Manual repair: Anti-entropy repair
Anti-entropy node repairs are important for every DataStax Enterprise (DSE) cluster. Frequent data deletions and downed nodes are common causes of data inconsistency. Use anti-entropy repair for routine maintenance and when a cluster needs fixing by running the nodetool repair. For continuous background repair, use NodeSync: Continuous background repair. Over time, data in a replica can become inconsistent with other replicas due to the distributed nature of the database. Node repair corrects the inconsistencies so that all nodes have the same and most up-to-date data. Node repair is an important part of regular maintenance for every DSE cluster.
A manual repair is run using nodetool repair. This tool provides many options for configuring repair. This page provides guidance for choosing certain parameters.
|
Before beginning any repair operation, it is important that you turn off the DSE OpsCenter Repair Service. Attempting repairs while the service is running can cause conflicts and data corruption. Tables with NodeSync enabled are skipped by repair operations that run against all or specific keyspaces.
For individual tables, running the |
Partitioner range (-pr)
Within a cluster, the database stores a particular range of data on multiple nodes, as determined by the replication factor.
There is, however, only one primary node for any range.
If you run nodetool repair on one node at a time, the database could repair the same range of data several times, depending on the replication factor used in the keyspace.
If you use the partitioner range option, nodetool repair -pr, repairs only the range for which the running node is the primary owner.
This repairs a specified range of data only once, rather than repeating the repair operation.
This option decreases the strain on network resources, although nodetool repair -pr still builds Merkle trees for each replica.
You can use the partitioner range option with incremental repair; however it is not recommended because incremental repair already avoids re-repairing data by marking data as repaired. The most efficient way to run incremental repair is without the -pr parameter since it can skip anti-compaction by marking whole SSTables as repaired.
|
If you use this option, run the repair on every node in the cluster to repair all data. Otherwise, some ranges of data will not be repaired. |
DataStax recommends using the partitioner range parameter when running full repairs during routine maintenance.
|
Full repair is run by default. |
|
If running |
Local (-local) vs datacenter (-dc) vs cluster-wide repair
Consider carefully before using nodetool repair across datacenters, instead of within a local datacenter.
When you run repair locally on a node using -local, the command runs only on nodes within the same datacenter as the node that runs it.
Otherwise, the command runs cluster-wide repair processes on all nodes that contain replicas, even those in different datacenters.
For example, if you start nodetool repair over two datacenters, DC1 and DC2, each with a replication factor of 3, repair builds Merkle tables for 6 nodes.
The number of Merkle Tree increases linearly for additional datacenters.
Cluster-wide repair also increases network traffic between datacenters tremendously, and can cause cluster issues.
If the local option is too limited, use the -dc option to limit repairs to a specific datacenter.
This does not repair replicas on nodes in other datacenters, but it can decrease network traffic while repairing more nodes than the local options.
The nodetool repair -pr option is good for repairs across multiple datacenters.
Additional guidance for nodetool repair options:
-
Does not support the use of
-localwith the-proption unless the datacenter nodes have all the data for all ranges. -
Does not support the use of
-localwith-inc(incremental repair).
|
For repairs across datacenters, use the |
One-way targeted repair from a remote node (--pull, --hosts, -st, -et)
Runs a repair directly from another node, which has a replica in the same token range. This option minimizes performance impact when cross-datacenter repairs are required.
nodetool repair --pull -hosts <local_ip_address>,<remote_ip_address> <keyspace_name>
Endpoint range vs Subrange repair (-st, -et)
A repair operation runs on all partition ranges on a node, or endpoint range, unless using -st and -et (or -start-token and -end-token) options to run subrange repairs.
When you specify a start token and end token, nodetool repair works between these tokens, repairing only those partition ranges.
Subrange repair is not a good strategy because it requires generated token ranges. However, if you know which partition has an error, you can target that partition range precisely for repair. This approach can relieve the problem known as overstreaming, which ties up resources by sending repairs to a range over and over.
Subrange repair involves more than just the nodetool repair command.
A Java describe_splits call to ask for a split containing 32k partitions can be iterated throughout the entire range incrementally or in parallel to eliminate the overstreaming behavior.
Once the tokens are generated for the split, they are passed to nodetool repair -st <start_token> -et <end_token>.
The -local option can be used to repair only within a local datacenter to reduce cross datacenter transfer.
Full repair vs incremental repair (-full vs -inc)
Full repair builds a full Merkle tree and compares it the data against the data on other nodes. For a complete explanation of full repair, see How does anti-entropy repair work?.
Incremental repair compares all SSTables on the node and makes necessary repairs. An incremental repair persists data that has already been repaired, and only builds Merkle trees for unrepaired SSTables. Incremental repair marks the rows in an SSTable as repaired or unrepaired.
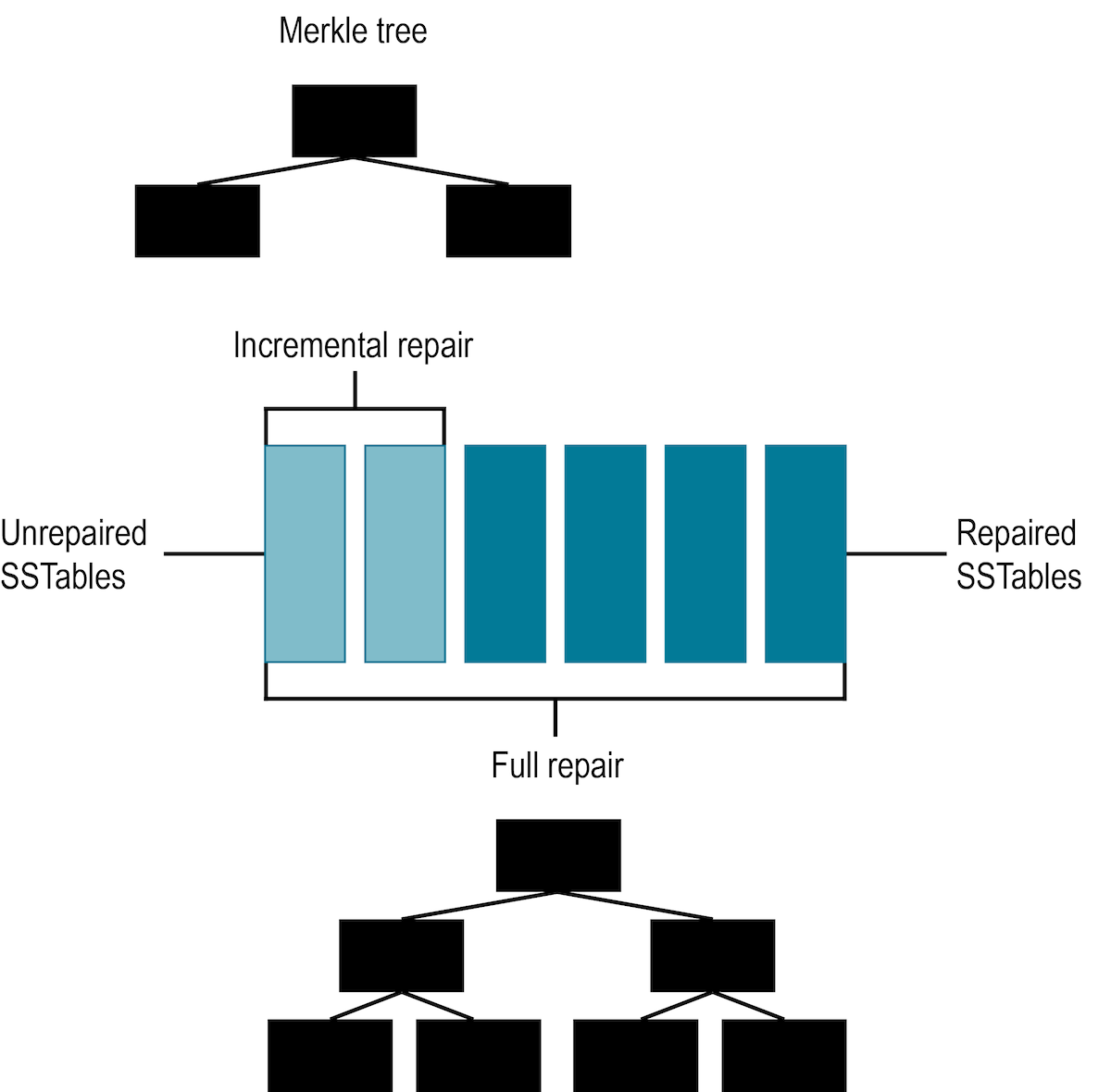
Incremental repairs work like full repairs, with an initiating node requesting Merkle trees from peer nodes with the same unrepaired data, and then comparing the Merkle trees to discover mismatches.
Once the data has been reconciled and new SSTables built, the initiating node issues an anti-compaction command.
Anti-compaction is the process of segregating repaired and unrepaired ranges into separate SSTables, unless the SSTable fits entirely within the repaired range.
In the latter case, the SSTable metadata repairedAt is updated to reflect its repaired status.
Anti-compaction is handled differently, depending on the compaction strategy assigned to the data.
-
Size-tiered compaction (STCS) splits repaired and unrepaired data into separate pools for separate compactions. A major compaction generates two SSTables, one for each pool of data.
-
Leveled compaction (LCS) performs size-tiered compaction on unrepaired data. After repair completes, DSE moves data from the set of unrepaired SSTables to L0.
-
Date-tiered (DTCS) splits repaired and unrepaired data into separate pools for separate compactions. A major compaction generates two SSTables, one for each pool of data. DTCS compaction should only be used with full repair.
Parallel vs Sequential repair (default, -seq, -dc-par)
The default mode runs repair on all nodes with the same replica data at the same time. Sequential (-seq) runs repair on one node after another. Datacenter parallel (-dcpar) combines sequential and parallel by simultaneously running a sequential repair in all datacenters; a single node in each datacenter runs repair, one after another until the repair is complete.
Sequential repair takes a snapshot of each replica. Snapshots are hardlinks to existing SSTables. They are immutable and require almost no disk space. The snapshots are active while the repair proceeds, then the database deletes them. When the coordinator node finds discrepancies in the Merkle trees, the coordinator node makes required repairs from the snapshots. For example, for a table in a keyspace with a Replication factor RF=3 and replicas A, B and C, the repair command takes a snapshot of each replica immediately and then repairs each replica from the snapshots sequentially (using snapshot A to repair replica B, then snapshot A to repair replica C, then snapshot B to repair replica C).
Parallel repair works on nodes A, B, and C all at once. During parallel repair, the dynamic snitch processes queries for this table using a replica in the snapshot that is not undergoing repair.
Sequential repair is the default in DSE 4.8 and earlier. Parallel repair is the default for DSE 5.0 and later.
