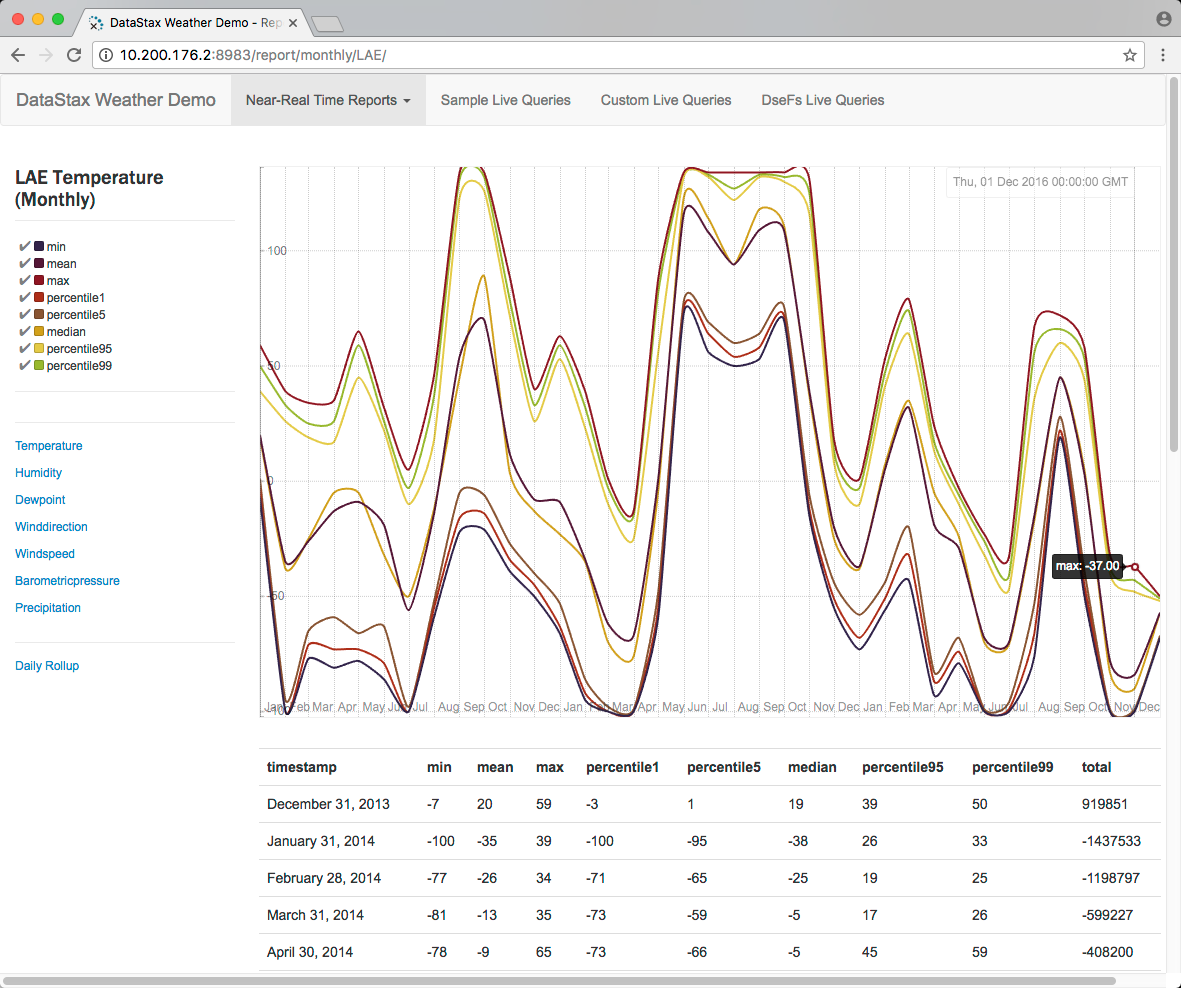
You run customize Spark SQL queries using different metrics and different dates. In addition to querying CQL tables, you time Spark SQL queries against data in DataStax Enterprise File System (DSEFS).
|
DataStax demos do not work with LDAP or internal authorization (username/password) enabled. |
Prepare the environment
-
Install Python 3.10 or later.
-
Install
pip. -
Install the required packages for the Weather Sensor demo:
-
libsasl2-dev(Debian and Ubuntu) -
cyrus-sasl-lib(RedHat or CentOS) -
pyhs2 -
six -
flask -
cassandra-driver(the Apache Cassandra® Python driver)
-
-
If you installed DSE using a tarball or the GUI-no services option, set the
PATHenvironment variable to your DSE installation’s/bindirectory:export PATH=$PATH:INSTALLATION_DIRECTORY/bin
Start DSE and import data
Start DSE in Spark mode, and then run a script that creates the schema for weather sensor data model.
The script also imports aggregated data from CSV files into DSE tables.
The script uses the hadoop fs command to put the CSV files into the DSEFS.
-
Start DSE in Apache Spark mode.
-
Run the
create-and-loadCQL script in thedemos/weather_sensors/resourcesdirectory. For example:cd INSTALLATION_DIRECTORY/demos/weather_sensors/resources bin/create-and-loadThe default location of the demos directory depends on the type of installation:
-
Package installations: /usr/share/dse/demos
-
Tarball installations: installation_location/demos The output confirms that the script imported the data into CQL and copied files to DSEFS.
If an error occurs, set the
PATHas described in Prepare the environment, and then retry the script. -
Starting the Spark SQL Thrift server
You start the Spark SQL Thrift server on a specific port to avoid conflicts.
Start using your local user account.
Do not use sudo.
-
Start the Spark SQL Thrift server on port 5588. For example:
cd INSTALLATION_DIRECTORY dse spark-sql-thriftserver start --hiveconf hive.server2.thrift.port=5588
Start the web app and query the data
-
Open another terminal and start the Python service that controls the web interface:
cd INSTALLATION_DIRECTORY/demos/weather_sensors python web/weather.py -
Open a browser and go to the following URL:
http://localhost:8983/The weather sensors app appears. Select Near Real-Time Reports on the horizontal menu. A drop-down listing weather stations appears:
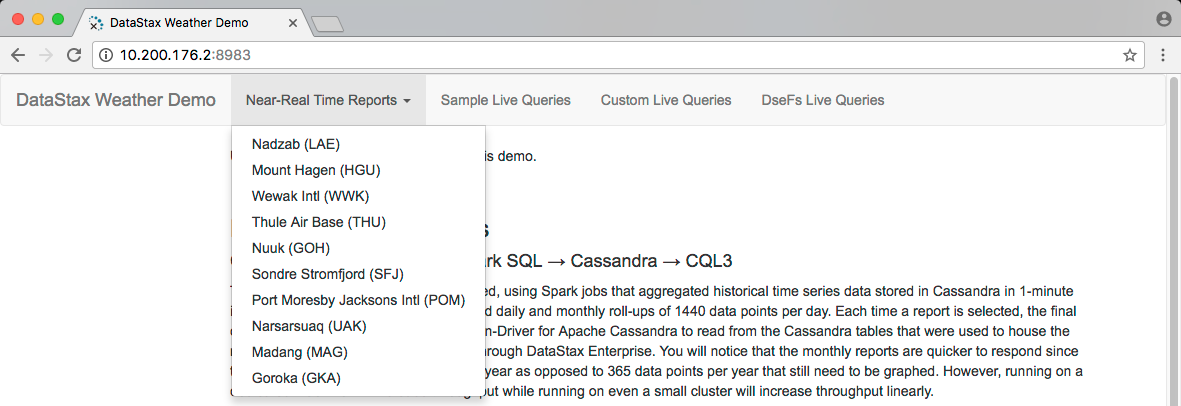
-
Select a weather station from the drop-down, view the graph, and select different metrics from the vertical menu on the left side of the page.
-
On the horizontal menu, click Sample Live Queries, then select a sample script. Click the Spark SQL button, then click Submit.
The time spent loading results using Apache Spark appears.
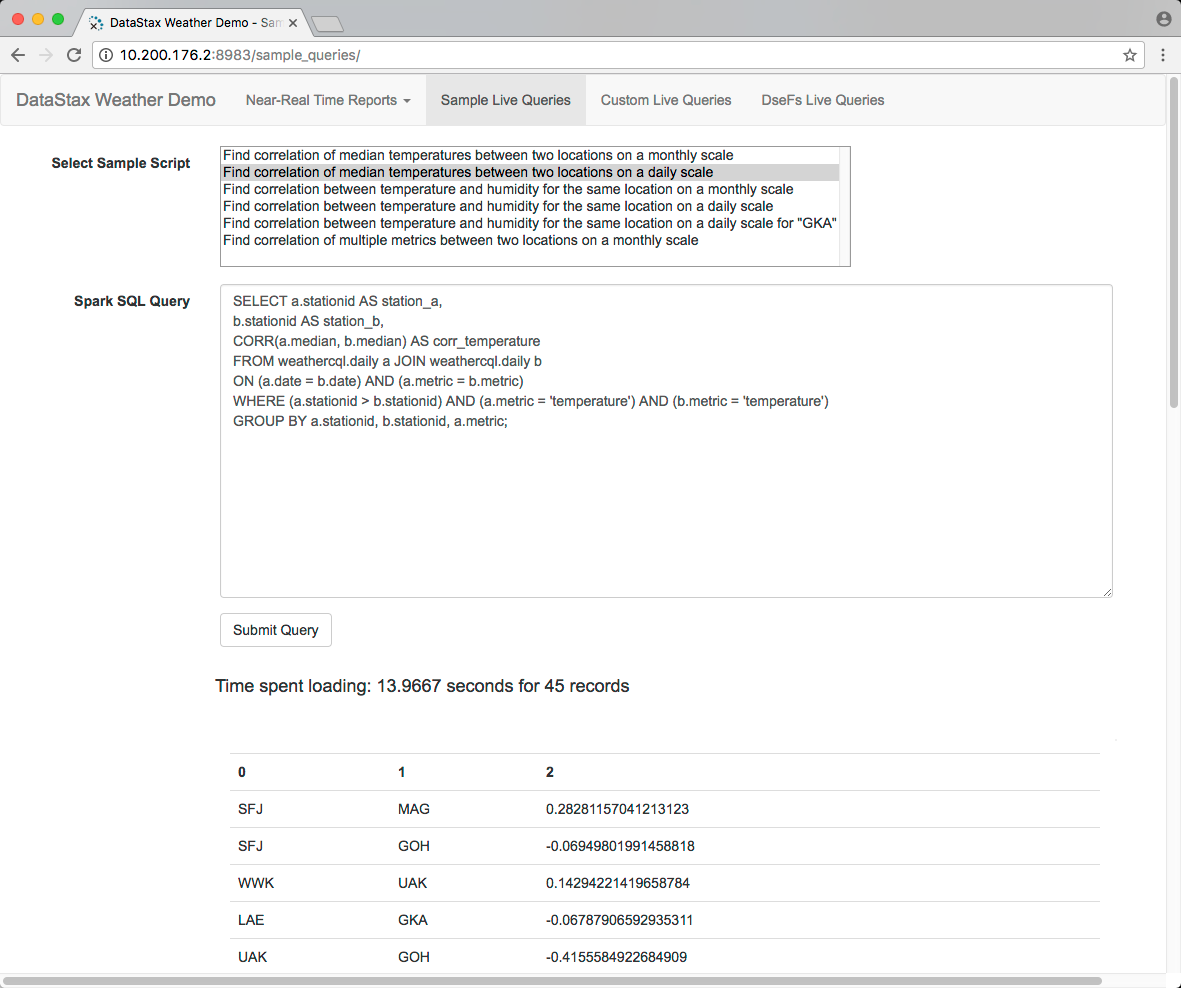
If you are running the demo on a SearchAnalytics datacenter, port 8983 conflicts with the Search web UI. Change the port in the
demos/weather_sensors/web/weather.pyto a free port:app.run(host='0.0.0.0', port=8984, threaded=True, debug=True) -
From the horizontal menu, click Custom Live Queries. Click a Week Day, and then a metric, such as Wind Direction. Click Recalculate Query. The query reflects the selections you made.
-
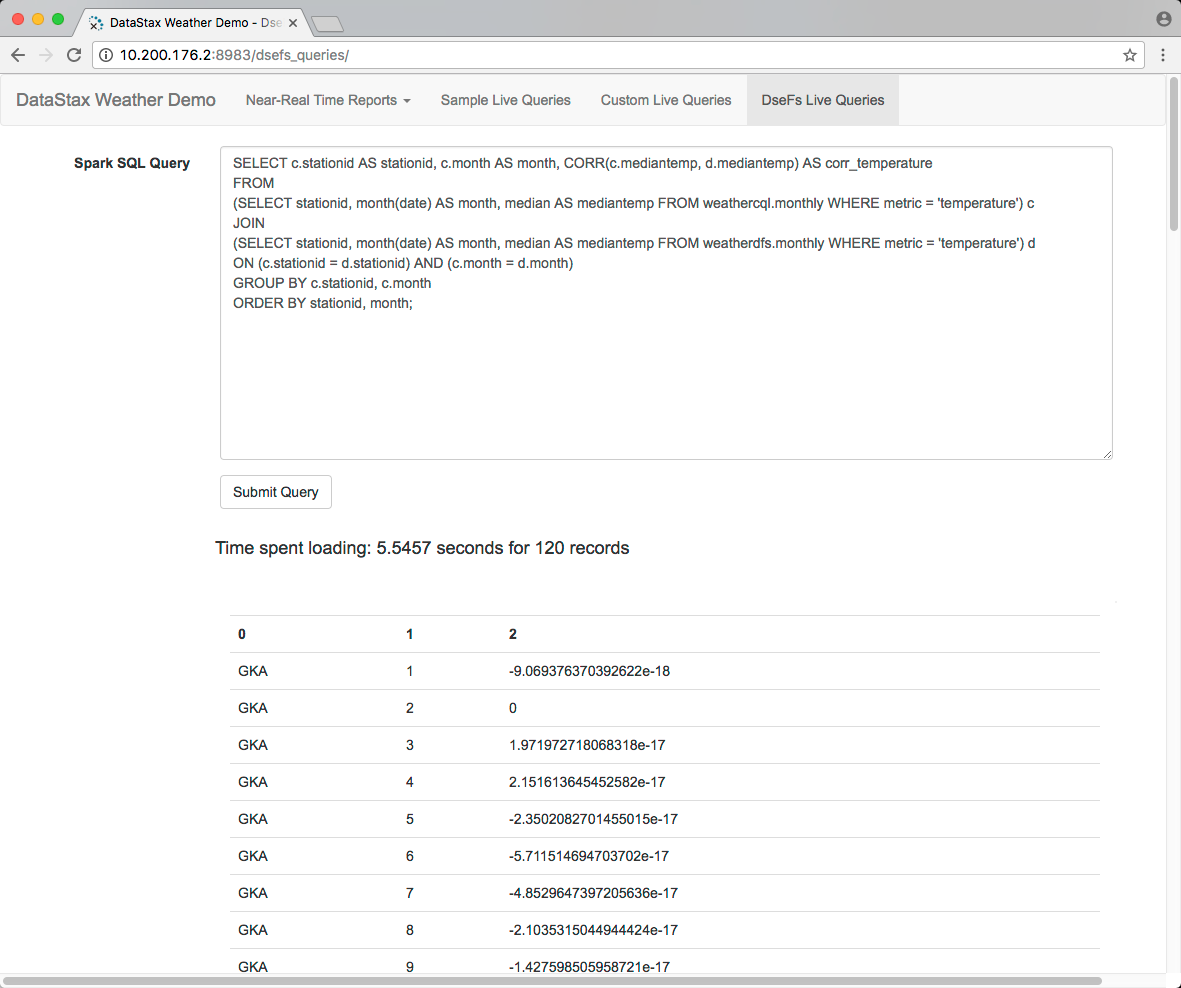
From the horizontal menu, click DSEFS Live Queries. Click Submit query. The time spent loading results from DSEFS using Spark SQL appears.
Clean up
-
Remove all generated data:
cd INSTALLATION_DIRECTORY/demos/weather_sensors bin/cleanup -
Remove the
weathercqlkeyspace from the cluster:cqlsh -e "DROP KEYSPACE weathercql;"
