Further data modeling concepts
Further data modeling concepts.
Graph data models can be expanded to encompass complex relationships.
The recipe data model can be modified to include new layers of data.
The whole graph can be digested better if subgraphs are considered.
For instance, let’s look at modifications to the vertex label ingredient.
Consider an ingredient. Many additional properties could be added to an ingredient:
-
category
vegetable, fruit, pasta, meat
-
nutritional value
% of vitamins, protein, carbohydrate, fat
-
calories
number of kcals

While it may seem simple to choose the property values for an ingredient, consider the complexity.
For instance, category seems straightforward.
Depending on the number of categories used to describe the ingredients, it can be more advantageous to create a vertex label or a property for category.
Each graph query must start with a vertex or edge label, not a vertex or edge property.
To ask the question "what ingredients are dairy products?", the dairy vertex requires one edge hop per ingredient to find all the ingredients categorized as dairy.
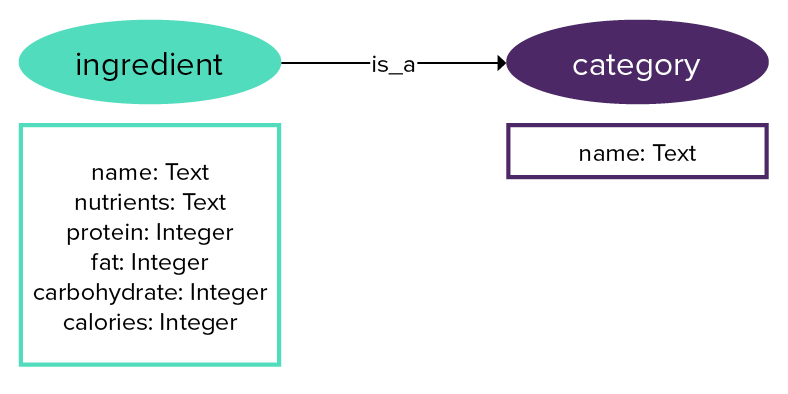
However, if too many ingredients are dairy, a supernode, defined as a node with too many incoming edges, can slow down queries that are searching for dairy ingredients.
Of course, an index on an ingredient category could mean that category is better as a property than as a vertex label.
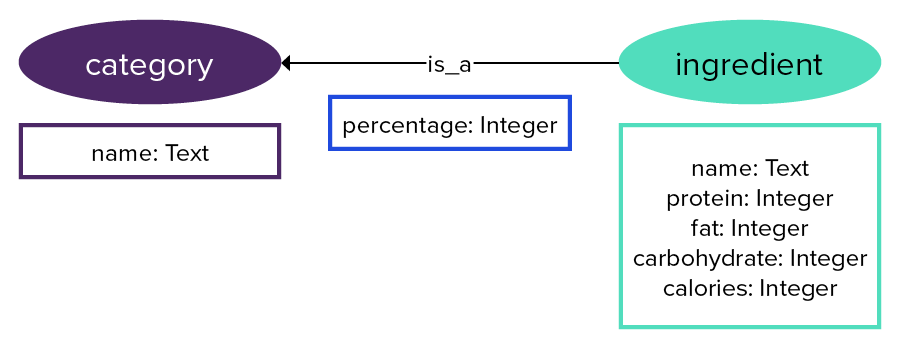
Nutrients are a set number of items, such as vitamin C, vitamin D, calcium, and sodium.
Creating a vertex label for nutrient and weighting the edges between ingredient and nutrient with the percentage adds another dimension to the graph.
Look at the relationships that result for just one ingredient if the nutrients are each created as a vertex label:
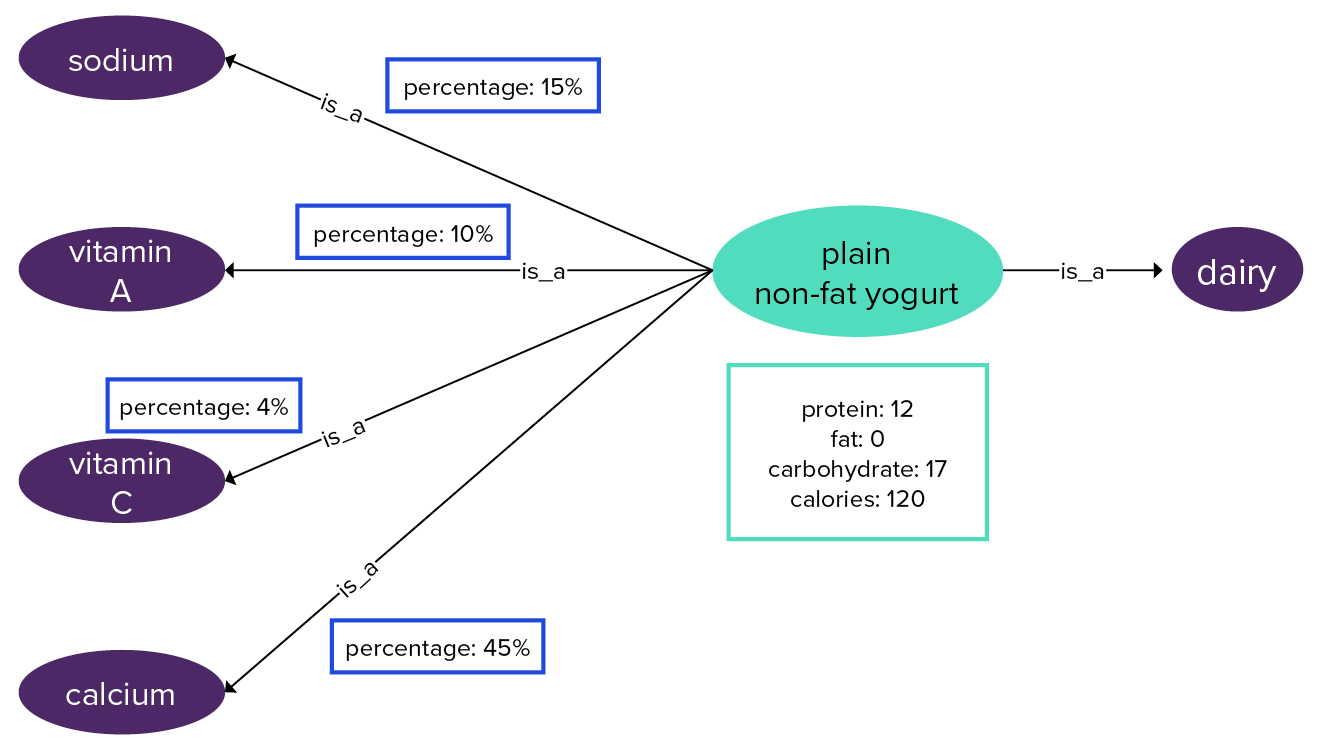
and imagine the graph resulting for even one hundred ingredients, let alone thousands of ingredients. Examine whether it is better to create a nutrient vertex label or nutrient vertex properties. The number of indexes on a single vertex label can cause poor performance, so a better choice is to use a collection, map, or user-defined type (UDT) to model the nutrients as vertex label properties.

Imagine the possibilities for applications built using the ingredient properties. Look in the refrigerator and discover that you have mushrooms and beef, and query the graph database to find a recipe to cook, such as Beef Stroganoff. With the coming possibility of tagged food in your refrigerator, you could even have your fridge tell you what’s for dinner tonight, given the items stored.
