About Apache Spark
Apache Spark™ is a framework for analyzing large datasets across a cluster, and is enabled when you start an Analytics node. Apache Spark runs locally on each node and executes in memory when possible. Apache Spark uses multiple threads instead of multiple processes to achieve parallelism on a single node, avoiding the memory overhead of several JVMs.
Spark integration with DataStax Enterprise (DSE) includes:
-
Apache Cassandra Spark Connector for accessing data stores in DSE
-
DSE Resource Manager for managing Spark components in a DSE cluster
-
Spark SQL support
-
DataFrames API to manipulate data within Apache Spark
Apache Spark architecture
The software components for a single DSE analytics node are:
-
Spark worker
-
DSE File System (DSEFS)
-
The database
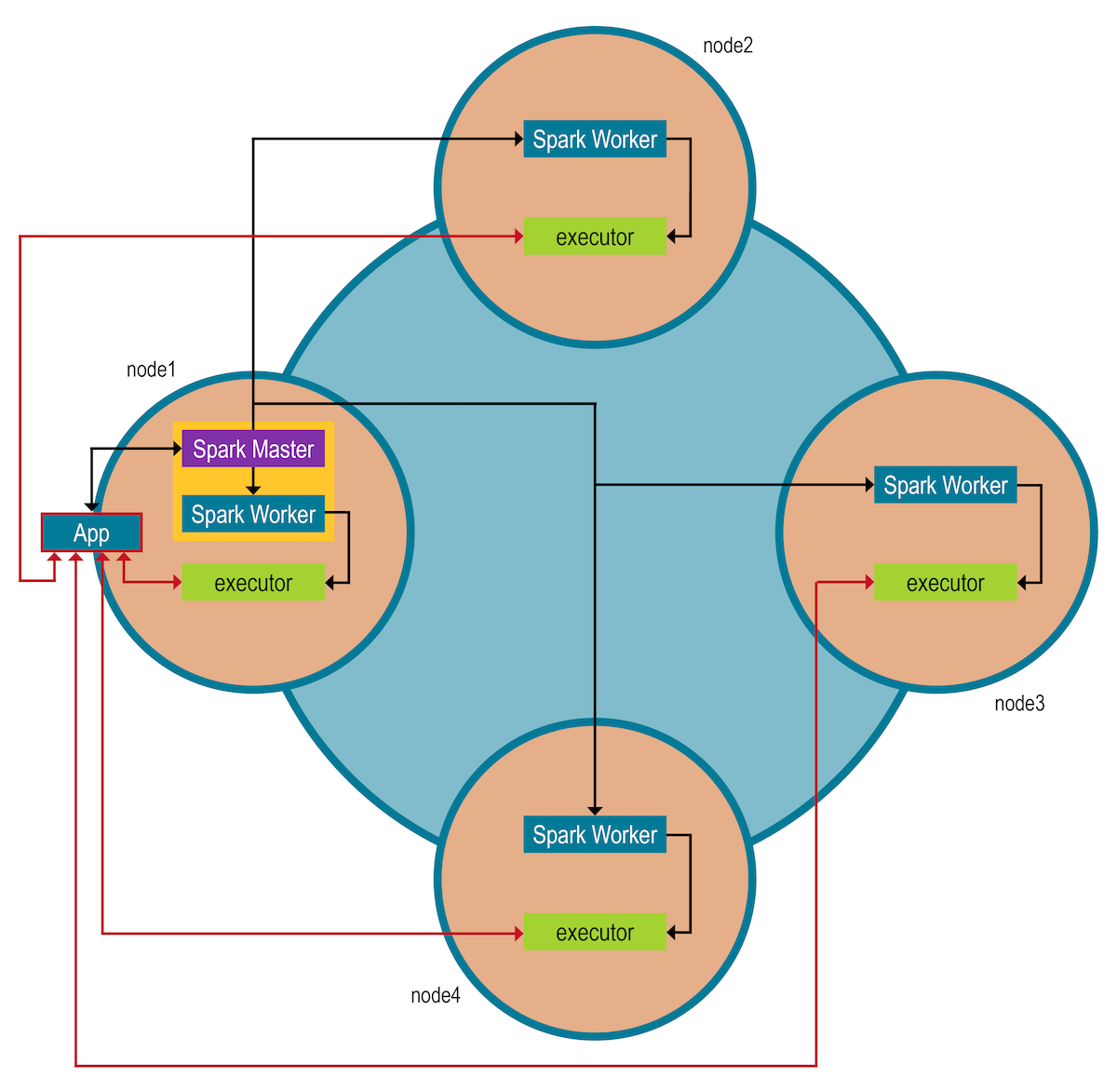
A Spark master acts purely as a resource manager for Spark applications. Spark workers launch executors that are responsible for executing part of the job that is submitted to the Spark master. Each application has its own set of executors. Spark architecture is described in the Apache documentation.
DSE Spark nodes use a different resource manager than standalone Spark nodes. The DSE Resource Manager simplifies integration between Apache Spark and DSE. In a DSE Spark cluster, client applications use the CQL protocol to connect to any DSE node, and that node redirects the request to the Spark master.
The communication between the Spark client application (or driver) and the Spark master is secured the same way as connections to DSE, which means that plain password authentication as well as Kerberos authentication is supported, with or without SSL encryption. Encryption and authentication can be configured per application, rather than per cluster. Authentication and encryption between the Spark master and worker nodes can be enabled or disabled regardless of the application settings.
Apache Spark supports multiple applications. A single application can spawn multiple jobs and the jobs run in parallel. An application reserves some resources on every node and these resources are not freed until the application finishes. For example, every session of Spark shell is an application that reserves resources. By default, the scheduler tries allocate the application to the highest number of different nodes. For example, if the application declares that it needs four cores and there are ten servers, each offering two cores, the application most likely gets four executors, each on a different node, each consuming a single core. However, the application can get also two executors on two different nodes, each consuming two cores. You can configure the application scheduler. Spark workers and Spark master are part of the main DSE process. workers spawn executor JVM processes which do the actual work for a Spark application (or driver). Spark executors access data in local transactional nodes through the built-in Apache Cassandra Spark Connector. The memory settings for the executor JVMs are set by the user submitting the driver to DSE.
In deployment for each Analytics datacenter one node runs the Spark master, and Spark workers run on each of the nodes. The Spark master comes with automatic high availability.
As you run Apache Spark, you can access data in the Apache Hadoop Distributed File System (HDFS), or the DSE File System (DSEFS) by using the URL for the respective file system.
Highly available Apache Spark master
The Spark master High Availability mechanism uses a special table in the dse_analytics keyspace to store information required to recover Spark workers and the application.
Reads to the recovery data in dse_analytics are always performed using the LOCAL_QUORUM consistency level.
Writes are attempted first using LOCAL_QUORUM, and if that fails, the write is retried using LOCAL_ONE.
Unlike the high availability mechanism mentioned in Spark documentation, DSE does not use Apache ZooKeeper™.
If the original Spark master fails, the reserved one automatically takes over. To find the current Spark master, run:
dse client-tool spark leader-addressDSE provides Automatic Apache Spark master management.
|
The Spark master will not start until |
Unsupported features
The following Apache Spark features and APIs are not supported:
-
Writing to blob columns from Apache Spark
Reading columns of all types is supported; however, you must convert collections of blobs to byte arrays before serializing.
