Hinted handoff: repair during write path
On occasion, a node becomes unresponsive while data is being written. Reasons for unresponsiveness include hardware problems, network issues, or overloaded nodes that experience long garbage collection (GC) pauses. By design, hinted handoff inherently allows DataStax Enterprise (DSE) to continue performing the same number of writes even when the cluster is operating at reduced capacity.
If the failure detector marks a node as down and hinted handoff is enabled in the cassandra.yaml file, the coordinator node stores missed writes as hints for a period of time.
In DSE 5.0 and later, the hint is stored in a local hints directory on each node for improved replay.
The hint consists of the following information:
-
Target ID for the downed node
-
Hint ID that is a time UUID for the data
-
Message ID that identifies the DSE version
-
The data itself as a blob
Hints are flushed to disk every ten seconds, reducing the staleness of the hints. When gossip discovers a node is back online, the coordinator replays each remaining hint to write the data to the newly-returned node, then deletes the hint file. If a node is down for longer than the value configured in the max_hint_window_in_ms parameter (three hours by default), the coordinator stops writing new hints.
The coordinator also checks every ten minutes for hints corresponding to writes that timed out during an outage too brief for the failure detector to notice through gossip.
If a replica node is overloaded or unavailable, and the failure detector has not yet marked the node as down, then expect most or all writes to that node to fail after the timeout triggered by write_request_timeout_in_ms (2 seconds by default).
The coordinator returns a TimeOutException error, and the write will fail.
However, a hint will be stored.
If several nodes experience brief outages simultaneously, substantial memory pressure can build up on the coordinator.
The coordinator tracks how many hints it is currently writing.
If the number of hints increases too much, the coordinator refuses writes and throws the OverloadedException error.
Consistency level ONE
The consistency level of a write request affects whether hints are written and a write request subsequently fails.
If the cluster consists of two nodes, A and B, with a replication factor of one, each row is stored on only one node.
Suppose node A is the coordinator, but goes down before a row K is written to it with a consistency level of ONE.
In this case, the consistency level specified cannot be met, and because node A is the coordinator, it cannot store a hint.
Node B cannot write the data because it has not received the data as the coordinator, and a hint has not been stored.
The coordinator checks the number of replicas that are up and will not attempt to write the hint if the consistency level specified by a client cannot be met.
In this case, the coordinator will return an UnavailableException error.
The write request fails and the hint is not written.
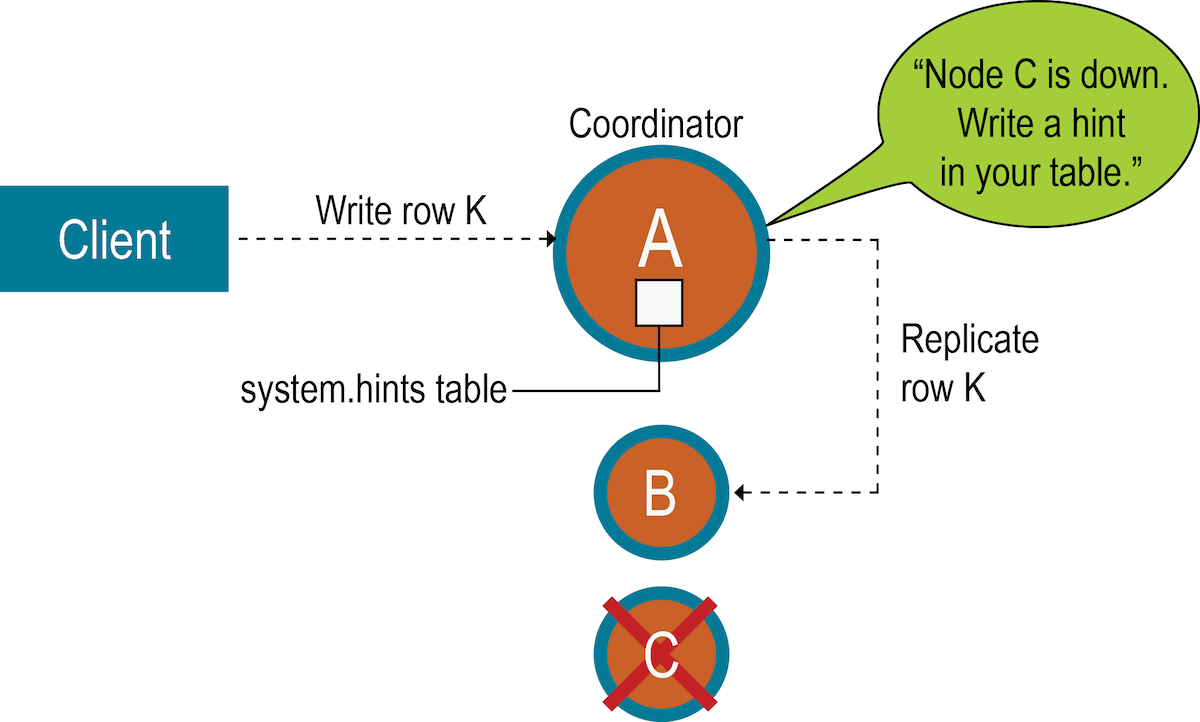
In general, the recommendation is to have enough nodes in the cluster and a replication factor sufficient to avoid write request failures. For example, consider a cluster consisting of three nodes, A, B, and C, with a replication factor of three. When a row K is written to the coordinator (node A in this case), even if node C is down, the consistency level of ONE or QUORUM can be met. Why? Both nodes A and B will receive the data, so the consistency level requirement is met. A hint is stored for node C and written when node C comes up. In the meantime, the coordinator can acknowledge that the write succeeded.
Consistency level ANY
For applications that want DSE to accept writes when all the normal replicas are down and consistency level ONE cannot be satisfied, the database provides consistency level ANY. ANY guarantees that the write is durable and readable after an appropriate replica target becomes available and receives the hint replay.
Nodes that die might have stored undelivered hints, because any node can be a coordinator. The data on the dead node will be stale after an extended outage. If a node has been down for an extended period of time, run a manual repair.
At first glance, it seems that hinted handoff eliminates the need for manual repair, but this is not true because hardware failure is inevitable and has the following ramifications:
-
Loss of the historical data necessary to tell the rest of the cluster exactly what data is missing.
-
Loss of hints-not-yet-replayed from requests that the failed node coordinated.
When removing a node from the cluster by decommissioning the node or by using the nodetool removenode command, the database automatically removes hints targeting the node that no longer exists and removes hints for dropped tables.
