About DSE Analytics Solo
DSE Analytics Solo datacenters provide analytics processing with Apache Spark™ and distributed storage using DSEFS without storing transactional database data.
DataStax Enterprise (DSE) is flexible when deploying analytic processing in concert with transactional workloads. There are two main ways to deploy DSE Analytics: collocated with the database processing nodes, and on segregated machines in their own datacenter.
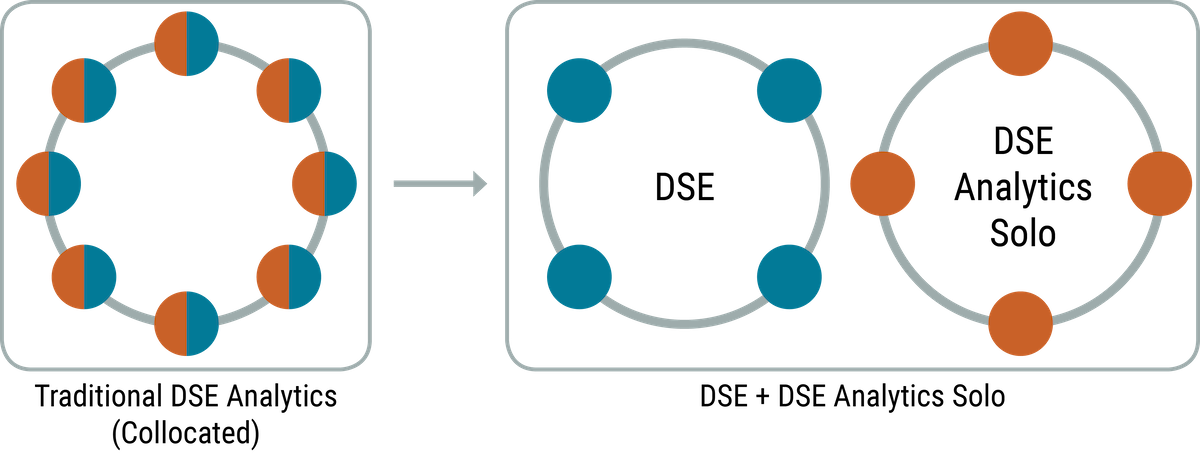
Traditional DSE Analytics deployments have both the DataStax database process and the Spark process running on the same machine. This allows for simple deployment of analytic processing when the analysis is not as intensive, or the database is not as heavily used.
DSE Analytics Solo allows customers to deploy DSE Analytics processing on segregated hardware configurations in a different datacenter from the transactional DSE nodes. This ensures consistent behavior of both engines in a configuration that does not compete for computer resources. This configuration is good for processing-intensive analytic workloads.
DSE Analytics Solo allows the flexibility to have more nodes dedicated to data processing than are used for database transactions. This is particularly good for situations where the processing needs far exceed the transactional resource needs. For example, suppose you have a Spark Streaming job that will analyze and filter 99.9% of the incoming data, storing only a few records after analysis. The resources required by the transactional datacenter are much smaller than the resources required to analyze the data.
DSE Analytics Solo is more elastic in terms of scaling up, or down, the analytic processing in the cluster. This is particularly useful when you need extra analytics processing, such as end of the day or end of the quarter surges in analytics jobs. Since a DSE Analytics Solo node does not store database data, when new nodes are added to a cluster there is very little data moved across the network to the new nodes. In an analytics and transactional collocated environment, adding a node means moving transactional data between the existing nodes and the new nodes.
For information on creating a DSE Analytics Solo datacenter, see Creating a DSE Analytics Solo datacenter.
