How are indexes stored and updated?
Secondary indexes for DataStax Enterprise (DSE) filter tables for data stored in non-primary key columns. For example, a table storing cyclist names and ages using the last name of the cyclist as the primary key might have a secondary index on the age to allow queries by age. Because querying should always result in a continuous slice of data being retrieved from the table, querying to match a non-primary key column is an anti-pattern.
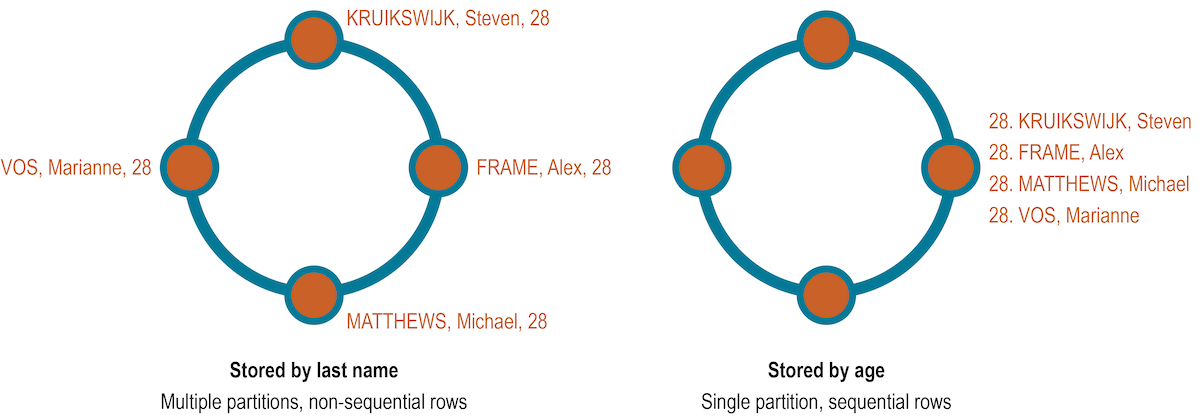
If the table rows are stored based on last names, the table might be spread across several partitions stored on different nodes.
Queries based on a particular range of last names, such as all cyclists with the last name Matthews, retrieve sequential rows from the table.
However, a query based on age, such as all cyclists who are 28, requires all nodes to be queried for a value.
An index on age could be used, but a better solution is to create a materialized view or additional table that is ordered by age.
|
Non-primary keys play no role in ordering the data in storage, so querying for a particular value of a non-primary key column results in scanning all partitions. Scanning all partitions generally results in a prohibitive read latency, and is not allowed. |
Secondary indexes can be built for a column in a table. These indexes are stored locally on each node in a hidden table and built in a background process. If a query includes both a partition key condition and a secondary index column condition, the query will be successful because the query can be directed to a single node partition.
If a secondary index is used in a query that is not restricted to a particular partition key, the query will have prohibitive read latency because all nodes will be queried.
A query with these parameters is allowed only if the query option ALLOW FILTERING is used.
This option is not appropriate for production environments, and does not guarantee trouble-free indexing.
Knowing when to use an index is imperative.
As with relational databases, keeping indexes current uses processing time and resources, so unnecessary indexes should be avoided. When a column is updated, the index is updated as well. If the old column value still exists in the memtable, which typically occurs when updating a small set of rows repeatedly, DSE removes the corresponding obsolete index entry; otherwise, the old entry remains to be purged by compaction. If a read sees a stale index entry before compaction purges it, the reader thread invalidates it.
