Architecture in brief
This page provides essential information for understanding and using DataStax Enterprise (DSE). Because DSE differs from a relational database, you will save yourself a lot of time by reading and understanding each section on this page.
How DataStax Enterprise works
DataStax Enterprise (DSE) version 6.8 is the industry’s best distributed cloud database designed for hybrid cloud. Easily deploy the only active-everywhere database platform that runs wherever needed: on-premises, across regions or clouds. Benefit from all the capabilities of the best distribution of Apache Cassandra® with enterprise tooling and expert support required for production cloud applications.
DSE is designed to handle big data workloads across multiple nodes with no single point of failure. Its architecture is based on the understanding that system and hardware failures can and do occur.
Write consistency
DSE addresses the problem of failures by employing a peer-to-peer distributed system across homogeneous nodes where data is distributed among all nodes in the cluster. Each node frequently exchanges state information about itself and other nodes across the cluster using the peer-to-peer gossip communication protocol. Each node maintains a sequentially written commit log that captures write activity to ensure data durability. DSE then indexes and writes the data to an in-memory structure, called a memtable, which resembles a write-back cache.
Each time the memory structure is full, the node writes the data to disk in an SSTable data file. All writes are automatically partitioned and replicated throughout the cluster. DSE periodically consolidates SSTables using compaction. This process discards obsolete data that has been marked for deletion with a tombstone. A tombstone is a marker in a row that indicates the column will be deleted. To ensure all data across the cluster stays consistent, DSE employs various repair mechanisms.
For more information, see the following:
Request handling
DSE is a partitioned row store database, where rows are organized into tables with a required primary key. Tables are organized into keyspaces. Typically, a DSE cluster has one keyspace per application with many tables in each keyspace.
The DSE architecture allows any authorized user to connect to any node in any datacenter and access data using the Cassandra Query Language (CQL).
|
CQL uses a similar syntax to SQL and works with table data. You can access CQL through the CQL shell, DataStax Studio, and Apache Cassandra drivers. |
Your client applications can send read and write requests to any node in the cluster. When a client connects to a node with a request, that node serves as the coordinator node for that particular client operation. The coordinator acts as a proxy between the client application and the nodes that own the data being requested. The coordinator determines which nodes in the ring should get the request based on how the cluster is configured.
For more information, see the following:
Key structures
The following components are essential to understanding the DSE architecture:
- Node
-
Nodes store your data. They are the basic database infrastructure component. Technically, they are Java virtual machines running an instance of the DSE software.
A coordinator node is a temporary designation for a node that receives a request from a client, and then coordinates the request across the cluster.
A seed node is used to bootstrap the gossip process for new nodes joining a cluster. Seed nodes are configured per cluster.
- Cluster
-
A group of distributed nodes for storing data. A cluster can have a single node, single datacenter, or multiple datacenters.
- Datacenter
-
A group of related nodes configured together within a cluster for replication purposes. A datacenter can be a physical datacenter or virtual datacenter. Using separate datacenters prevents transactions from being impacted by other workloads and lowers latency. Depending on the replication factor, data can be written to multiple datacenters. Datacenters must never span physical locations.
Each datacenter usually contains only one node type. The available node types are as follows:
-
Transactional: Previously referred to as a Cassandra node.
-
DataStax Graph: A graph database for managing, analyzing, and searching highly-connected data.
-
DSE Analytics: Integration with Apache Spark™.
-
DSE Search: Integration with Apache Solr™.
-
DSE SearchAnalytics: DSE Search queries within DSE Analytics jobs.
-
- Replication
-
The process of storing copies of data on multiple nodes. Replication ensures reliability and fault tolerance. The number of copies is set by the replication factor.
- Commit log
-
All data is written first to the commit log for durability. After all its data has been flushed to SSTables, it can be archived, deleted, or recycled.
- SSTable
-
A sorted string table (SSTable) is an immutable data file to which the database writes memtables periodically.
SSTables are append only and stored on disk sequentially and maintained for each database table.
- Tombstone
-
A marker in a row that indicates data will be deleted.
During compaction, marked data is deleted.
- Keyspace
-
A container for one or more tables within a database.
Keyspaces are a critical aspect of data modeling.
- CQL table
-
A group of ordered columns fetched by table row. A table consists of columns and has a primary key.
Each row represents a contiguous piece of data having one or more properties (values). For example, a table containing purchase history for an online store might include values like
name,address,customer_id,purchase_date, andorder_idin each row. Values can be stored as various data types, like text, numbers, arrays, dates, booleans, and vectors.
Key components for configuring DataStax Enterprise
- Gossip
-
A peer-to-peer communication protocol to discover and share location and state information about the other nodes in a DSE cluster. Gossip information is persisted locally by each node to use immediately when a node restarts.
- Partitioner
-
A partitioner distributes data evenly across the nodes in the cluster for load balancing.
Specifically, a partitioner determines which node receives the first replica of a piece of data, and how to distribute other replicas across other nodes in the cluster. Each row of data is uniquely identified by a primary key, which can be the same as its partition key, and can include optional clustering columns. A partitioner is a hash function that derives a token from the primary key of a row. The partitioner uses the token value to determine which nodes in the cluster receive the replicas of that row. The Murmur3Partitioner is the default partitioning strategy for new DSE clusters and the right choice for new clusters in almost all cases.
- Replication factor
-
Replication is the process of storing copies of data on multiple nodes. Replication ensures reliability and fault tolerance. The number of copies is set by the replication factor.
A replication factor of 1 means that there is only one copy of each row on one node. A replication factor of 2 means two copies of each row, where each copy is on a different node. All replicas are equally important; there is no primary or master replica. You define the replication factor for each datacenter. Generally, set the replication strategy greater than one, but no more than the number of nodes in the cluster.
- Replica placement strategy
-
A replication strategy determines which nodes to place replicas on. The first replica of data is simply the first copy; it is not unique in any sense. The NetworkTopologyStrategy is highly recommended for most deployments because it is much easier to expand to multiple datacenters when required by future expansion.
When creating a keyspace, you must define the replica placement strategy and the number of replicas you want.
- Snitch
-
A snitch maps from the IP addresses of nodes to physical and virtual locations, such as racks and datacenters. Snitches inform the database about the network topology so that requests are routed efficiently and allows the database to distribute replicas by grouping machines into datacenters and racks.
You must configure a snitch when you create a cluster. All snitches use a dynamic snitch layer, which monitors performance and chooses the best replica for reading. The dynamic snitch is enabled by default and recommended for use in most deployments. Configure dynamic snitch thresholds for each node in the cassandra.yaml configuration file.
The default DseSimpleSnitch does not recognize datacenter or rack information. Use it for single-datacenter deployments or single-zone in public clouds. The GossipingPropertyFileSnitch is recommended for production. It defines a node’s datacenter and rack and uses gossip for propagating this information to other nodes.
- cassandra.yaml configuration file
-
The main configuration file for setting the initialization properties for a cluster, caching parameters for tables, properties for tuning and resource utilization, timeout settings, client connections, backups, and security. By default, a node is configured to store the data it manages in a directory set in the cassandra.yaml file.
In a production cluster deployment, DataStax recommends changing the commitlog directory to a different disk drive from the data file directories.
- dse.yaml configuration file
-
The configuration file for DSE Advanced Security, DSE Search, DSE Graph, and DSE Analytics.
- System keyspace table properties
-
You set storage configuration attributes on a per-keyspace or per-table basis programmatically or using a client application, such as CQL shell (
cqlsh). - Loading and unloading data
-
Use these tools to move data into and out of your database:
-
Streaming tools, such as the DataStax Apache Kafka Connector
Basic data modeling concepts
Data modeling in Cassandra-based databases, like DSE, is different from relational databases. Here are some basic concepts to consider when modeling your data:
- Design the data model
-
The design of the data model is based on the queries you want to perform, not on modeling entities and relationships like you do for relational databases.
- Keyspace
-
The outermost grouping of data, similar to a schema in a relational database. All tables belong to a keyspace. A keyspace is the defining container for replication.
- Table
-
A table stores data based on a primary key, which consists of a partition key and optional clustering columns. Materialized views can also be added for high cardinality data.
-
A partition key defines the node on which the data is stored, and divides data into logical groups. Define partition keys that evenly distribute the data and also satisfy specific queries. Query and write requests across multiple partitions should be avoided if possible.
-
A clustering column defines the sort order of rows within a partition. When defining a clustering column, consider the purpose of the data. For example, retrieving the most recent transactions, sorted by date, in descending order.
-
Materialized views are tables built from another table’s data with a new primary key and new properties. Queries are optimized by the primary key definition. Data in the materialized view is automatically updated by changes to the source table.
In earlier versions of DSE and Cassandra, a column family was synonymous in many respects, to a table.
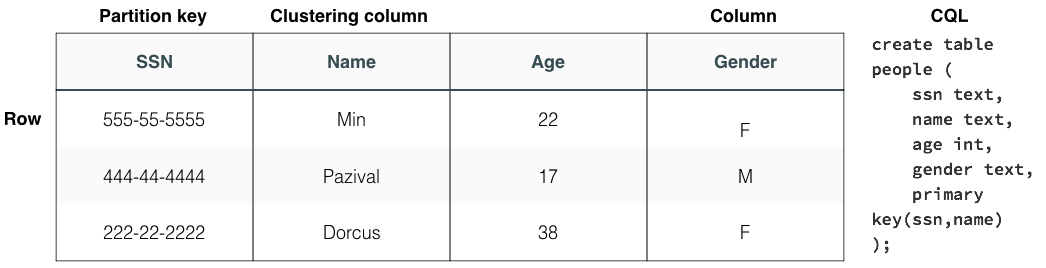 Table example
Table example
-
