Getting started - quick start with Gremlin console
Graph databases are useful for discovering simple and complex relationships between objects. Relationships are fundamental to how objects interact with one another and their environment. Graph databases are the perfect representation of the relationships between objects.
Graph databases consist of two elements:
- vertex
-
A vertex is an object, such as a person, location, automobile, recipe, or anything else you can think of as nouns.
- edge
-
An edge defines the relationship between two vertices. A person can create software, or an author can write a book. Think verbs when you are defining edges.
Both vertices and edges can have properties; for this reason, DSE Graph is classified as a property graph. The properties for both vertices and edges are an important element of storing and querying information from a property graph.
Property graphs are typically quite large, although the nature of querying the graph will vary depending on whether the graph has large numbers of vertices, edges, or both vertices and edges. To get started with graph database concepts, a "toy" graph is used for simplicity. The example used here explores the world of food.
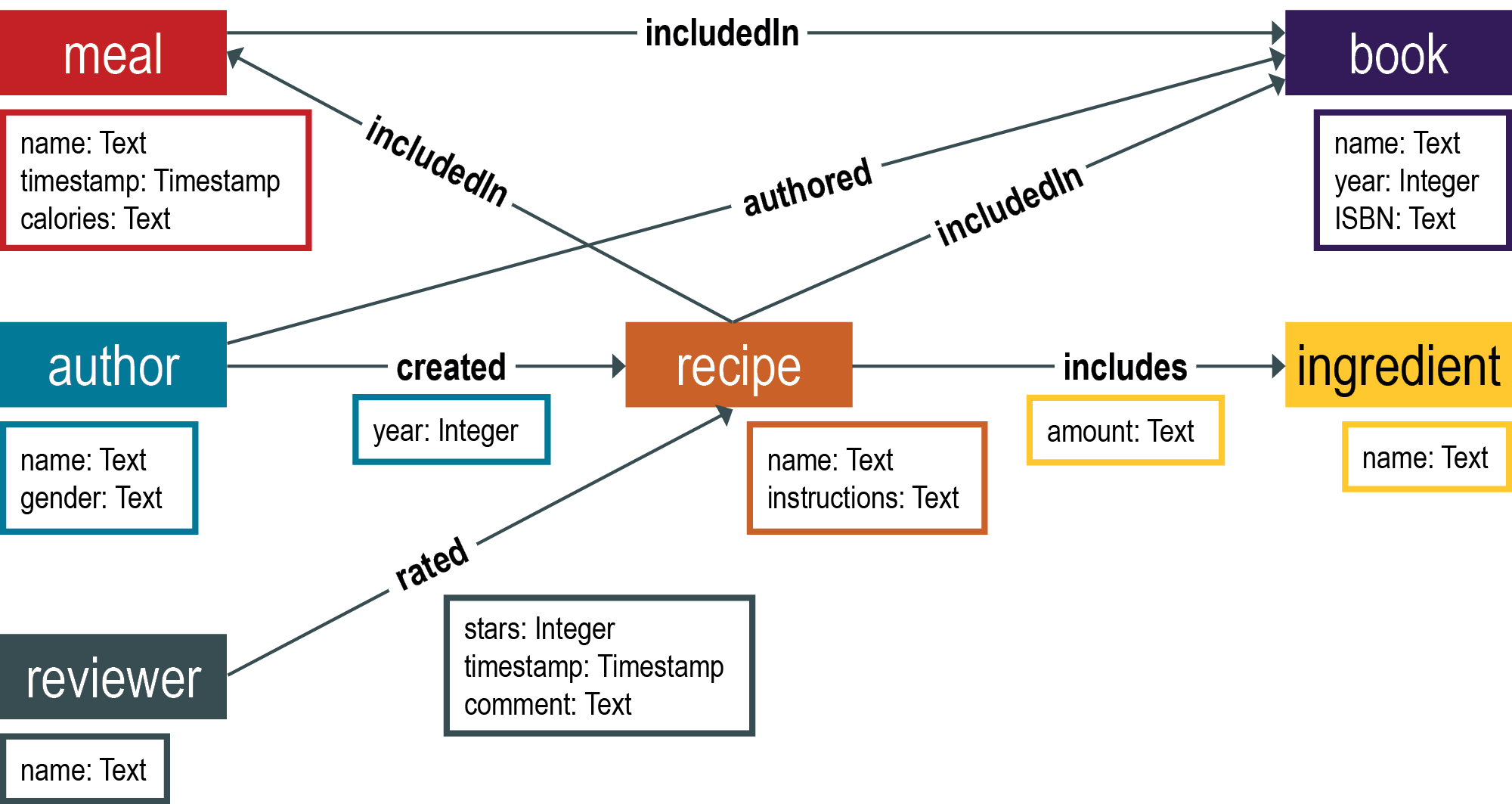
Elements are labeled to distinguish the type of vertices and edges in a graph database. A vertex that will hold information about an author is labeled author. An edge in the graph is labeled authored. Labels specify the types of vertices and edges that make up the graph. Specifying appropriate labels is an important step in graph data modeling.
Vertices and edges generally have properties. For instance, an author vertex can have a name. Gender and current job are examples of additional properties for an author vertex. Edges also have properties. A created edge can have a timestamp property that identifies when the adjoining recipe vertex was created.
Information in a graph database can be retrieved using graph traversals. Graph traversals "walk" a graph with a single or series of traversal steps that can define a starting point for a traversal and filter the results to find the answers to queries about the graph data.
In order to run graph traversals to retrieve information, data must first be inserted. The steps listed in this section will allow you to gain a rudimentary understanding of DSE Graph with a minimum amount of configuration and schema creation.
-
Start the Gremlin Console.
bin/dse gremlin-console\,,,/ (o o) -----oOOo-(3)-oOOo-----plugin activated: tinkerpop.tinkergraph plugin activated: tinkerpop.server plugin activated: tinkerpop.utilities ==>Connected - localhost/127.0.0.1:8182-[4edf75f9-ed27-4add-a350-172abe37f701] ==>Set remote timeout to 2147483647ms ==>All scripts will now be sent to Gremlin Server - [localhost/127.0.0.1:8182]-[4edf75f9-ed27-4add-a350-172abe37f701] - type ':remote console' to return to local mode gremlin>Gremlin console sends all commands typed at the prompt to the Gremlin Server that will process the commands. DSE Graph runs a Gremlin Server tinkerpop.server on each DSE node. Gremlin console automatically connects to the Gremlin Server. A graph must be created that is stored as one graph instance per DSE database keyspace.
The Gremlin console runs in remote mode automatically, processing commands on the Gremlin server. The Gremlin console by default opens a session to run commands on the remote server. The Gremlin console can be switched to run commands locally using:
:remote consoleAll commands will need to be submitted remotely once this command is run. Using the command again will switch the context back to the Gremlin server.
-
Create a graph to hold the data. The system commands are used to run commands that affect graphs in DSE Graph.
system.graph('quickstart').create()==>nullOnce a graph exists, a graph traversal g is configured that will allow graph traversals to be executed. Graph traversals are used to query the graph data and return results. A graph traversal is bound to a specific traversal source which is the standard OLTP traversal engine.
-
To list all graphs previously created, use:
system.graphs()==>quickstart ==>anotherTest -
Configure a graph traversal
gto use the default graph traversal setting, which isquickstart.g. This step will also create an implicitgraphobject.:remote config alias g quickstart.g==>g=quickstart.gThis command is not available if a graph traversal is aliased with the
:remote config alias g some_graph.gcommand. In order to access the system command, reset the alias with:remote config alias resetThe graph commands usually add vertices or edges to the database, or get other graph information. The g commands generally do queries to obtain results.
-
First, set the schema mode to Development. Development is a more lenient mode that allows schema to be added at any time during testing. Also allow full scans for testing purposes to inspect the data with broad graph traversals. For production, Production schema mode should be set to prevent interactive schema changes that can lead to anomalous behavior, and full scans should be turned off.
schema.config().option('graph.schema_mode').set('Development') schema.config().option('graph.allow_scan').set('true') -
Check the number of vertices that exist in the graph using the traversal step
count(). There should currently be none, because we have not added data yet. A graph traversal g is chained with V() to get all vertices and count() to get the number of vertices.g.V().count()==>0Be aware that queries doing full graph scans with
g.V().count()should not be run on large graphs! If multiple DSE nodes are configured, this traversal step intensively walks all partitions on all nodes in the cluster that have graph data. -
A simple example is composed of two vertices, one author (Julia Child) and one book (The Art of French Cooking, Vol. 1) with an edge between them to identify that Julia Child authored that book. Without creating any schema, the three elements can be created as shown below. However, DSE Graph makes a best guess at the schema, as we’ll talk about below.
-
First, let’s make a vertex for Julia Child. The vertex label is author, and two property key-value pairs are created for name and gender. Note the use of label to designate the key for a key-value pair that sets the vertex label. Run the command and look at the results using the buttons to display the Raw, Table, and Graph views.
juliaChild = graph.addVertex(label,'author', 'name','Julia Child', 'gender','F')==>v[{~label=author, member_id=0, community_id=1080937600}]Each view displays the same information:
-
an auto-generated id, consisting of a
member_id,community_idand label-
The
member_idandcommunity_idare used for grouping vertices within the graph (more information) + [NOTE] ==== Standard auto-generated ids are deprecated with DSE 6.0. Custom ids will undergo changes, and specifying vertex ids withpartitionKeyandclusteringKeywill likely become the normal method. ====As you will see in the next command, a property key can be reused for different types of information. While properties are “global” in the sense that they are used with multiple vertex labels, it is important to understand that when specifying a property in a graph traversal, it is always used in conjunction with a vertex label.
Run the next command to create a book vertex. Don’t run any command twice, or you’ll create a duplicate in the graph!
-
-
-
Create a book in the graph.
artOfFrenchCookingVolOne = graph.addVertex(label, 'book','name', 'The Art of French Cooking, Vol. 1', 'year', 1961)==>v[{~label=book, member_id=1, community_id=1080937600}]As with the author vertex, you can see the id information about the book vertex created.
Run the next two commands. The first command creates the edge between the author and book vertices. The second command is a graph traversal that retrieves the two vertices using
valueMap(). UsevalueMap()to check author vertex property key information. The traversalgchecks all vertices with the traversal stepV(), and prints out a key-value listing of the property values for each vertex using the traversal stepvalueMap(). -
Create an edge and display the vertex data.
juliaChild.addEdge('authored', artOfFrenchCookingVolOne) g.V().valueMap()juliaChild.addEdge('authored', artOfFrenchCookingVolOne) ==>e[{out_vertex={~label=author, member_id=0, community_id=1080937600}, local_id=6bd73210-0e70-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=1, community_id=1080937600}, ~type=authored}][{~label=author, member_id=0, community_id=1080937600}-authored->{~label=book, member_id=1, community_id=1080937600}] g.V().valueMap() ==>{gender=[F], name=[Julia Child]} ==>{name=[The Art of French Cooking, Vol. 1], timestamp=[1961]}Using
valueMap()without specifying properties can result in slow query latencies, if a large number of property keys exist for the queried vertex or edge. Specific properties can be specified, such asvalueMap('name').We now have data! The key-value pairs identify the property key and its value for name and gender for the author vertex created, as well as the name and timestamp for the book vertex created.
-
A graph traversal that is a basic starting point for more complex traversal use the
has()step along with the vertex labelauthorand the propertyname = Julia Childto identify a particular vertex. This common graph traversal is used because it narrows the search of the graph with specific information.g.V().has('author', 'name', 'Julia Child')==>v[{~label=author, member_id=0, community_id=1080937600}]The id is automatically generated and consists of a vertex label and two components associated with the location of the vertex within the graph. The Anatomy of a Graph Traversal explains the id components.
-
If only the value for a particular property key is desired, the traversal step
values()step is used. This example below gets thenameof all vertices.g.V().values('name')Only two vertices exists, so two results are written. If multiple vertices exist, the traversal step returns results for all vertices with a
name.==>Julia Child ==>The Art of French Cooking, Vol. 1 -
Edge information can also be retrieved. The next command filters all edges to find those with an edge label
authored. The edge information displays details about the incoming and outgoing vertices as well as edge parametersid,label, andtype.g.E().hasLabel('authored')==>e[{out_vertex={~label=author, member_id=0, community_id=1080937600}, local_id=6bd73210-0e70-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=1, community_id=1080937600}, ~type=authored}] [{~label=author, member_id=0, community_id=1080937600}-authored->{~label=book, member_id=1, community_id=1080937600}] -
The traversal step
count()is useful for counting both the number of vertices and the number of edges. To count edges, useE()rather thanV(). You should have one edge.g.E().count()==>1 -
Re-running the vertex count traversal done at the beginning of this tutorial should now yield two vertices.
g.V().count()==>2 -
Before adding more data to the graph, let’s stop and talk about schema. Schema is used to define the possible properties and their data types that will be used in the graph. These properties are then used in the definitions of vertex labels and edge labels. The last critical step in schema creation is index creation. Indexes play an important role in making graph traversals efficient and fast.
More information can be found in the documents about creating schema and creating indexes.
First, let’s create schema for the property keys. In the next two cells, the first command clears the schema that was set when we created the first two vertices and edge. After the schema creation is completed, you enter data for those elements again in a longer script.
DSE Graph has two schema modes, Production and Development. In Production mode, all schema must be identified before data is entered. In Development mode, schema can be created after data is entered.
-
Clear the previous schema. A return value of null means that the command is successful.
schema.clear()==>null -
Create the property keys.
// Property Keys // Check for previous creation of property key with ifNotExists() schema.propertyKey('name').Text().ifNotExists().create() schema.propertyKey('gender').Text().create() schema.propertyKey('instructions').Text().create() schema.propertyKey('category').Text().create() schema.propertyKey('year').Int().create() schema.propertyKey('timestamp').Timestamp().create() schema.propertyKey('ISBN').Text().create() schema.propertyKey('calories').Int().create() schema.propertyKey('amount').Text().create() schema.propertyKey('stars').Int().create() // single() is optional, as it is the default schema.propertyKey('comment').Text().single().create() // Example of a multiple property that can have several values // schema.propertyKey('nickname').Text().multiple().create() // Next 2 lines define two properties, then create a meta-property 'livedIn' on 'country' // A meta-property is a property of a property // EX: 'livedIn': '1999-2005' 'country': 'Belgium' schema.propertyKey('livedIn').Text().create() schema.propertyKey('country').Text().multiple().properties('livedIn').create()// A series of null returns will mark the successful completion of all property key creation ==>nullEach property must be defined with a data type. DSE Graph data types are aligned with the DSE database data types. The data types used here are Text, Int, and Timestamp. By default, properties have single cardinality, but can be defined with multiple cardinality. Multiple cardinality allows more than one value to be assigned to a property.
In addition, properties can have their own properties, or meta-properties. Meta-properties can only be nested one deep, and are useful for keying information to an individual property. Notice that property keys can be created with an additional method
ifNotExists()to prevent overwriting a definition that may already exist. After property keys are created, vertex labels and edge labels can be defined. -
Create vertex labels and edge labels.
// Vertex Labels schema.vertexLabel('author').ifNotExists().create() schema.vertexLabel('recipe').create() // Example of creating vertex label with properties // schema.vertexLabel('recipe').properties('name','instructions').create() // Example of adding properties to a previously created vertex label // schema.vertexLabel('recipe').properties('name','instructions').add() schema.vertexLabel('ingredient').create() schema.vertexLabel('book').create() schema.vertexLabel('meal').create() schema.vertexLabel('reviewer').create() // Example of custom vertex id: // schema.propertyKey('city_id').Int().create() // schema.propertyKey('sensor_id').Uuid().create() // schema().vertexLabel('FridgeSensor').partitionKey('city_id').clusteringKey('sensor_id').create() // Edge Labels schema.edgeLabel('authored').ifNotExists().create() schema.edgeLabel('created').create() schema.edgeLabel('includes').create() schema.edgeLabel('includedIn').create() schema.edgeLabel('rated').connection('reviewer','recipe').create()// A series of null returns will mark the successful completion of all vertex label and edge label creation ==>nullThe schema for vertex labels defines the label type, and optionally defines the properties associated with the vertex label. There are two different methods for defining the association of the properties with vertex labels, either during creation, or by adding them after vertex label addition. The
ifNotExists()method can be used for any schema creation.DSE Graph limits the number of vertex labels to 200 per graph.
Vertex ids are automatically generated, but custom vertex ids can be created if necessary. This custom vertex id example is explained in further detail in the documentation, but note that partition keys and clustering keys can be defined.
The schema for edge labels defines the label type, and optionally defines the two vertex labels that are connected by the edge label with
connection(). Theratededge label defines edges between adjacent vertices with the outgoing vertex labelreviewerand the incoming vertex labelrecipe. By default, edges have multiple cardinality, but can be defined with single cardinality. Multiple cardinality allows more than one edge with differing property values but the same edge label to be assigned. -
Create the indexes.
// Vertex Indexes // Secondary schema.vertexLabel('author').index('byName').secondary().by('name').add() // Materialized schema.vertexLabel('recipe').index('byRecipe').materialized().by('name').add() schema.vertexLabel('meal').index('byMeal').materialized().by('name').add() schema.vertexLabel('ingredient').index('byIngredient').materialized().by('name').add() schema.vertexLabel('reviewer').index('byReviewer').materialized().by('name').add() // Search // schema.vertexLabel('recipe').index('search').search().by('instructions').asText().add() // schema.vertexLabel('recipe').index('search').search().by('instructions').asString().add() // If more than one property key is search indexed // schema.vertexLabel('recipe').index('search').search().by('instructions').asText().by('category').asString().add() // Property index using meta-property 'livedIn': schema.vertexLabel('author').index('byLocation').property('country').by('livedIn').add() // Edge Index schema.vertexLabel('reviewer').index('ratedByStars').outE('rated').by('stars').add()// A series of null returns will mark the successful completion of all index creation ==>nullIndexing is a complex and highly important topic. Here, several types of indexes are created. Briefly, secondary and materialized indexes are two types of indexes that use DSE database built-in indexing. Search indexes use DSE Search which is Solr-based. Only one search index per vertex label is allowed, but multiple properties can be included. Property indexes allow meta-properties indexed. Edge indexes allow properties on edges to be indexed. Note that indexes are added with
add()to previously created vertex labels. After running all the cells to create the schema, examine the schema with the following command. -
Examine the schema.
schema.describe()==>schema.propertyKey("instructions").Text().single().create() schema.propertyKey("livedIn").Text().single().create() schema.propertyKey("country").Text().multiple().properties("livedIn").create() schema.propertyKey("amount").Text().single().create() schema.propertyKey("gender").Text().single().create() schema.propertyKey("year").Int().single().create() schema.propertyKey("calories").Int().single().create() schema.propertyKey("stars").Int().single().create() schema.propertyKey("ISBN").Text().single().create() schema.propertyKey("name").Text().single().create() schema.propertyKey("comment").Text().single().create() schema.propertyKey("category").Text().single().create() schema.propertyKey("timestamp").Timestamp().single().create() schema.edgeLabel("authored").multiple().create() schema.edgeLabel("rated").multiple().properties("stars").create() schema.edgeLabel("includedIn").multiple().create() schema.edgeLabel("created").multiple().create() schema.edgeLabel("includes").multiple().create() schema.vertexLabel("meal").properties("name").create() schema.vertexLabel("meal").index("byMeal").materialized().by("name").add() schema.vertexLabel("ingredient").properties("name").create() schema.vertexLabel("ingredient").index("byIngredient").materialized().by("name").add() schema.vertexLabel("author").properties("country", "name").create() schema.vertexLabel("author").index("byName").secondary().by("name").add() schema.vertexLabel("author").index("byLocation").property("country").by("livedIn").add() schema.vertexLabel("book").create() schema.vertexLabel("recipe").properties("name").create() schema.vertexLabel("recipe").index("byRecipe").materialized().by("name").add() schema.vertexLabel("reviewer").properties("name").create() schema.vertexLabel("reviewer").index("byReviewer").materialized().by("name").add() schema.vertexLabel("reviewer").index("ratedByStars").outE("rated").by("stars").add() schema.edgeLabel("rated").connection("reviewer", "recipe").add()The
schema.describe()command will display schema that can be used to re-create the schema entered. If you enter data without creating schema, this command verifies the data types set for each property.Currently, in DSE Graph, schema once created cannot be modified. Additional properties, vertex labels, edge labels, and indexes can be created, but the data type of a property, for instance, cannot be changed. While entering data without schema creation is handy while developing and learning, it is strongly recommended against for actual applications. As a reminder, Production mode disallows schema creation once data is loaded.
-
Should you wish to find only the schema for a particular type of item in the
describe()listing, additional steps can split the output per newline and grep for a string as shown for theindex. Gremlin as shown in this notebook uses Groovy, so any Groovy commands manipulate graph traversals.schema.describe().split('\n').grep(~/.*index.*/)==>schema.vertexLabel("meal").index("byMeal").materialized().by("name").add() ==>schema.vertexLabel("ingredient").index("byIngredient").materialized().by("name").add() ==>schema.vertexLabel("author").index("byName").secondary().by("name").add() ==>schema.vertexLabel("author").index("byLocation").property("country").by("livedIn").add() ==>schema.vertexLabel("recipe").index("byRecipe").materialized().by("name").add() ==>schema.vertexLabel("reviewer").index("byReviewer").materialized().by("name").add() ==>schema.vertexLabel("reviewer").index("ratedByStars").outE("rated").by("stars").add() -
Now that schema is created, add more vertices and edges using the following script. To explore more connections in the recipe data model, more vertices and edges are input into the graph. Create a script file, generateRecipe.groovy, with the information shown below.Note the first command,
g.V().drop().iterate(); this command drop all vertex and edge data from the graph before reading in new data.// Add all vertices and edges for Recipe g.V().drop().iterate() // author vertices juliaChild = graph.addVertex(label, 'author', 'name','Julia Child', 'gender', 'F') simoneBeck = graph.addVertex(label, 'author', 'name', 'Simone Beck', 'gender', 'F') louisetteBertholie = graph.addVertex(label, 'author', 'name', 'Louisette Bertholie', 'gender', 'F') patriciaSimon = graph.addVertex(label, 'author', 'name', 'Patricia Simon', 'gender', 'F') aliceWaters = graph.addVertex(label, 'author', 'name', 'Alice Waters', 'gender', 'F') patriciaCurtan = graph.addVertex(label, 'author', 'name', 'Patricia Curtan', 'gender', 'F') kelsieKerr = graph.addVertex(label, 'author', 'name', 'Kelsie Kerr', 'gender', 'F') fritzStreiff = graph.addVertex(label, 'author', 'name', 'Fritz Streiff', 'gender', 'M') emerilLagasse = graph.addVertex(label, 'author', 'name', 'Emeril Lagasse', 'gender', 'M') jamesBeard = graph.addVertex(label, 'author', 'name', 'James Beard', 'gender', 'M') // book vertices artOfFrenchCookingVolOne = graph.addVertex(label, 'book', 'name', 'The Art of French Cooking, Vol. 1', 'year', 1961) simcasCuisine = graph.addVertex(label, 'book', 'name', "Simca's Cuisine: 100 Classic French Recipes for Every Occasion", 'year', 1972, 'ISBN', '0-394-40152-2') frenchChefCookbook = graph.addVertex(label, 'book', 'name','The French Chef Cookbook', 'year', 1968, 'ISBN', '0-394-40135-2') artOfSimpleFood = graph.addVertex(label, 'book', 'name', 'The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution', 'year', 2007, 'ISBN', '0-307-33679-4') // recipe vertices beefBourguignon = graph.addVertex(label, 'recipe', 'name', 'Beef Bourguignon', 'instructions', 'Braise the beef. Saute the onions and carrots. Add wine and cook in a dutch oven at 425 degrees for 1 hour.') ratatouille = graph.addVertex(label, 'recipe', 'name', 'Rataouille', 'instructions', 'Peel and cut the eggplant. Make sure you cut eggplant into lengthwise slices that are about 1-inch wide, 3-inches long, and 3/8-inch thick') saladeNicoise = graph.addVertex(label, 'recipe', 'name', 'Salade Nicoise', 'instructions', 'Take a salad bowl or platter and line it with lettuce leaves, shortly before serving. Drizzle some olive oil on the leaves and dust them with salt.') wildMushroomStroganoff = graph.addVertex(label, 'recipe', 'name', 'Wild Mushroom Stroganoff', 'instructions', 'Cook the egg noodles according to the package directions and keep warm. Heat 1 1/2 tablespoons of the olive oil in a large saute pan over medium-high heat.') spicyMeatloaf = graph.addVertex(label, 'recipe', 'name', 'Spicy Meatloaf', 'instructions', 'Preheat the oven to 375 degrees F. Cook bacon in a large skillet over medium heat until very crisp and fat has rendered, 8-10 minutes.') oystersRockefeller = graph.addVertex(label, 'recipe', 'name', 'Oysters Rockefeller', 'instructions', 'Saute the shallots, celery, herbs, and seasonings in 3 tablespoons of the butter for 3 minutes. Add the watercress and let it wilt.') carrotSoup = graph.addVertex(label, 'recipe', 'name', 'Carrot Soup', 'instructions', 'In a heavy-bottomed pot, melt the butter. When it starts to foam, add the onions and thyme and cook over medium-low heat until tender, about 10 minutes.') roastPorkLoin = graph.addVertex(label, 'recipe', 'name', 'Roast Pork Loin', 'instructions', 'The day before, separate the meat from the ribs, stopping about 1 inch before the end of the bones. Season the pork liberally inside and out with salt and pepper and refrigerate overnight.') // ingredients vertices beef = graph.addVertex(label, 'ingredient', 'name', 'beef') onion = graph.addVertex(label, 'ingredient', 'name', 'onion') mashedGarlic = graph.addVertex(label, 'ingredient', 'name', 'mashed garlic') butter = graph.addVertex(label, 'ingredient', 'name', 'butter') tomatoPaste = graph.addVertex(label, 'ingredient', 'name', 'tomato paste') eggplant = graph.addVertex(label, 'ingredient', 'name', 'eggplant') zucchini = graph.addVertex(label, 'ingredient', 'name', 'zucchini') oliveOil = graph.addVertex(label, 'ingredient', 'name', 'olive oil') yellowOnion = graph.addVertex(label, 'ingredient', 'name', 'yellow onion') greenBean = graph.addVertex(label, 'ingredient', 'name', 'green beans') tuna = graph.addVertex(label, 'ingredient', 'name', 'tuna') tomato = graph.addVertex(label, 'ingredient', 'name', 'tomato') hardBoiledEgg = graph.addVertex(label, 'ingredient', 'name', 'hard-boiled egg') eggNoodles = graph.addVertex(label, 'ingredient', 'name', 'egg noodles') mushroom = graph.addVertex(label, 'ingredient', 'name', 'mushrooms') bacon = graph.addVertex(label, 'ingredient', 'name', 'bacon') celery = graph.addVertex(label, 'ingredient', 'name', 'celery') greenBellPepper = graph.addVertex(label, 'ingredient', 'name', 'green bell pepper') groundBeef = graph.addVertex(label, 'ingredient', 'name', 'ground beef') porkSausage = graph.addVertex(label, 'ingredient', 'name', 'pork sausage') shallot = graph.addVertex(label, 'ingredient', 'name', 'shallots') chervil = graph.addVertex(label, 'ingredient', 'name', 'chervil') fennel = graph.addVertex(label, 'ingredient', 'name', 'fennel') parsley = graph.addVertex(label, 'ingredient', 'name', 'parsley') oyster = graph.addVertex(label, 'ingredient', 'name', 'oyster') pernod = graph.addVertex(label, 'ingredient', 'name', 'Pernod') thyme = graph.addVertex(label, 'ingredient', 'name', 'thyme') carrot = graph.addVertex(label, 'ingredient', 'name', 'carrots') chickenBroth = graph.addVertex(label, 'ingredient', 'name', 'chicken broth') porkLoin = graph.addVertex(label, 'ingredient', 'name', 'pork loin') redWine = graph.addVertex(label, 'ingredient', 'name', 'red wine') // meal vertices SaturdayFeast = graph.addVertex(label, 'meal', 'name', 'Saturday Feast', 'timestamp', '2015-11-30', 'calories', 1000) EverydayDinner = graph.addVertex(label, 'meal', 'name', 'EverydayDinner', 'timestamp', '2016-01-14', 'calories', 600) JuliaDinner = graph.addVertex(label, 'meal', 'name', 'JuliaDinner', 'timestamp', '2016-01-14', 'calories', 900) // author-book edges juliaChild.addEdge('authored', artOfFrenchCookingVolOne) simoneBeck.addEdge('authored', artOfFrenchCookingVolOne) louisetteBertholie.addEdge('authored', artOfFrenchCookingVolOne) simoneBeck.addEdge('authored', simcasCuisine) patriciaSimon.addEdge('authored', simcasCuisine) juliaChild.addEdge('authored', frenchChefCookbook) aliceWaters.addEdge('authored', artOfSimpleFood) patriciaCurtan.addEdge('authored', artOfSimpleFood) kelsieKerr.addEdge('authored', artOfSimpleFood) fritzStreiff.addEdge('authored', artOfSimpleFood) // author - recipe edges juliaChild.addEdge('created', beefBourguignon, 'year', 1961) juliaChild.addEdge('created', ratatouille, 'year', 1965) juliaChild.addEdge('created', saladeNicoise, 'year', 1962) emerilLagasse.addEdge('created', wildMushroomStroganoff, 'year', 2003) emerilLagasse.addEdge('created', spicyMeatloaf, 'year', 2000) aliceWaters.addEdge('created', carrotSoup, 'year', 1995) aliceWaters.addEdge('created', roastPorkLoin, 'year', 1996) jamesBeard.addEdge('created', oystersRockefeller, 'year', 1970) // recipe - ingredient edges beefBourguignon.addEdge('includes', beef, 'amount', '2 lbs') beefBourguignon.addEdge('includes', onion, 'amount', '1 sliced') beefBourguignon.addEdge('includes', mashedGarlic, 'amount', '2 cloves') beefBourguignon.addEdge('includes', butter, 'amount', '3.5 Tbsp') beefBourguignon.addEdge('includes', tomatoPaste, 'amount', '1 Tbsp') ratatouille.addEdge('includes', eggplant, 'amount', '1 lb') ratatouille.addEdge('includes', zucchini, 'amount', '1 lb') ratatouille.addEdge('includes', mashedGarlic, 'amount', '2 cloves') ratatouille.addEdge('includes', oliveOil, 'amount', '4-6 Tbsp') ratatouille.addEdge('includes', yellowOnion, 'amount', '1 1/2 cups or 1/2 lb thinly sliced') saladeNicoise.addEdge('includes', oliveOil, 'amount', '2-3 Tbsp') saladeNicoise.addEdge('includes', greenBean, 'amount', '1 1/2 lbs blanched, trimmed') saladeNicoise.addEdge('includes', tuna, 'amount', '8-10 ozs oil-packed, drained and flaked') saladeNicoise.addEdge('includes', tomato, 'amount', '3 or 4 red, peeled, quartered, cored, and seasoned') saladeNicoise.addEdge('includes', hardBoiledEgg, 'amount', '8 halved lengthwise') wildMushroomStroganoff.addEdge('includes', eggNoodles, 'amount', '16 ozs wmyIde') wildMushroomStroganoff.addEdge('includes', mushroom, 'amount', '2 lbs wild or exotic, cleaned, stemmed, and sliced') wildMushroomStroganoff.addEdge('includes', yellowOnion, 'amount', '1 cup thinly sliced') spicyMeatloaf.addEdge('includes', bacon, 'amount', '3 ozs diced') spicyMeatloaf.addEdge('includes', onion, 'amount', '2 cups finely chopped') spicyMeatloaf.addEdge('includes', celery, 'amount', '2 cups finely chopped') spicyMeatloaf.addEdge('includes', greenBellPepper, 'amount', '1/4 cup finely chopped') spicyMeatloaf.addEdge('includes', porkSausage, 'amount', '3/4 lbs hot') spicyMeatloaf.addEdge('includes', groundBeef, 'amount', '1 1/2 lbs chuck') oystersRockefeller.addEdge('includes', shallot, 'amount', '1/4 cup chopped') oystersRockefeller.addEdge('includes', celery, 'amount', '1/4 cup chopped') oystersRockefeller.addEdge('includes', chervil, 'amount', '1 tsp') oystersRockefeller.addEdge('includes', fennel, 'amount', '1/3 cup chopped') oystersRockefeller.addEdge('includes', parsley, 'amount', '1/3 cup chopped') oystersRockefeller.addEdge('includes', oyster, 'amount', '2 dozen on the half shell') oystersRockefeller.addEdge('includes', pernod, 'amount', '1/3 cup') carrotSoup.addEdge('includes', butter, 'amount', '4 Tbsp') carrotSoup.addEdge('includes', onion, 'amount', '2 medium sliced') carrotSoup.addEdge('includes', thyme, 'amount', '1 sprig') carrotSoup.addEdge('includes', carrot, 'amount', '2 1/2 lbs, peeled and sliced') carrotSoup.addEdge('includes', chickenBroth, 'amount', '6 cups') roastPorkLoin.addEdge('includes', porkLoin, 'amount', '1 bone-in, 4-rib') roastPorkLoin.addEdge('includes', redWine, 'amount', '1/2 cup') roastPorkLoin.addEdge('includes', chickenBroth, 'amount', '1 cup') // book - recipe edges beefBourguignon.addEdge('includedIn', artOfFrenchCookingVolOne) saladeNicoise.addEdge('includedIn', artOfFrenchCookingVolOne) carrotSoup.addEdge('includedIn', artOfSimpleFood) // meal - recipe edges beefBourguignon.addEdge('includedIn', SaturdayFeast) carrotSoup.addEdge('includedIn', SaturdayFeast) oystersRockefeller.addEdge('includedIn', SaturdayFeast) carrotSoup.addEdge('includedIn', EverydayDinner) roastPorkLoin.addEdge('includedIn', EverydayDinner) beefBourguignon.addEdge('includedIn', JuliaDinner) saladeNicoise.addEdge('includedIn', JuliaDinner) // meal - book edges EverydayDinner.addEdge('includedIn', artOfSimpleFood) SaturdayFeast.addEdge('includedIn', simcasCuisine) JuliaDinner.addEdge('includedIn', artOfFrenchCookingVolOne) g.V()Run the script by loading it in Gremlin console:
:load /tmp/generateRecipe.groovyreplacing "/tmp" with the directory where you write the script.
// A series of returns for vertices and edges will mark the successful completion of the script // Sample vertex ==>v[{~label=author, member_id=0, community_id=1878171264}] // Sample edge ==>e[{out_vertex={~label=meal, member_id=27, community_id=1989847424}, local_id=545b88b0-0e7b-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=10, community_id=1878171264}, ~type=includedIn}] [{~label=meal, member_id=27, community_id=1989847424}-includedIn->{~label=book, member_id=10, community_id=1878171264}]The property
timestampis aTimestampdata type that corresponds to a valid DSE database timestamp data type. -
Run the vertex count again.
g.V().count()==>56A tool, graphloader, is also available for scripting data loading. See the graphloader documentation for information.
-
Exploring the graph with graph traversals can lead to interesting conclusions.
-
With several author vertices in the graph, a specific
namemust be given to find a particular vertex. This traversal gets the stored vertex information for the vertex thathasthenameofJulia Child. Note that the constraint that the vertex is an author is also included in thehasclause.g.V().has('author','name','Julia Child')==>v[{~label=author, member_id=0, community_id=1878171264}] -
In this next traversal,
has()gets the vertex information filtered withname = Julia Child. The traversal stepoutE()discovers the outgoing edges from that vertex with theauthoredlabel.g.V().has('name','Julia Child').outE('authored')The edge information is returned:
==>e[{out_vertex={~label=author, member_id=0, community_id=1878171264}, local_id=521f5450-0e7b-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=10, community_id=1878171264}, ~type=authored}][{~label=author, member_id=0, community_id=1878171264}-authored->{~label=book, member_id=10, community_id=1878171264}] ==>e[{out_vertex={~label=author, member_id=0, community_id=1878171264}, local_id=523155b0-0e7b-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=12, community_id=1878171264}, ~type=authored}] [{~label=author, member_id=0, community_id=1878171264}-authored->{~label=book, member_id=12, community_id=1878171264}] -
If instead, the query is seeking the books that all authors have written, the last example gets edges, but not the adjacent book vertices. Add a traversal step
inV()to find all the vertices that connect to the outgoing edges, then print the book titles of those vertices. Note how the chained traversal steps go from the vertices along outgoing edges to the adjacent vertices withV().outE().inV(). The outgoing edges are given a particular filter value, authored.g.V().outE('authored').inV().values('name')==>The Art of French Cooking, Vol. 1 ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The Art of French Cooking, Vol. 1 ==>The French Chef Cookbook ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The Art of French Cooking, Vol. 1 ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution -
Notice that the book titles are duplicated in the resulting list, because a listing is returned for each author. If a book has three authors, three listings are returned. The traversal step
dedup()can eliminate the duplication.g.V().outE('authored').inV().values('name').dedup()==>The Art of French Cooking, Vol. 1 ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The French Chef Cookbook ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution -
Refine the traversal by reinserting the
has()step for a particular author. Find all the books authored by Julia Child.g.V().has('name','Julia Child').outE('authored').inV().values('name')==>The Art of French Cooking, Vol. 1 ==>The French Chef Cookbook -
The last example and this example accomplish the same result. However, the number of traversal steps and the type of traversal steps can affect performance. The traversal step
outE()should be used if the edges are explicitly required. In this example, the edges are traversed to get information about connected vertices, but the edge information is not important to the query.g.V().has('name','Julia Child').out('authored').values('name')==>The Art of French Cooking, Vol. 1 ==>The French Chef CookbookThe traversal step
out()retrieves the connected book vertices based on the edge labelauthoredwithout retrieving the edge information. In a larger graph traversal, this subtle difference in the traversal can become a latency issue. -
Additional traversal steps continue to fine-tune the results. Adding another chained
hastraversal step finds only books authored by Julia Child that are published after 1967. This example also displays the use of thegt, or greater than function.g.V().has('name','Julia Child').out('authored').has('year', gt(1967)).values('name')==>The French Chef Cookbook -
When developing or testing, oftentimes a check of the number of vertices with each vertex label can confirm that data has been read. To find the number of vertices by vertex label, use the traversal step
label()followed by the traversal stepgroupCount(). The stepgroupCount()is useful for aggregating results from a previous step.g.V().label().groupCount()==>{meal=3, ingredient=31, author=10, book=4, recipe=8} -
Write your data to an output file to save or exchange information. A Gryo file is a binary format file that can be used to reload data to DSE Graph. In this next command, graph I/O is used to write the entire graph to a file. Other file formats can be written by substituting
gryo()withgraphml()orgraphson().graph.io(gryo()).writeGraph("/tmp/recipe.gryo")graph.io()is disabled in sandbox mode.==>null -
To load a Gryo file, use the
graphloader, after creating a mapping script:graphloader mappingGRYO.groovy -graph recipe -address localhostDetails about loading Gryo data are found in Loading Gryo Data, in Using DSE Graph Loader.
Further adventures in traversing can be found in Creating queries using traversals. If you want to explore various loading options, check out the DSE Graph Loader or Using DSE Graph.
