Graph data modeling example
Details of a larger data model creation.
Let’s consider the world of food further to create a complex data model. This example will go through some of the thinking behind creating a graph database data model. Many different decisions are made to optimize the schema for a graph. Some of the following considerations include:
-
vertex vs property
-
vertex property vs edge property
-
properties with multiple values
-
properties associated with other properties
-
edge directionality
-
edge uniqueness (single edge vs multiple edges)
-
indexes - why use them and which ones
-
complexity
Vertex, edge or property?
In general, if an entity is a thing, it will be a vertex. If it describes an action on a thing, it’s an edge. Lastly, if it is a qualifier of a thing, it is a property.
For instance, what is a possible additional type of vertex besides person and recipe in the food data model?
Recipes use ingredients, so ingredient vertices will be required.
Recipes are generally published in cookbooks, so book vertices will also be added.
What are some edges that will connect these vertices?
Each ingredient is included_in a recipe, and each recipe is likely included_in at least one book.
And finally, all of these vertices and edges have properties.
An ingredient will have a name and id, a book will have a publish_year, an edge included_in can identify the amount of an ingredient used in a recipe.
A recipe can be included_in many books, creating multiple edges between vertices.
Vertex vs property
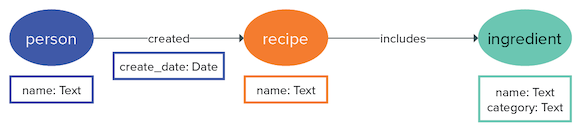
Sometimes, a property may seem to be the best schema option for an entity. But in some cases, making the property into another vertex label would be a better choice. Let’s look at the following vertex: image::dataModelExample1.png[]
It seems perfectly obvious that an ingredient should have a category property.
But could category be a vertex with an edge connecting an ingredient with several categories?
Generally, vertex properties are easily queried, so are edges between vertices.
What is the deciding factor in which option to use?
One key data model feature you want to avoid is a super-node, a single vertex containing billions of connections to other vertices.
With ingredients, there is unlikely to be billions of ingredients in any category, unless the category is absurdly broad, like hot_food.
Another deciding factor can be to contemplate if the category vertex would have any property of its own.
Perhaps a category is a member of another category, branching out from a broad category to more sub-categories.
In this case, however, it seems that category has no definite requirements, so creating it either as a property or a vertex is reasonable.
Vertex property vs edge property
Vertex and edge properties can be searched equally well, starting with a specific set of vertices or edges based on property key:value pairs.
For instance, if I want to find all the cookbook authors in France, I can search all the vertices with the vertex label person who have lived in the country of France.But I can also search all the edges between a vertex label person and a vertex label country with an edge property of lived_in.
DSG can equally search these two scenarios, and often, a particular query must be tested to see which is optimal.
For a different query, you can find all the cookbook authors in France who know Julia Child, but the query begins with the person Julia Child and traverses outward.
And edge property for the know edges can give us additional information, such as when Julia Child met an author who lives in France, but starting the search to see who Julia Child knew in 1955 would not be performant.
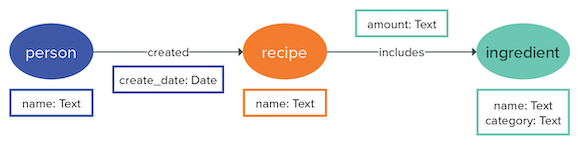
An edge property is often the only choice. For instance, look at an ingredient that is included in a recipe.
Knowing the ingredients in a recipe is important, but the amount used is also critical.
One cup of salt instead of one teaspoon of salt will make a big difference in the results.
But an ingredient is used in many recipes, and each recipe has a specified amount.
In this case, adding the edge property amount is the right choice:
Properties with multiple values
Properties can have multiple values and are useful for storing similar information.
For instance, a nickname property can store all the nicknames that a person might have, or a email property can store all the various email addresses a person owns.
Consider how you will access data in your data model design when considering collections, tuples, and user-defined types (UDTs).
Properties associated with other properties
Collections, tuples, and UDTs are the best method of associating properties with other properties.
For instance, if you want to assign a person a badge that consists of the level and the date at which the badge was awarded, a map collection is an excellent choice.
A UDT is a good choice if a specific group of data is required, such as an address and multiple phone numbers for a home or business.
The UDT location_details is composed of the UDT address plus an additional property telephone List data type.
Edge directionality
Edge directionality can play a role in the performance of queries.
Edges are unidirectional by default to avoid the unfortunate possibility of super-nodes, nodes that have too many edges.
If your queries generally look to find the ingredients included_in a recipe, rather than what recipes use a specific ingredient, then designing the edge to connection from ingredient->recipe is the right choice.
If bidirectionality is required for particular edges, then the special indexing step inverse() can be used to create a materialized index to add the opposite direction edges.
Edge uniqueness
Edge uniqueness is required if multiple edges between two vertices is required.
For instance, if a person can review a recipe more than once, a property that will identify the unique instances of those edges must be created in the edge label schema.
An edge property review_date makes clear that different reviews can be made at different times, and should be a clustering key for the edge label reviewed.
Additionally, if a celebrity, or super-node is present with millions of incoming edges, the data model will benefit from breaking the incoming edges with an additional partition key and no indexing.
Indexes
Indexes play a significant role in making DSG queries performant.
Graph queries that must traverse the entire graph to find information will have poor performance, which explains why full-scan queries are disallowed in production environments.
DSG implements three types of indexes, materialized view indexes, secondary indexes, and search indexes to address these different aspects of query processing.
Indexes are used to find the starting point in a graph and involve finding a matching vertex or edge property value.
Queries that require indexes will not execute without an index unless a development bypass mechanism, like dev or g.with('allow-filtering') is used.
An index analyzer can be used to discover what indexes are required, by running the analyzer on any query. The analyzer results will return an index that can be applied or state that indexes required for the query already exist.
Complexity
Today, people publish their recipes online and in cookbooks. Restaurants create fixed price meals from recipes. Consumers review the recipes they try. The results are an intertwined graph of data.The additional vertices and edges that can be added to this graph are numerous. For instance, the gender of the recipe authors and reviewers can be included. Nutritional information for the ingredients can be derived from the calories for a recipe. The number of servings that a recipe makes is useful to cooks. The resulting web of data can grow quickly.
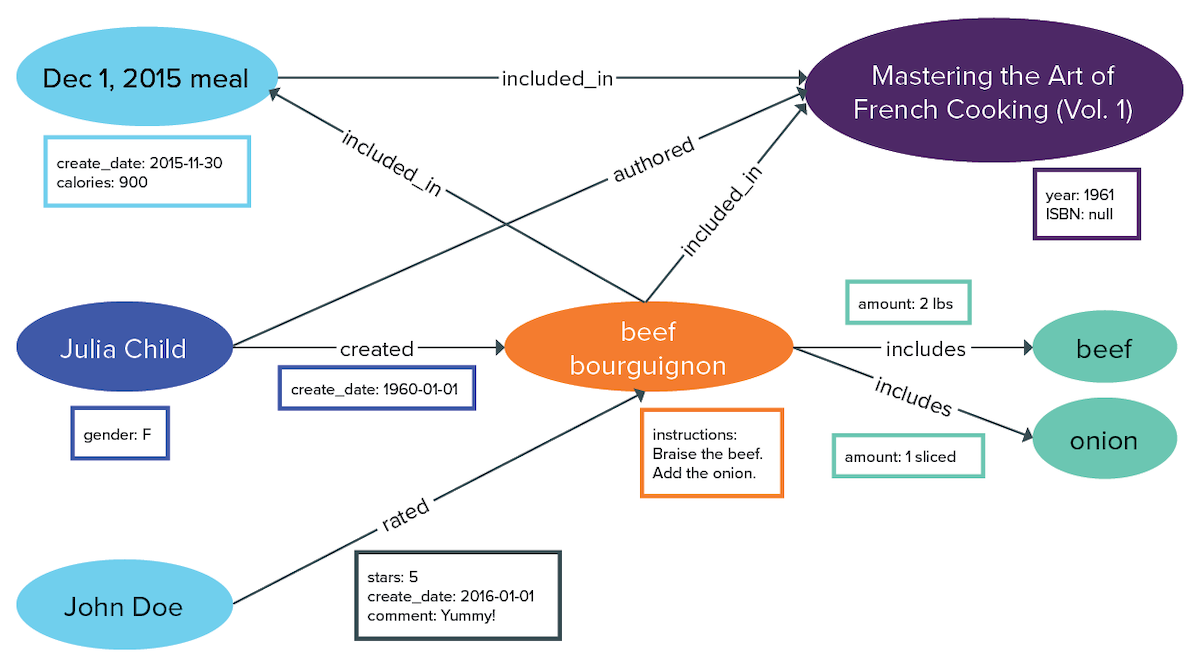
Add a hundred authors, a thousand recipes, ten thousand reviews, and the enormity of the graph becomes obvious. However, as you will see in later sections, DSG can transform complex searches and pattern matching into simple and powerful solutions.
The data model is the first step in creating a graph. Using the data model, a schema can be created that defines how DSG will store the data.
