DataStax Graph: CQL as Graph
Graph databases are useful for discovering simple and complex relationships between objects. Relationships are fundamental to how objects interact with one another and their environment. Apache Cassandra® can store large distributed datasets, and DataStax Graph (DSG) is Graph for Cassandra. DSG allows Cassandra data to be traversed with complex queries that are not possible with the Cassandra Query Language (CQL) or are the equivalent of multiple SQL JOINS required in a traditional RDBMS.
This section explores DSG from a data model that leads to schema, inserting data, and simple queries that show off the power of graph databases. Starting with DSG 6.8, the same data can be queried with either Gremlin or CQL, increasing the useability of the same data for different uses. This section uses Cassandra Query Language (CQL) to create a graph and schema that can be queried with Gremlin. We’ll start by discussing what a graph database actually is.
Graph databases consist of three elements:
-
vertex
A vertex is an object, such as a person, location, automobile, recipe, or anything else you can think of as nouns.
-
edge
An edge defines the relationship between two vertices. A person can create software, or an author can write a book. Typically an edge is equivalent to a verb.
-
property
A key-value pair that describes some attribute of either a vertex or an edge. A property key is used to describe the key in the key-value pair.
Vertices, edges, and properties can have properties; for this reason, DataStax Graph is classified as a property graph. The properties for elements are an important element of storing and querying information in a property graph.
Property graphs are typically quite large, although the nature of querying the graph varies depending on whether the graph has large numbers of vertices, edges, or both vertices and edges. To get started with graph database concepts, a toy graph is used for simplicity. The example used here explores the world of food.
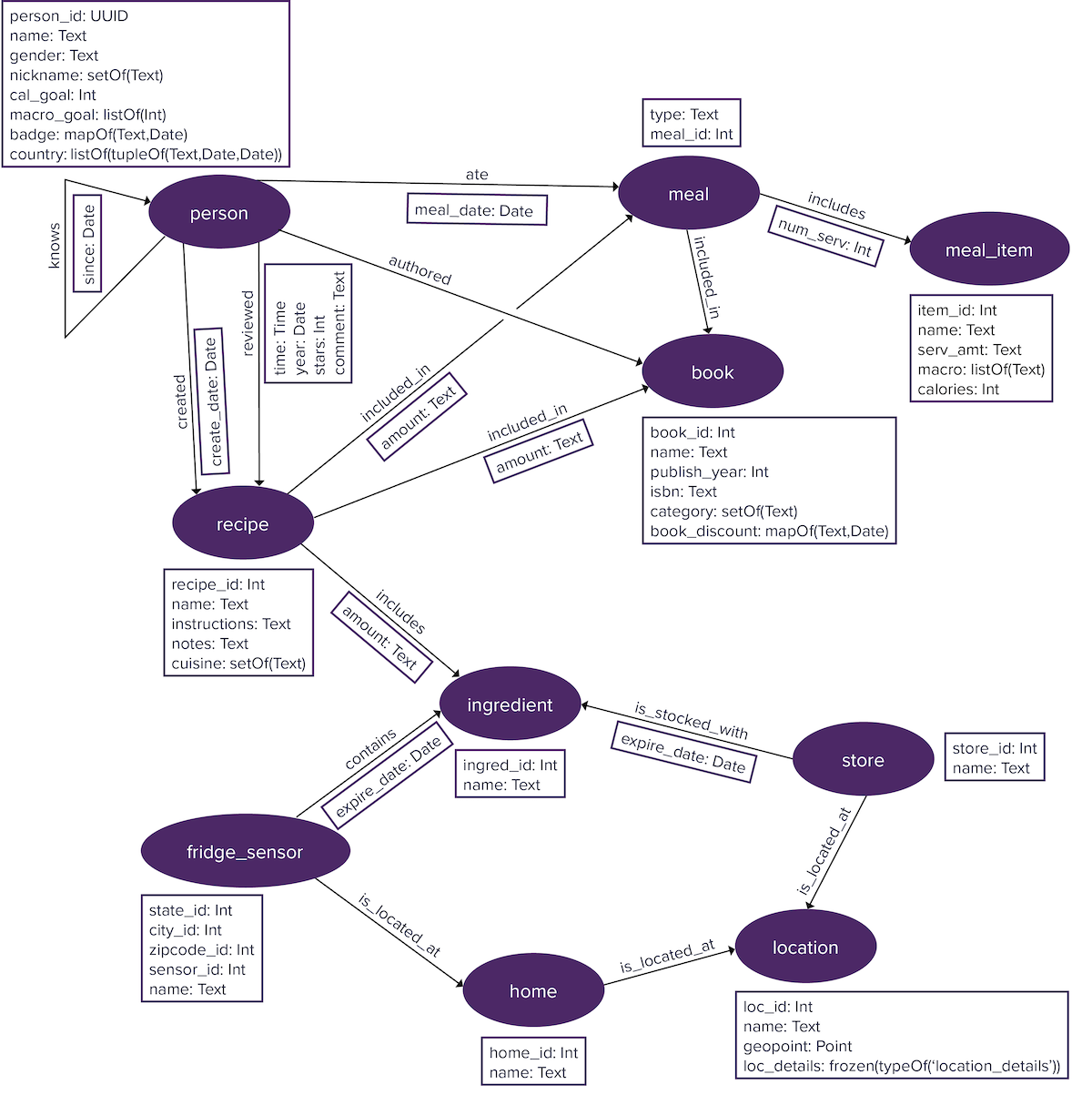
Elements are labeled to distinguish the type of vertices and edges in a graph database using vertex labels and edge labels. A vertex labeled person holds information about an author or reviewer or someone who ate a meal. An edge between an person and a book is labeled authored. Specifying appropriate labels is an important step in graph data modeling.
Vertices and edges generally have properties. For instance, a person vertex can have properties name and gender. Edges can also have properties. A created edge can have a create_date property that identifies when the adjoining recipe vertex was created.
Information in a graph database is retrieved using graph traversals. Graph traversals walk a graph with a single or series of traversal steps from a defined starting point and filter each step until returning a result.
DataStax Graph: CQL as Graph Installation
Install DataStax Graph, DSE Search, and DataStax Studio:
-
Start DataStax Enterprise (DSE) with DataStax Graph and DSE Search enabled. DSE Search enables search index use in the following examples.
-
Either start the CQL shell or install and start DataStax Studio.
-
If you don’t plan to use DataStax Studio for the entire tutorial, start the Gremlin console. If DataStax Graph was installed as a package, you can run the command directly. If installed from a tarball, run the command from
<install_directory>/bin.dse gremlin-consoleResult\,,,/ (o o) -----oOOo-(3)-oOOo----- plugin activated: tinkerpop.server plugin activated: tinkerpop.tinkergraph gremlin>Gremlin console sends all commands typed at the prompt to the Gremlin Server that processes the commands.
To exit the Gremlin console, use
:exit.
DataStax Graph: CQL as Graph Configuration
To use DSG, a graph must be created. Using DataStax Studio, either a pre-populated notebook, DataStax Graph: CQL as Graph v6.9.0, can be used, or a new notebook can be created. Instructions for both are provided. DataStax Graph (DSG) is tightly integrated with Cassandra, so that both the Gremlin langauge or the Cassandra Query Langauge (CQL) can be used to create, insert, update, and query graph data. This section focuses on using CQL to create a graph, insert data, and query with both CQL and Gremlin.
|
When Gremlin console is used for this section, an alias must be set a graph traversal source to execute code examples. The set alias identifies the graph in which all schema and queries are executed. Should Gremlin console be exited, you must set the alias configuration again before proceeding. |
DataStax Studio is a visual browser-based tool that provides a better understanding of the interconnectedness of the graph data and both CQL and Gremlin commands can be created in the tool.
The CQL shell (cqlsh) is a command-line interface that is better suited to automation of checking and verifying query results and scripting, as is the Gremlin console.
For initial exploration and development, DataStax Studio is highly recommended.
-
Create a DataStax Studio notebook and configure a graph for the DataStax Graph: CQL as Graph execution. If you are using
cqlsh, skip to the next section.-
This tutorial exists as a DataStax Studio notebook, DataStax Graph: CQL as Graph v6.9.0, so that you do not have to create a notebook. However, in DataStax Studio, creating a notebook is simple. If running DataStax Studio on a Graph node, the default connection of
localhostworks, otherwise create a connection for the node desired. Each notebook is connected to a graph or CQL keyspace. Multiple notebooks can be connected to the same graph or CQL keyspace, or multiple notebooks can be created to connect to different graphs or CQL keyspaces. The following information is provided on how to create a graph, but in this tutorial, we’ll create a CQL keyspace and alter it into a graph.DataStax Studio can create a graph from a number of different places. You can create the graph as the last step during notebook creation, or open a notebook and add a graph. Either way, several choices must be configured. The graph must be given a name, graph type designated, and replication factor settings selected.
-
Graph type: Core is the default and preferred graph engine for DataStax Graph. It allows users to access their graph data via CQL as well as Gremlin. The schemas for storing Core and Classic graphs are different, so Classic should be chosen only if a notebook will use graph data created using DSE Graph 6.7 or earlier.
-
Replication factor: The default is set to 1. Production clusters and multi-datacenter clusters need a higher replication factor.
-
Replication strategy: The default is NetworkTopologyStrategy. In general, this default is the good option.
-
-
-
cqlshneeds no configuration to start, although the tool does use a configuration filecqlshrc.
DataStax Graph: CQL as Graph Simple example
Let’s start with a simple example from the recipe data model. The data is composed of two vertices, one person who is an author (Julia Child) and one book (The Art of French Cooking, Vol. 1) with an edge between them to identify that Julia Child authored that book. We’ll supply CQL schema, insert data using CQL, then examine the data and run queries with both CQL and Gremlin.
Execute all code samples using either DataStax Studio or the CQL shell (cqlsh) by copy/pasting the codeblocks below.
-
Create a CQL keyspace:
CREATE KEYSPACE IF NOT EXISTS food_cql WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };This is a container for the tables that will hold graph data.
-
Verify that the CQL keyspace was created:
DESCRIBE KEYSPACE food_cql;CREATE KEYSPACE food_cql WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor': '1' }; -
The schema for the
fooddata model defines user-defined types (UDTs) that must be created before use in CQL table schema:CREATE TYPE IF NOT EXISTS food_cql.address ( address1 text, address2 text, city_code text, zip_code text); CREATE TYPE IF NOT EXISTS food_cql.fullname ( lastname text, firstname text); //Using a nested UDT in another UDT: CREATE TYPE IF NOT EXISTS food_cql.location_details ( loc_address frozen<address>, telephone list<text> ); -
CQL stores schema data in several tables in the system_schema keyspace: types, vertices, edges, indexes. A CQL query can be used to view the UDT information.
select * from system_schema.types WHERE keyspace_name='food_cql';keyspace_name | type_name | field_names | field_types ---------------+------------------+---------------------------------------------------+----------------------------------- food_cql | address | ['address1', 'address2', 'city_code', 'zip_code'] | ['text', 'text', 'text', 'text'] food_cql | fullname | ['lastname', 'firstname'] | ['text', 'text'] food_cql | location_details | ['loc_address', 'telephone'] | ['frozen<address>', 'list<text>'] (3 rows) -
Create the schema for a vertex label
person, along with the vertex properties and their data types in a CQL table:CREATE TABLE IF NOT EXISTS food_cql.person ( person_id uuid, name text, gender text, nickname set<text>, cal_goal int, macro_goal list<int>, country list<frozen<tuple<text, date, date>>>, badge map<text, date>, PRIMARY KEY (person_id) ) WITH VERTEX LABEL person_label;The Cassandra Query Language (CQL) table name will store
personvertices. TheAND VERTEX LABELdefines the graph vertex label nameperson_label; if not defined, the table name is used by default. Each property consists of a property key and data type that define CQL columns in the table. Both the vertex label and the property definitions must adhere to CQL naming syntax. Like CQL tables, a single or multiple partition key must be defined by at least one property in thePRIMARY KEY. Clustering columns may also be defined in thePRIMARY KEY. The partition key defines where in the cluster the data will reside, while the clustering columns define the sort order of the data within a partition.A new feature of DataStax Graph 6.8 is the use of collections as data types for properties. The DSE 6.7 Graph and earlier concepts of meta-properties and multi-properties are replaced with collections or nested collections. For instance,
countryis now defined as a list of tuples, to store multiple records of a country,start_date and end_date in which a person has lived. -
Similarly, create the schema for a vertex label
book, along with the vertex properties and their data types in a CQL table:CREATE TABLE IF NOT EXISTS food_cql.book ( book_id int, name text, publish_year int, isbn text, category set<text>, PRIMARY KEY(book_id) ) WITH VERTEX LABEL book_label;A vertex label name is unique within a keyspace, and a CQL table has only one graph label definition.
-
View the system_schema.vertices information.
// Look at the created vertex labels using CQL select * from system_schema.vertices; // Look at the created vertex labels using CQL select * from system_schema.vertices WHERE keyspace_name='food';keyspace_name | table_name | label_name ---------------+------------+-------------- food_cql | book | book_label food_cql | person | person_label (2 rows) -
Properties can also be added or dropped from tables. The properties added here with
ALTER_TABLEare used to track the book discount given on a book.ALTER TABLE food_cql.book ADD book_discount text; -
Create the schema for an edge label
authored, along with the edge properties and their data types in a CQL table:CREATE TABLE IF NOT EXISTS food_cql.person_authored_book ( person_id UUID, person_name text, book_id int, book_name text, PRIMARY KEY (person_id, person_name, book_id, book_name) ) WITH EDGE LABEL authored FROM person_label(person_id) TO book_label(book_id);The
v1-edge->v2triplet must be unique within a keyspace, and a table has only one graph label definition. The vertex labelsv1andv2must exist. The partition key forv1must be part of thePRIMARY KEYof the edge table. Clustering columns of bothv1andv2will also be part of thePRIMARY KEY. TheFROMandTOdefinitions must also match thePRIMARY KEYdefinitions of the vertices. Edge properties are not present in this example, but will be another column definition in the table. -
View the system_schema.edges information.
// Look at the created edge labels using CQL select * from system_schema.edges; // Look at the created edge labels using CQL select * from system_schema.edges WHERE keyspace_name='food_cql';The first query results in:
keyspace_name | table_name | label_name | from_clustering_columns | from_partition_key_columns | from_table | to_clustering_columns | to_partition_key_columns | to_table ---------------------+-------------------------------------+----------------------+-----------------------------+---------------------------------------------------------------------------------+---------------+-----------------------+-------------------------------+------------ food_cql | person_authored_book | authored | [] | ['person_id'] | person | [] | ['book_id'] | book (1 rows) -
Insert data for the
persontable using theINSERTCQL command:INSERT INTO food_cql.person (person_id, name, gender, nickname, country) VALUES ( bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca, 'Julia CHILD', 'F', {'Jay', 'Julia'}, [('USA', '1912-08-12', '1944-01-01'), ('Ceylon', '1944-01-01', '1945-06-01'), ('France', '1948-01-01', '1950-01-01'), ('USA', '1960-01-01', '2004-08-13')] ); INSERT INTO food_cql.person (person_id, name, gender, nickname, country) VALUES ( adb8744c-d015-4d78-918a-d7f062c59e8f, 'Simone BECK', 'F', {'Simca', 'Simon'}, [('France', '1904-07-07', '1991-12-20')] ); INSERT INTO food_cql.person (person_id, name, gender) VALUES ( 888ad970-0efc-4e2c-b234-b6a71c30efb5, 'Fritz STREIFF', 'M' );Using a
set, the propertynicknameis defined with multiple values, a replacement for previously supported multi-properties in DSE Graph 6.7 and earlier. In addition, notice the insertion of alistoftuplesfor the propertycountry. -
Verify that the data is inserted:
SELECT * FROM food_cql.person;person_id | badge | cal_goal | country | gender | macro_goal | name | nickname --------------------------------------+-------+----------+--------------------------------------------------------------------------------------------------------------------------------------------+--------+------------+---------------+-------------------- 888ad970-0efc-4e2c-b234-b6a71c30efb5 | null | null | null | M | null | Fritz STREIFF | null adb8744c-d015-4d78-918a-d7f062c59e8f | null | null | [('France', 1904-07-07, 1991-12-20)] | F | null | Simone BECK | {'Simca', 'Simon'} bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca | null | null | [('USA', 1912-08-12, 1944-01-01), ('Ceylon', 1944-01-01, 1945-06-01), ('France', 1948-01-01, 1950-01-01), ('USA', 1960-01-01, 2004-08-13)] | F | null | Julia CHILD | {'Jay', 'Julia'} (3 rows)In DataStax Studio, the result can be displayed using different views: Raw JSON, Table, or Graph. Explore the options.
-
Insert data for the
booktable using theINSERTCQL command:INSERT INTO food_cql.book (name,book_id,publish_year,isbn,category) VALUES ( 'The French Chef Cookbook', 1003, 1968, '0-394-40135-2', {'French'} ); INSERT INTO food_cql.book (name,book_id,publish_year,isbn,category) VALUES ( $$Simca's Cuisine: 100 Classic French Recipes for Every Occasion$$, 1002, 1972, '0-394-40152-2', {'American','French'} ); -
Verify that the data is inserted:
SELECT * FROM food_cql.book;The first query results in:
book_id | book_discount | category | isbn | name | publish_year ---------+---------------+------------------------+---------------+----------------------------------------------------------------+-------------- 1003 | null | {'French'} | 0-394-40135-2 | The French Chef Cookbook | 1968 1002 | null | {'American', 'French'} | 0-394-40152-2 | Simca's Cuisine: 100 Classic French Recipes for Every Occasion | 1972 (2 rows) -
Because the CQL tables were identified as vertex labels on creation, it is interesting that Gremlin can now also be used to examine the vertices inserted. However, the keyspace must be altered to a graph prior to the Gremlin query. So let’s do that before adding the edges.
ALTER KEYSPACE food_cql WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1} AND graph_engine = 'Core'; -
Verify that the keyspace was altered:
SELECT * FROM system_schema.keyspaces;keyspace_name | durable_writes | graph_engine | replication ---------------------+----------------+--------------+--------------------------------------------------------------------------------------- food | True | Core | {'SearchGraph': '1', 'class': 'org.apache.cassandra.locator.NetworkTopologyStrategy'} system_auth | True | null | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'} system_schema | True | null | {'class': 'org.apache.cassandra.locator.LocalStrategy'} dse_system_local | True | null | {'class': 'org.apache.cassandra.locator.LocalStrategy'} dse_system | True | null | {'class': 'org.apache.cassandra.locator.EverywhereStrategy'} dse_leases | True | null | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'} solr_admin | True | null | {'class': 'org.apache.cassandra.locator.EverywhereStrategy'} food_cql | True | Core | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'} dse_insights | True | null | {'class': 'org.apache.cassandra.locator.EverywhereStrategy'} dse_insights_local | True | null | {'class': 'org.apache.cassandra.locator.LocalStrategy'} system_distributed | True | null | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '3'} system | True | null | {'class': 'org.apache.cassandra.locator.LocalStrategy'} dse_perf | True | null | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'} system_traces | True | null | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '2'} dse_security | True | null | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'} (15 rows)A number of system keyspaces are listed here. Look for
food_cqland see that thegraph_engineis set toCore, verifying that the keyspace is now designated as a graph.The keyspace could be altered at the beginning of this section, before any work is done, or any other point. If a keyspace does not have graph_engine set, it won’t be recognized as a graph.
-
Now that the keyspace is a graph, we can use Gremlin to query the data, as well as CQL. Change the language to Gremlin in DataStax Studio to run this command, or start Gremlin console.
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph before running any commands. For example:
:remote config alias g food_qs.gg.V().hasLabel('person_label').elementMap()==>{id=dseg:/person_label/888ad970-0efc-4e2c-b234-b6a71c30efb5, label=person_label, gender=M, name=Fritz STREIFF, person_id=888ad970-0efc-4e2c-b234-b6a71c30efb5} ==>{id=dseg:/person_label/adb8744c-d015-4d78-918a-d7f062c59e8f, label=person_label, gender=F, name=Simone BECK, nickname=[Simca], person_id=adb8744c-d015-4d78-918a-d7f062c59e8f} ==>{id=dseg:/person_label/bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca, label=person_label, gender=F, name=Julia CHILD, person_id=bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca}Compare these results with the query that selected the data from the
personCQL table. -
We can similarly verify the
book_labeldata:g.V().hasLabel('book_label').elementMap()==>{id=dseg:/book_label/1003, label=book_label, publish_year=1968, isbn=0-394-40135-2, name=The French Chef Cookbook, book_id=1003, category=[French]} ==>{id=dseg:/book_label/1002, label=book_label, publish_year=1972, isbn=0-394-40152-2, name=Simca's Cuisine: 100 Classic French Recipes for Every Occasion, book_id=1002, category=[American, French]}Compare these results with the query that selected the data from the
bookCQL table. -
Insert data for the
person_authored_booktable using theINSERTCQL command:INSERT INTO food_cql.person_authored_book (person_name,person_id, book_name, book_id) VALUES ('Julia CHILD', bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca, 'The French Chef Cookbook', 1003); INSERT INTO food_cql.person_authored_book (person_name,person_id, book_name, book_id) VALUES ('Simone BECK', adb8744c-d015-4d78-918a-d7f062c59e8f, $$Simca's Cuisine: 100 Classic French Recipes for Every Occasion$$, 1002); -
Verify that the data is inserted with CQL:
SELECT * FROM food_cql.person_authored_book;The first query results in:
person_id | person_name | book_id | book_name --------------------------------------+-------------+---------+---------------------------------------------------------------- adb8744c-d015-4d78-918a-d7f062c59e8f | Simone BECK | 1002 | Simca's Cuisine: 100 Classic French Recipes for Every Occasion bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca | Julia CHILD | 1003 | The French Chef Cookbook (2 rows) -
We can similarly verify the
authoreddata with Gremlin:g.E().hasLabel('authored')==>e[dseg:/person_label-authored-book_label/adb8744c-d015-4d78-918a-d7f062c59e8f/Simone+BECK/Simca%27%27s+Cuisine%3A+100+Classic+French+Recipes+for+Every+Occasion/1002][dseg:/person_label/adb8744c-d015-4d78-918a-d7f062c59e8f-authored->dseg:/book_label/1002] ==>e[dseg:/person_label-authored-book_label/bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca/Julia+CHILD/The+French+Chef+Cookbook/1003][dseg:/person_label/bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca-authored->dseg:/book_label/1003] -
In order to use this data, one index is required for the edge label, made with gremlin:
schema.edgeLabel('authored'). from('person_label').to('book_label'). materializedView('authored_by_person_id'). ifNotExists(). partitionBy(OUT, 'person_id'). clusterBy('person_name', Asc). clusterBy(IN, 'book_id', Asc). clusterBy('book_name', Asc). create() -
In DataStax Studio, the results are easy to visualize and check. All of the commands can be executed in DataStax Studio as well as Gremlin console. In production, DSG prevents expensives queries from processing. In development, include the
with("label-warning", false)so that a query can run without specifying vertex labels.g.with("label-warning", false).V()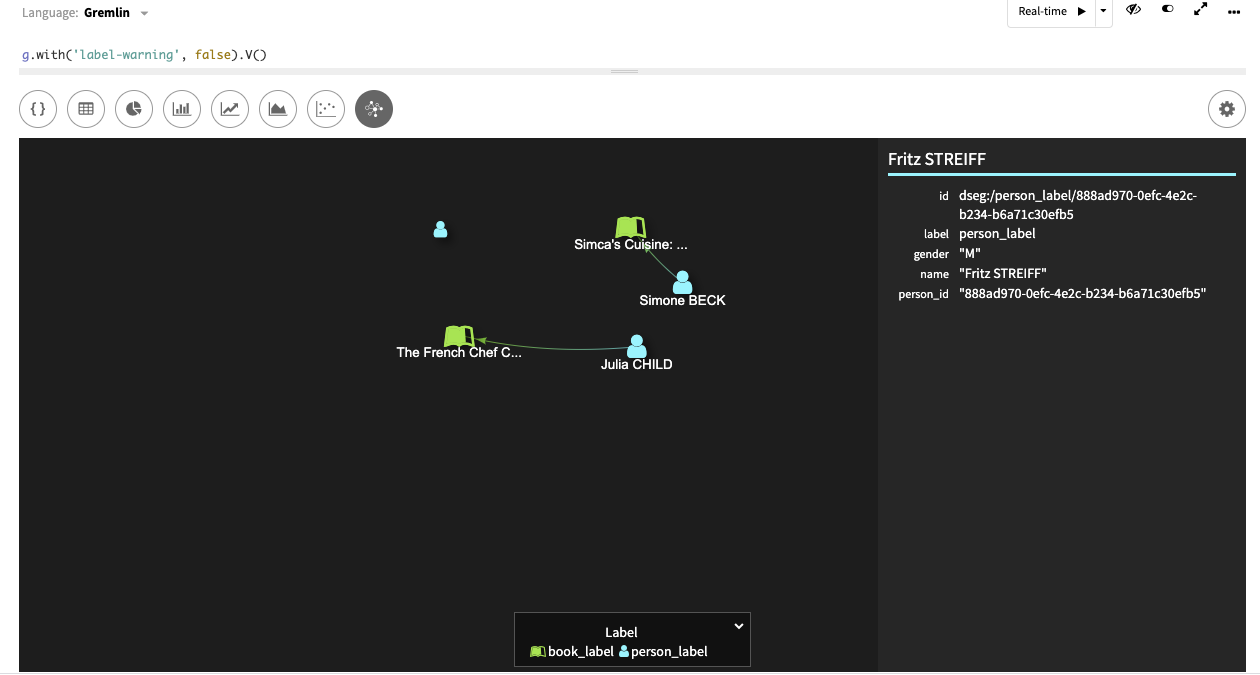
-
The
ALTER TABLECQL command can be used to rename a vertex or edge label:ALTER TABLE food_cql.person RENAME VERTEX LABEL TO "person";This command will change the vertex label from
person_labeltoperson, and simplify the Gremlin commands from this point on in the example. -
A much more useful query would check the data for a vertex using a simple bit of information, like a person’s name. However, without adding an index for
name, this query will fail, because the value for the primary keyperson_idis not supplied. For example:g.V().has('person', 'name', 'Julia CHILD')Two alternatives exist, a development mode for running queries and a modifier mode
with('allow-filtering'). Thedevmode is intended for early exploration, before appropriate indexes have been settled upon:dev.V().hasLabel('person').has('name', 'Julia CHILD')An alternative in development is to use the
with('allow-filtering')step which will do a full scan of all partitions:g.with('allow-filtering').V().has('person', 'name', 'Julia CHILD')All of these commands will return the same result:
==>v[dseg:/person/bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca] -
You’ll notice when you tried the command
g.V().has('person', 'name', 'Julia CHILD'), you got an error message that provides the index required to do the query in a production-safe manner:schema.vertexLabel('person'). materializedView('person_by_name'). ifNotExists(). partitionBy('name'). clusterBy('person_id', Asc). create()Note that while the index has been created successfully, it may not yet be finished building. Alternatively, use '.waitForIndex(<optionalTimeout>).create()' during index creation to wait for the index to be built. OKThe index is created as a materialized view table, with a partition key of the column to index and a clustering column of the original table’s partition key. Once the index exists, the query will run without doing a full scan. Indexing is a large topic that is worth reading about, as efficient queries depend on indexes.
-
Notice that the original query about Julia Child will now run without warnings, after the index is created, and returns the same information as the development queries:
g.V().has('person', 'name', 'Julia CHILD') -
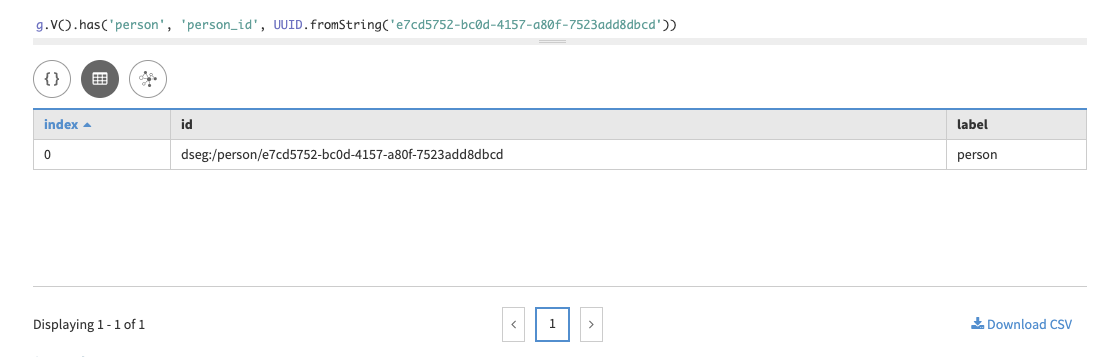
We now have data! Let’s see what kind of graph queries can be executed. First, check the data using the unique partition key:
g.V().has('person', 'person_id', UUID.fromString('e7cd5752-bc0d-4157-a80f-7523add8dbcd'))In DataStax Studio:
In Gremlin console:
==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd]While the partition key will be useful in some queries, generally queries use more user-friendly data, like
nameorcategory, to find vertices. -
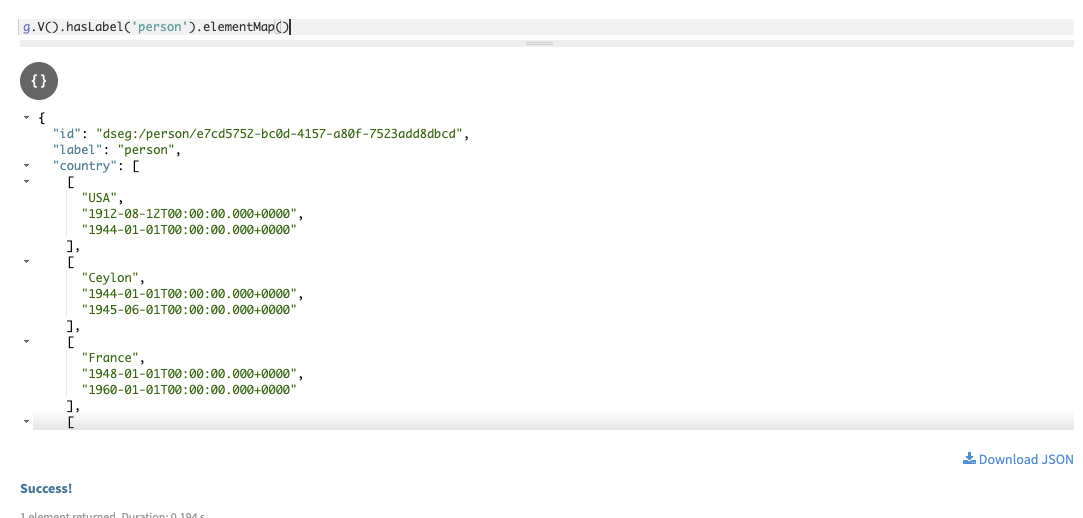
Two other useful traversals are
elementMap()andvalueMap()which print the key-value listing of each property value for specified vertices.g.V().hasLabel('person').elementMap()In DataStax Studio:
Using
elementMap()orvalueMap()without specifying properties can result in slow query latencies, if a large number of property keys exist for the queried vertex or edge. Specific properties can be specified, such aselementMap('name') or``valueMap('name').In Gremlin console:
gremlin> g.V().hasLabel('person').elementMap() ==>{id=dseg:/person/4ce9caf1-25b8-468e-a983-69bad20c017a, label=person, gender=M, name=James BEARD, nickname=[Jim, Jimmy], person_id=4ce9caf1-25b8-468e-a983-69bad20c017a} ==>{id=dseg:/person/888ad970-0efc-4e2c-b234-b6a71c30efb5, label=person, gender=M, name=Fritz STREIFF, person_id=888ad970-0efc-4e2c-b234-b6a71c30efb5} ==>{id=dseg:/person/4954d71d-f78c-4a6d-9c4a-f40903edbf3c, label=person, cal_goal=1800, gender=M, macro_goal=[30, 20, 50], name=John Smith, nickname=[Johnie], person_id=4954d71d-f78c-4a6d-9c4a-f40903edbf3c} ==>{id=dseg:/person/01e22ca6-da10-4cf7-8903-9b7e30c25805, label=person, gender=F, name=Kelsie KERR, person_id=01e22ca6-da10-4cf7-8903-9b7e30c25805} ==>{id=dseg:/person/6c09f656-5aef-46df-97f9-e7f984c9a3d9, label=person, cal_goal=1500, gender=F, macro_goal=[50, 15, 35], name=Jane DOE, nickname=[Janie], person_id=6c09f656-5aef-46df-97f9-e7f984c9a3d9} ==>{id=dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd, label=person, country=[('USA','1912-08-12','1944-01-01'), ('Ceylon','1944-01-01','1945-06-01'), ('France','1948-01-01','1950-01-01'), ('USA','1960-01-01','2004-08-13')], gender=F, name=Julia CHILD, nickname=[Jay, Julia], person_id=e7cd5752-bc0d-4157-a80f-7523add8dbcd}Using
valueMap()returns similar information in a slightly different container, but doesn’t include the elementidandlabel. Try out the command and compare! In DSG 6.8.0,valueMap()is deprecated, so useelementMap().
DataStax Graph: CQL as Graph Adding data using DSBulk
Now that the schema is created, data can be added using either the CQL method shown in the simple example or the DataStax Bulk Loader (DSBulk). The existing data can be dropped from the graph before reloading.
Data can be loaded with DSBulk, a standalone command-line tool, using CSV or JSON input files (see the next cell for CSV files that will be loaded). The following commands should be run from a terminal on a cluster node that has DSBulk installed.
-
Load data to
persontable from a CSV file with a pipe delimiter and allow missing field values:CSV data file located in
data/vertices/person.csvcontaining:person_id|name|gender|nickname|cal_goal|macro_goal|badge|country e7cd5752-bc0d-4157-a80f-7523add8dbcd|Julia CHILD|F|'Jay','Julia'||||[['USA', '1912-08-12', '1944-01-01'], ['Ceylon', '1944-01-01', '1945-06-01'], ['France', '1948-01-01', '1960-01-01'], ['USA','1960-01-01', '2004-08-13']] adb8744c-d015-4d78-918a-d7f062c59e8f|Simone BECK|F|'Simca','Simone'||||[['France', '1904-07-07', '1991-12-20']] 888ad970-0efc-4e2c-b234-b6a71c30efb5|Fritz STREIFF|M||||| f092107c-0c5c-47e7-917c-c82c7fc2a249|Louisette BERTHOLIE|F||||| ef811281-f954-4fd6-ace0-bf67d057771a|Patricia SIMON|F|'Pat'|||| d45c76bc-6f93-4d0e-9d9f-33298dae0524|Alice WATERS|F||||| 7f969e16-b81e-4fcd-87c5-1911abbed132|Patricia CURTAN|F|'Pattie'|||| 01e22ca6-da10-4cf7-8903-9b7e30c25805|Kelsie KERR|F||||| ad58b8bd-033f-48ee-8f3b-a84f9c24e7de|Emeril LAGASSE|M||||| 4ce9caf1-25b8-468e-a983-69bad20c017a|James BEARD|M|'Jim', 'Jimmy'|||| 65fd73f7-0e06-49af-abd6-0725dc64737d|John DOE|M|'Johnny'|1750|10,30,60|'silver':'2016-01-01', 'gold':'2017-02-01'| 3b3e89f4-5ca2-437e-b8e8-fe7c5e580068|John SMITH|M|'Johnnie'|1800|30,20,50|| 9b564212-9544-4f85-af36-57615e927f89|Jane DOE|F|'Janie'|1500|50,15,35|| ba6a6766-beae-4a35-965b-6f3878581702|Sharon SMITH|F||1600|30,20,50|| a3e7ab29-2ac9-4abf-9d4a-285bf2714a9f|Betsy JONES|F||1700|10,50,30||and run the
dsbulk loadcommand:dsbulk load --schema.keyspace food_qs --schema.table person -url data/vertices/person.csv -delim '|' --schema.allowMissingFields true -
Load data to
booktable from a CSV file with a pipe delimiter, allow missing field values, and identifying thefield->columnswith schema mapping:CSV data file located in
data/vertices/book.csvcontaining:book_id|name|publish_year|isbn 1001|The Art of French Cooking, Vol. 1|1961| 1002|Simca's Cuisine: 100 Classic French Recipes for Every Occasion|1972|0-394-40152-2 1003|The French Chef Cookbook|1968|0-394-40135-2 1004|The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution|2007|0-307-33679-4and run the
dsbulk loadcommand:dsbulk load -k food_qs -t book \ -url data/vertices/book.csv \ --schema.mapping '0=book_id, 1=name, 2=publish_year 3=isbn' \ -delim '|' \ --schema.allowMissingFields true -
Load data to
person_authored_booktable from a CSV file with a pipe delimiter, allow missing field values, and map CSV file positions to named columns in the table:CSV data file located in
data/edges/person_authored_book.csvcontaining:person_id|book_id bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca|1001 adb8744c-d015-4d78-918a-d7f062c59e8f|1001 f092107c-0c5c-47e7-917c-c82c7fc2a249|1001 adb8744c-d015-4d78-918a-d7f062c59e8f|1002 ef811281-f954-4fd6-ace0-bf67d057771a|1002 bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca|1003 d45c76bc-6f93-4d0e-9d9f-33298dae0524|1004 7f969e16-b81e-4fcd-87c5-1911abbed132|1004 01e22ca6-da10-4cf7-8903-9b7e30c25805|1004 888ad970-0efc-4e2c-b234-b6a71c30efb5|1004and run the
dsbulk loadcommand:dsbulk load -k food_qs -t person_authored_book \ -url data/edges/person\_authored\_book.csv \ -m '0=lastname, 1=person_id, 2=person_name, 3=book_id 4=book_name' \ -delim '|' \ --schema.allowMissingFields true
