Virtual nodes
Virtual nodes (vnodes) distribute data across nodes at a finer granularity than can be easily achieved using a single-token architecture. Virtual nodes simplify many tasks in DataStax Enterprise (DSE):
-
Tokens are automatically calculated and assigned to each node.
-
A cluster is automatically rebalanced when adding or removing nodes. When a node joins the cluster, it assumes responsibility for an even portion of data from the other nodes in the cluster. If a node fails, the load is spread evenly across other nodes in the cluster.
-
Rebuilding a dead node is faster because it involves every other node in the cluster.
-
The proportion of vnodes assigned to each machine in a cluster can be assigned, so smaller and larger computers can be used in building a cluster.
To convert an existing single-token architecture cluster to vnodes, see Enabling virtual nodes on an existing production cluster.
Distributing data using vnodes
Virtual nodes (vnodes) use consistent hashing to distribute data without requiring new token generation and assignment.
In single-token architecture clusters, you must calculate and assign a single token to each node in a cluster. Each token determines the node’s position in the cluster (or, ring) and its portion of data according to its hash value. Vnodes allow each node to own a large number of small partition ranges distributed throughout the cluster. Partition ranges are based on the partitioner.
Although vnodes use consistent hashing to distribute data, using them doesn’t require token generation and assignment.
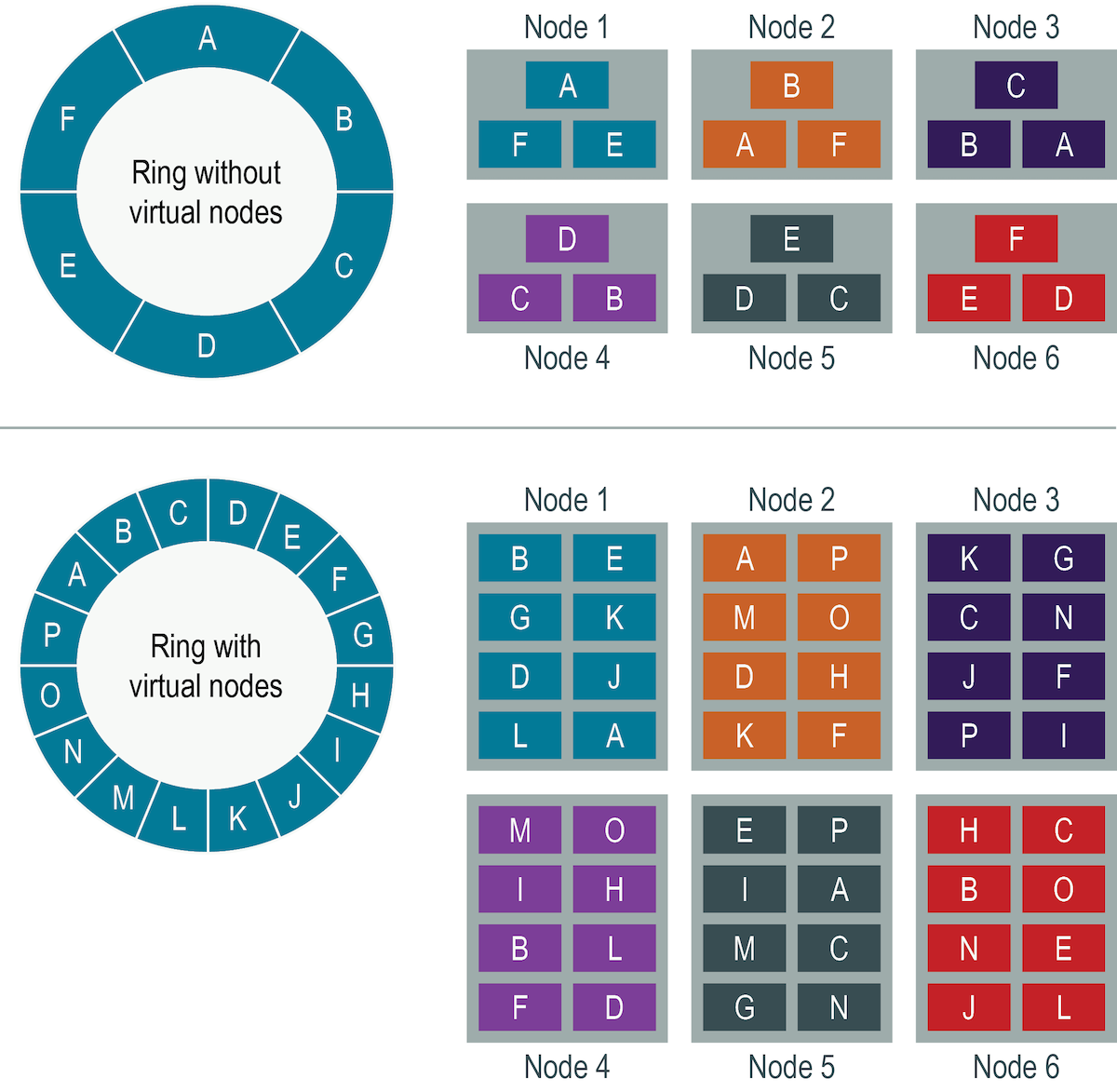
The top portion of the graphic shows a cluster without vnodes. In the single-token architecture paradigm, each node is assigned a single token that represents a location in the ring. Each node stores data determined by mapping the partition key to a token value within a range from the previous node to its assigned value. Each node also contains copies of each row from other nodes in the cluster. For example, if the replication factor is 3, range E replicates to nodes 5, 6, and 1. A node owns exactly one contiguous partition range in the ring space.
The bottom portion of the graphic shows a ring with vnodes. Within a cluster, vnodes are randomly selected and non-contiguous. The placement of a row is determined by the hash of the partition key within many smaller partition ranges belonging to each node.
|
While vnodes provide considerable operational benefits, it’s important to keep in mind that the number of vnodes assigned to a given node can impact cluster-wide operations. For instance, when the number of vnodes are increased, so are the number of repairs that need to be run during a repair cycle, thus increasing full cluster repair times. In addition, as the number of vnode token ranges increase, features such as DSE Search that span token ranges can see their performance suffer. |
