DSE Search
In a distributed environment, the data is spread over multiple nodes. Deploy DSE Search nodes in their own datacenter to run DSE Search on all nodes.
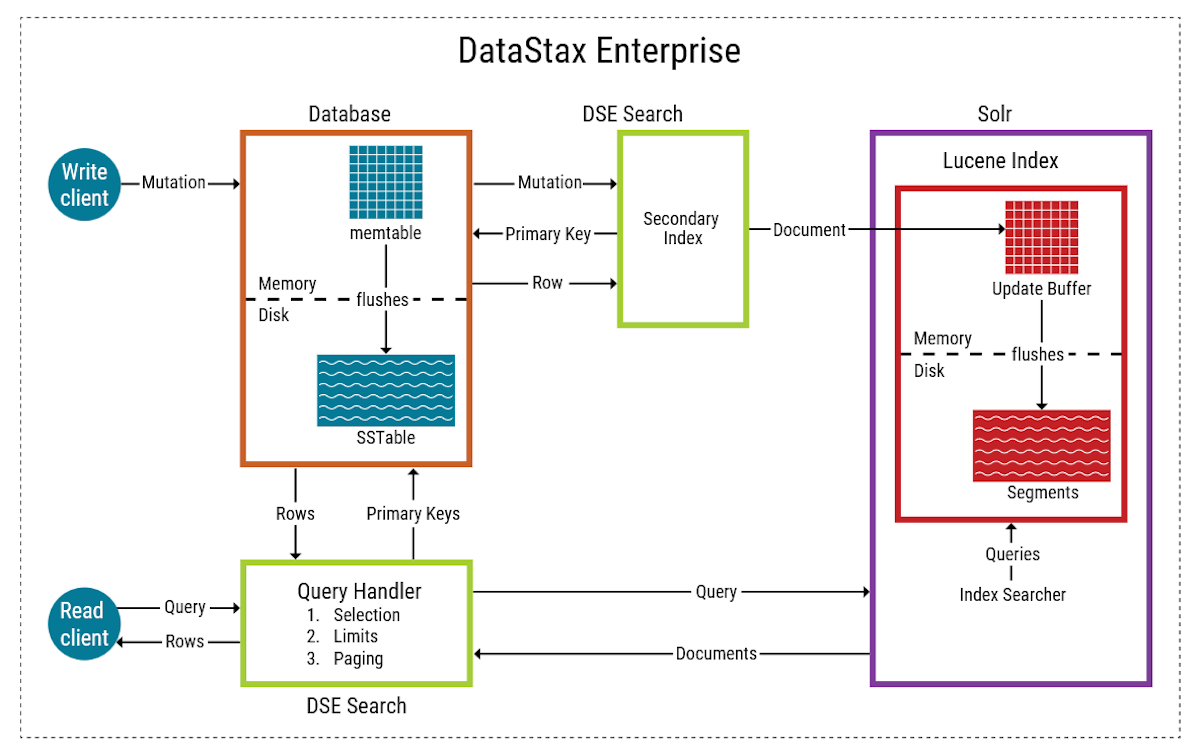
Data is written to the database first, and then indexes are updated next.
When you update a table using CQL, the search index is updated. Indexing occurs automatically after an update. Writes are durable. All writes to a replica node are recorded in memory and in a commit log before they are acknowledged as a success. If a crash or server failure occurs before the memory tables are flushed to disk, the commit log is replayed on restart to recover any lost writes.
DSE Search terms
In DSE Search, there are several names for an index of documents on a single node:
-
A search index (formerly referred to as a search core)
-
A collection
-
One shard of a collection
See the following table for a mapping between database and DSE Search concepts.
| Database | Search single node environment |
|---|---|
Table |
Search index (core) or collection |
Row |
Document |
Primary key |
Unique key |
Column |
Field |
Node |
n/a |
Partition |
n/a |
Keyspace |
n/a |
How DSE Search works
-
Each document in a search index is unique and contains a set of fields that adhere to a user-defined schema.
-
The schema lists the field types and defines how they should be indexed.
-
DSE Search maps search indexes to tables.
-
Each table has a separate search index on a particular node.
-
Solr documents are mapped to rows, and document fields to columns.
-
A shard is indexed data for a subset of the data on the local node.
-
The keyspace is a prefix for the name of the search index and has no counterpart in Solr.
-
Search queries are routed to enough nodes to cover all token ranges.
-
The query is sent to all token ranges to get all possible results.
-
The search engine considers the token ranges that each node is responsible for, taking into account the replication factor (RF), and computes the minimum number of nodes that is required to query all ranges.
-
-
On DSE Search nodes, the shard selection algorithm for distributed queries uses a series of criteria to route sub-queries to the nodes most capable of handling them. The shard routing is token aware, but is not limited unless the search query specifies a specific token range.
-
With replication, a node or search index contains more than one partition (shard) of table (collection) data. Unless the replication factor equals the number of cluster nodes, the node or search index contains only a portion of the data of the table or collection.
DSE Search path
This section provides an overview of the DSE Search path, and how Solr integrates with Apache Cassandra®:
-
A row mutation is performed in Apache Cassandra.
-
A thread in the Thread Per Core (TPC) architecture processes the mutation.
-
The mutation is forwarded to the secondary index API.
-
A Lucene document is built from the latest full row in the backing table.
-
The document is placed in the Lucene RAM buffer.
-
Control is returned to Apache Cassandra.
-
The Apache Cassandra write operation is completed.
|
