cassandra-stress user
Interleave user provided queries with configurable ratio and distribution.
Synopsis
cassandra-stress user [arguments]Command options
- cl=?
-
Set the consistency level to use during
cassandra-stress. Options areONE,QUORUM,LOCAL_ONE(default),LOCAL_QUORUM,EACH_QUORUM,ALL, andANY. - clustering=DIST(?)
-
Distribution clustering runs of operations of the same kind.
- duration=?
-
Specify the time to run, in seconds, minutes, or hours.
- err<?
-
Specify a standard error of the mean. When this value is reached,
cassandra-stresswill end.Default:
0.02 - n>?
-
Specify a minimum number of iterations to run before accepting uncertainly convergence.
- n<?
-
Specify a maximum number of iterations to run before accepting uncertainly convergence.
- n=?
-
Specify the number of operations to run.
- no-warmup
-
Do not warmup the process. Do a cold start.
- ops(?)
-
Specify what operations to run and the number of each. Only valid with the
useroption. - profile=?
-
Designate the YAML file to use with
cassandra-stress. Only valid with theuseroption. - truncate=?
-
Truncate the table created during
cassandra-stress. Options arenever,once,always.Default:
neverThe
truncateoption must be inserted before themodeargument, otherwise thecassandra-stresstool won’t apply truncation as specified.
Command arguments
- -col
-
Column details, such as size and count distribution, data generator, names, and comparator:
Supports multiple syntax formats:
-col names=? [slice] [super=?] [comparator=?] [timestamp=?] [size=DIST(?)]-col [n=DIST(?)] [slice] [super=?] [comparator=?] [timestamp=?] [size=DIST(?)] - -errors
-
How to handle errors when encountered during stress testing:
-errors [retries=N] [ignore] [skip-read-validation]-
retries=<N>: Number of times to try each operation before failing. -
ignore: If included, won’t fail on errors. Omit this argument to fail on errors. -
skip-read-validation: Include to skip read validation and message output.
-
- -graph
-
Graph results of
cassandra-stresstests. Multiple tests can be graphed together.-graph file=? [revision=?] [title=?] [op=?] - -insert
-
Insert specific options relating to various methods for batching and splitting partition updates.
-insert [revisit=DIST(?)] [visits=DIST(?)] partitions=DIST(?) [batchtype=?] select-ratio=DIST(?) row-population-ratio=DIST(?) - -log
-
Where to log progress and the interval to use.
-log [level=?] [no-summary] [file=?] [hdrfile=?] [interval=?] [no-settings] [no-progress] [show-queries] [query-log-file=?] - -mode
-
Thrift or CQL with options. Supports multiple syntax formats:
-mode thrift [smart] [user=?] [password=?]-mode native [unprepared] cql3 [compression=?] [port=?] [user=?] [password=?] [auth-provider=?] [maxPending=?] [connectionsPerHost=?] [protocolVersion=?]-mode simplenative [prepared] cql3 [port=?] - -node
-
Nodes to connect to.
-node [datacenter=?] [whitelist] [file=?] - -pop
-
Population distribution and intra-partition visit order. Supports multiple syntax formats:
-pop seq=? [no-wrap] [read-lookback=DIST(?)] [contents=?]-pop [dist=DIST(?)] [contents=?] - -port
-
Specify port for connecting nodes. Port can be specified for Apache Cassandra native protocol (
native=), Thrift protocol (thrift=), or a JMX port (jmx=) for retrieving statistics.-port [native=?] [thrift=?] [jmx=?] - -rate
-
Set the rate. Supports multiple syntax formats:
-
Throttle to a fixed rate of operations per second with a specified number of threads:
-rate threads=? [throttle=?] [fixed=?]-
threads=?: Number of clients to run concurrently. -
throttle=?: Throttle operations per second across all clients to a maximum rate (or less) with no implied schedule. Default: 0 -
fixed=?: Expect fixed rate of operations per second across all clients with implied schedule. Default: 0
-
-
Gradually increase the number of threads until a specified minimum or maximum is reached, or until throughput saturates:
-rate [threads>=?] [threads<=?] [auto]-
threads>=?: Run at least this many clients concurrently. Default: 4 -
threads⇐?: Run at most this many clients concurrently. Default: 1000 -
auto: Stop increasing threads once throughput saturates.
-
-
- -schema
-
Schema configuration including replication settings, keyspace, compression, and compaction:
-schema [replication(?)] [keyspace=?] [compaction(?)] [compression=?] - -sendto
-
Specify a server to send the stress command to.
-sendto <host> - -tokenrange
-
Token range settings.
-tokenrange [no-wrap] [split-factor=?] [savedata=?] - -transport
-
Custom transport factories.
-transport [factory=?] [truststore=?] [truststore-password=?] [keystore=?] [keystore-password=?] [ssl-protocol=?] [ssl-alg=?] [store-type=?] [ssl-ciphers=?]
Use the -graph option
In Apache Cassandra 3.2 and later, the -graph option provides visual feedback for
cassandra-stress tests. A file must be named to build the resulting HTML file. A
title and revision are optional, but revision must be used if multiple stress tests are graphed on the same output.
cassandra-stress user profile=tools/cqlstress-example.yaml ops\(insert=1\) -graph file=test.html title=test revision=test1An interactive graph can be displayed with a web browser:
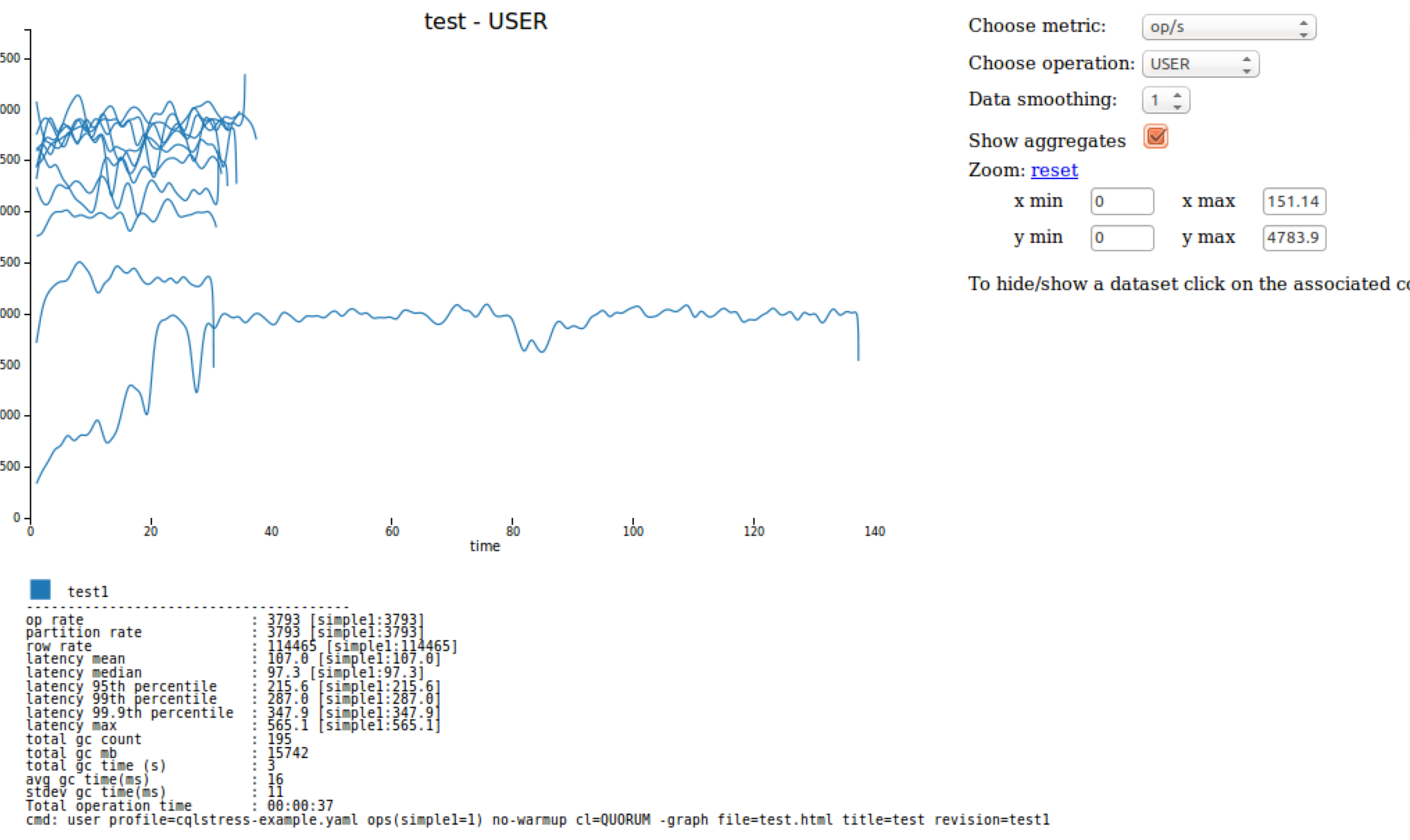
Use a YAML file to run cassandra-stress
This example uses a YAML file named cqlstress-example.yaml, which contains the keyspace
and table definitions, and a query definition. The keyspace name and definition are the first entries in
the YAML file:
keyspace: perftesting
keyspace_definition:
CREATE KEYSPACE perftesting WITH replication = { 'class': 'SimpleStrategy', 'replication_factor': 3};The table name and definition are created in the next section using CQL:
table: users
table_definition:
CREATE TABLE users (
username text,
first_name text,
last_name text,
password text,
email text,
last_access timeuuid,
PRIMARY KEY(username)
);In the extra_definitions section you can add secondary indexes or
materialized views to the table:
extra_definitions:
- CREATE MATERIALIZED VIEW perftesting.users_by_first_name AS SELECT * FROM perftesting.users WHERE first_name IS NOT NULL and username IS NOT NULL PRIMARY KEY (first_name, username);
- CREATE MATERIALIZED VIEW perftesting.users_by_first_name2 AS SELECT * FROM perftesting.users WHERE first_name IS NOT NULL and username IS NOT NULL PRIMARY KEY (first_name, username);
- CREATE MATERIALIZED VIEW perftesting.users_by_first_name3 AS SELECT * FROM perftesting.users WHERE first_name IS NOT NULL and username IS NOT NULL PRIMARY KEY (first_name, username);The population distribution can be defined for any column in the table. This section specifies a uniform distribution between 10 and 30 characters for username values in gnerated rows, that the values in the generated rows willcreates , a uniform distribution between 20 and 40 characters for generated startdate over the entire Apache Cassandra cluster, and a Gaussian distribution between 100 and 500 characters for description values.
columnspec:
- name: username
size: uniform(10..30)
- name: first_name
size: fixed(16)
- name: last_name
size: uniform(1..32)
- name: password
size: fixed(80) # sha-512
- name: email
size: uniform(16..50)
- name: startdate
cluster: uniform(20...40)
- name: description
size: gaussian(100...500)After the column specifications, you can add specifications for how each batch runs. In the following
code, the partitions value directs the test to use the column definitions above to
insert a fixed number of rows in the partition in each batch:
insert:
partitions: fixed(10)
batchtype: UNLOGGEDThe last section contains a query, read1, that can be run against the defined table.
queries:
read1:
cql: select * from users where username = ? and startdate = ?
fields: samerow # samerow or multirow (select arguments from the same row, or randomly from all rows in the partition)The following example shows using the user option and its parameters to run
cassandra-stress tests from cqlstress-example.yaml:
cassandra-stress user profile=tools/cqlstress-example.yaml n=1000000 ops\(insert=3,read1=1\) no-warmup cl=QUORUMNotice that:
-
The user option is required for the
profileandoptparameters. -
The value for the profile parameter is the path and filename of the .yaml file.
-
In this example,
-nspecifies the number of batches that run. -
The values supplied for
opsspecifies which operations run and how many of each. hese values direct the command to insert rows into the database and run the read1 query.
How many times? Each insert or query counts as one batch, and the values in ops
determine how many of each type are run. Since the total number of batches is 1,000,000, and
ops says to run three inserts for each query, the result will be 750,000 inserts and
250,000 of the read1 query.
Use escaping backslashes when specifying the ops value.
