DataStax Graph QuickStart
DataStax Graph (DSG) QuickStart using DataStax Studio or Gremlin console.
QuickStart Introduction
QuickStart Introduction
Graph databases are useful for discovering simple and complex relationships between objects. Relationships are fundamental to how objects interact with one another and their environment. Apache Cassandra can store large distributed datasets, and DataStax Graph (DSG) is Graph for Apache Cassandra. DSG allows Apache Cassandra data to be traversed with complex queries that are not possible with the Cassandra Query Language (CQL) or are the equivalent of multiple SQL JOINS required in a traditional RDBMS.
This QuickStart explores DSG from a data model that leads to schema, inserting data, and simple queries that show off the power of graph databases. Starting with DSG 6.8, the same data can be queried with either Gremlin or CQL, increasing the useability of the same data for different uses. However, for this QuickStart, we’ll use Gremlin as the main language of interaction.We’ll start by discussing what a graph database actually is.
Graph databases consist of three elements:
-
vertex
A vertex is an object, such as a person, location, automobile, recipe, or anything else you can think of as nouns.
-
edge
An edge defines the relationship between two vertices. A person can create software, or an author can write a book. Typically an edge is equivalent to a verb.
-
property
A key-value pair that describes some attribute of either a vertex or an edge. A property key is used to describe the key in the key-value pair.
Vertices, edges, and properties can have properties; for this reason, DataStax Graph is classified as a property graph. The properties for elements are an important element of storing and querying information in a property graph.
Property graphs are typically quite large, although the nature of querying the graph varies depending on whether the graph has large numbers of vertices, edges, or both vertices and edges. To get started with graph database concepts, a toy graph is used for simplicity. The example used here explores the world of food.
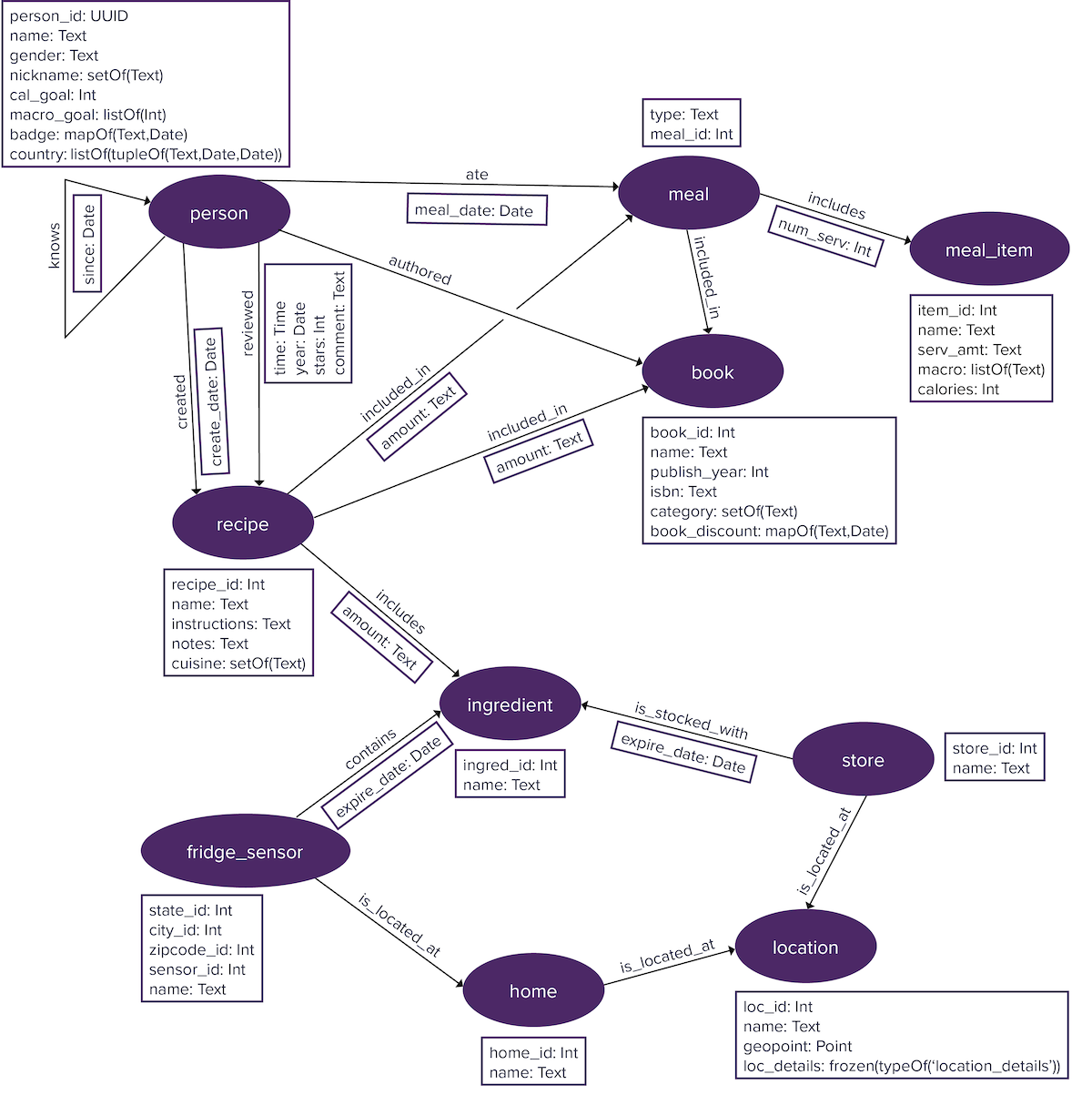
Elements are labeled to distinguish the type of vertices and edges in a graph database using vertex labels and edge labels. A vertex labeled person holds information about an author or reviewer or someone who ate a meal. An edge between an person and a book is labeled authored. Specifying appropriate labels is an important step in graph data modeling.
Vertices and edges generally have properties. For instance, a person vertex can have properties name and gender. Edges can also have properties. A created edge can have a create_date property that identifies when the adjoining recipe vertex was created.
Information in a graph database is retrieved using graph traversals. Graph traversals walk a graph with a single or series of traversal steps from a defined starting point and filter each step until returning a result.
Quickstart installation
Install DataStax Enterprise (DSE) and DataStax Studio:
-
Start DataStax Enterprise (DSE) with DataStax Graph and DSE Search enabled. DSE Search enables search index use in the examples below.
-
Either install and start DataStax Studio or start the Gremlin console.
To start the Gremlin console, run the following command. If DataStax Graph was installed as a package, you can run the command directly. If installed from a tarball, run the command from
<install_directory>/bin.dse gremlin-consoleResult
\,,,/ (o o) -----oOOo-(3)-oOOo----- plugin activated: tinkerpop.server plugin activated: tinkerpop.tinkergraph gremlin>Gremlin console sends all commands typed at the prompt to the Gremlin Server that processes the commands.
To exit the Gremlin console, use
:exit.
QuickStart Configuration
Configure DataStax Graph to run QuickStart.
About this task
To use DSG, a graph must be created. With DataStax Studio, you can either use a pre-populated notebook, DataStax Graph QuickStart, or create a new notebook. Instructions for both are provided. In addition, if Gremlin console is used for this QuickStart, a graph must be created, and an alias to set a graph traversal source must be executed in order for the code examples to work. The set alias identifies the graph in which all schema and queries are executed.
|
Should Gremlin console be exited, you must set the alias configuration again before proceeding. |
DataStax Studio is a visual browser-based tool that provides a better understanding of the interconnectedness of the graph data. The Gremlin console is a command-line interface that is better suited to automation of checking and verifying query results and scripting. For initial exploration and development, Studio is highly recommended, whereas greater familiarity with DSG will make Gremlin console handy for automated verification.
Procedure
-
Create a Studio notebook and configure a graph for the QuickStart. If you are using Gremlin console, skip to the instructions for set up..
-
This tutorial exists as a Studio notebook, DataStax Graph QuickStart, so that you do not have to create a notebook. However, in Studio, creating a notebook is simple. If running Studio on a Graph node, the default connection of
localhostworks, otherwise create a connection for the node desired. Each notebook is connected to a particular graph. Multiple notebooks can be connected to the same graph, or multiple notebooks can be created to connect to different graphs.Studio can create a graph from a number of different places. You can create the graph as the last step during notebook creation, or open a notebook and add a graph. Either way, several choices must be configured. The graph must be given a name, graph type designated, and replication factor settings selected.
-
Graph type: Core is the default and preferred graph engine for DataStax Graph 6.8. It allows users to access their graph data via CQL as well as Gremlin. The schemas for storing Core and Classic graphs are different, so Classic should be chosen only if a notebook will use graph data created using DataStax Graph 6.7 or earlier.
-
Replication factor: The default is set to 1. Production clusters and multi-datacenter clusters need a higher replication factor.
-
Replication strategy: The default is NetworkTopologyStrategy. In general, this default is the good option.
-
-
-
Create a graph in Gremlin console and configure the graph for the QuickStart.
-
Create a graph to hold the data. The system commands are used to run commands that affect graphs in DSG.
system.graph('food_qs'). ifNotExists(). create()==>OK -
Once a graph exists, a graph traversal g is configured that will allow graph traversals to be executed. Graph traversals are used to query the graph data and return results. The graph traversal can be bound to either the standard OLTP engine or the OLAP engine. In order to execute any schemas or other queries in the Gremlin console, a graph traversal must be executed first. Configure a graph traversal
gto use the default graph traversal setting, which isfood_qs.g.:remote config alias g food_qs.g==>g=food_qs.gAs with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with
:remote config alias g food_qs.gbefore running any commands. -
When creating a new graph, to check what graphs already exist, use:
system.graphs()==>food_qs
-
QuickStart Simple example
Simple DataStax Graph example.
About this task
Let’s start with a simple example from the recipe data model.
The data is composed of two vertices, one person who is an author (Julia Child) and one book (The Art of French Cooking, Vol.
1) with an edge between them to identify that Julia Child authored that book.
We’ll supply schema, insert data using graph traversals with g.addV() and g.addE(), then examine the data and run queries.
Execute all code samples using either Studio or Gremlin console by copy/pasting the codeblocks below.
|
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with |
Procedure
-
Create the schema for a vertex label
person, along with the vertex properties and their data types:schema.vertexLabel('person'). ifNotExists(). partitionBy('person_id', Uuid). property('name', Text). property('gender', Text). property('nickname', setOf(Text)). property('cal_goal', Int). property('macro_goal', listOf(Int)). property('country', listOf(tupleOf(Text, Date, Date))). property('badge', mapOf(Text, Date)). create()The vertex label defines the Cassandra Query Language (CQL) table name that will store
personvertices. Each property consists of a property key and data type that define CQL columns in the table. Both the vertex label and the property definitions must adhere to CQL naming syntax. Like CQL tables, a single or multiple partition key must be defined with at least one property usingpartitionBy property\_name. Clustering columns may also be defined using a similarclusteringBy property\_name. The partition key defines where in the cluster the data will reside, while the clustering columns define the sort order of the data within a partition.A new feature of DataStax Graph 6.8 is the use of collections as data types for properties. The DSE 6.7 Graph and earlier concepts of meta-properties and multi-properties are replaced with collections or nested collections. For instance,
countryis now defined as a list of tuples, to store multiple records of a country,start_date and end_date in which a person has lived.A successful schema command will return:
==> OK -
Insert a vertex for Julia Child using a
g.addV()command.g.addV('person'). property('person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID). property('name', 'Julia CHILD'). property('gender','F'). property('nickname', ['Jay', 'Julia'] as Set). property('country', [['USA', '1912-08-12' as LocalDate, '1944-01-01' as LocalDate] as Tuple, ['Ceylon', '1944-01-01' as LocalDate, '1945-06-01' as LocalDate] as Tuple, ['France', '1948-01-01' as LocalDate, '1960-01-01' as LocalDate] as Tuple, ['USA', '1960-01-01' as LocalDate, '2004-08-13' as LocalDate] as Tuple])The vertex label
personidentifies the type of vertex to add along with the property key-value pairs created. Note that some properties include additional information to define the data type conversion from a string to the required type.Using a
set, the property nickname is defined with multiple values, a replacement for previously supported multi-properties.The Studio result:
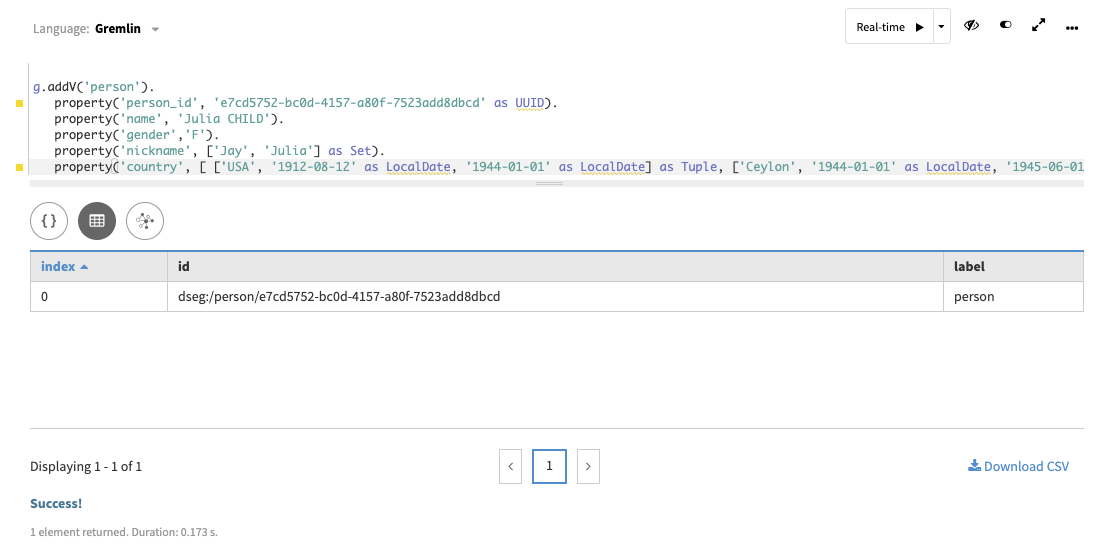
In Studio, the result can be displayed using different views: Raw JSON, Table, or Graph. Explore the options.
The Gremlin console result:
==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd] -
Create the schema for a vertex label
book:schema.vertexLabel('book'). ifNotExists(). partitionBy('book_id', Int). property('name', Text). property('publish_year', Int). property('isbn', Text). property('category', setOf(Text)). create()This command and the next one will return results similar to the actions above for creating a
person. -
Insert a book into the graph:
g.addV('book'). property('book_id',1001). property('name',"The Art of French Cooking, Vol. 1"). property('publish_year', 1961). property('category', ['French', 'American'] as Set)The Studio result:
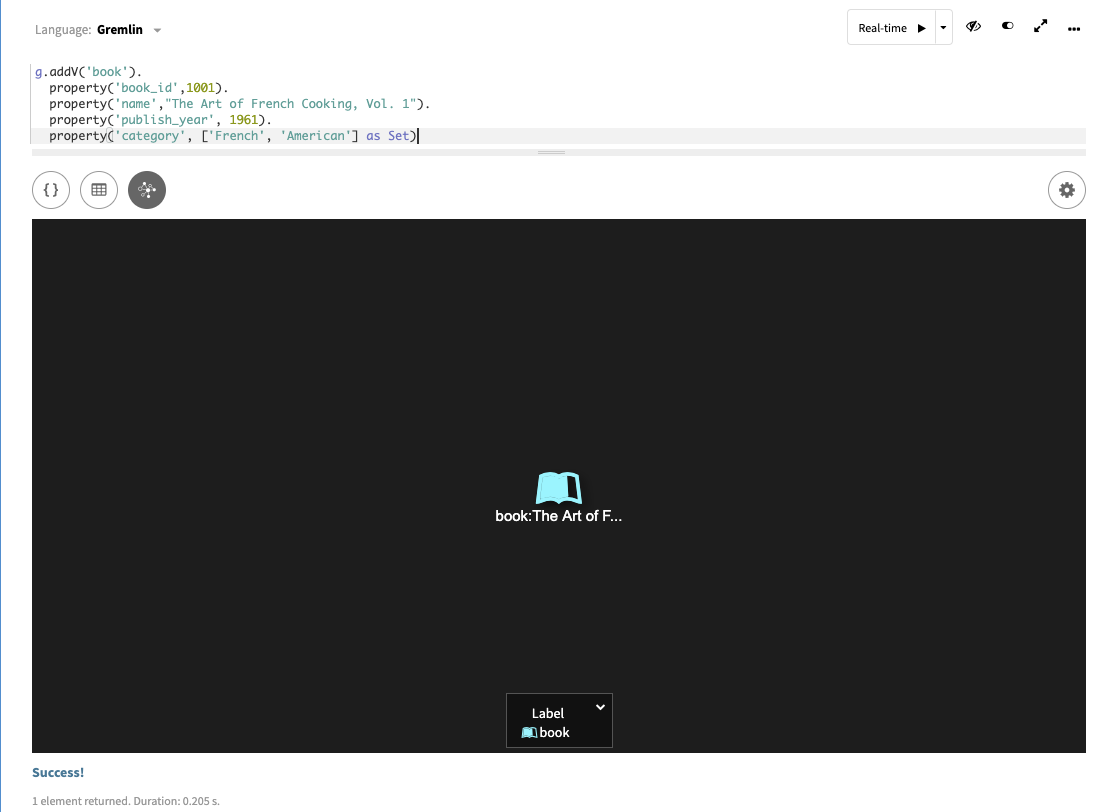
As with the person vertex, you can see all the information about the book vertex created. In Graph view, use the Settings button (the gear) to change the display label for person by entering
Chef {{name}}. Change the book display label withbook:{{{[name]}}}. Change the icon for books to a book icon as shown here with the Style-Vertex Shape menu. To set graph display names more generally, look for “Manage Global Defaults” under the Display NamesThe Gremlin console result:
==>v[dseg:/book/1001] -
Add schema for the edge between the two vertices for a person authoring a book:
schema.edgeLabel('authored'). ifNotExists(). from('person').to('book'). create()The edge label
authoredis defined, along with the outgoing vertex labelpersonand the incoming vertex labelbook. -
Insert an edge between Julia Child and one of her cookbooks:
g.V('dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd').as('a'). V('dseg:/book/1001').as('b'). addE('authored').from('a').to('b')In this query, each vertex is defined and given a temporary label,
personasaandbookasb, and the temporary labels used to add the edge withaddE().from().to(). The partition key and value for each vertex must be included in the query.Use Graph view in Studio to see the relationship. Scroll over elements to display additional information.
The Studio result:
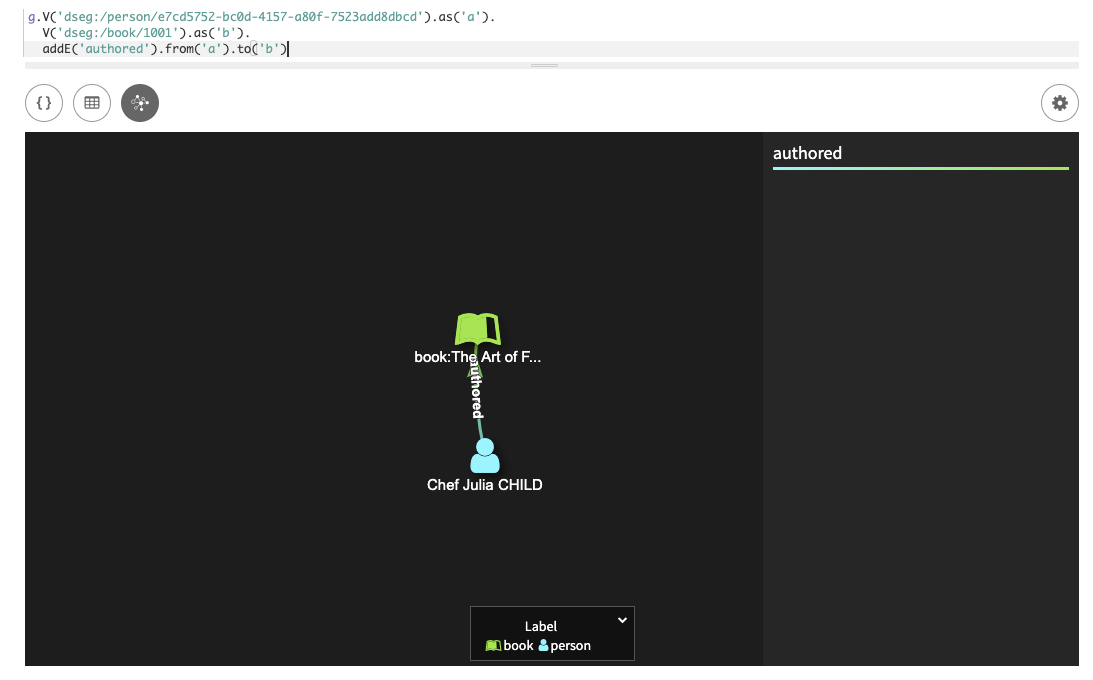
The Gremlin console result:
==>e[dseg:/person-authored-book/e7cd5752-bc0d-4157-a80f-7523add8dbcd/1001][dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd-authored->dseg:/book/1001] -
In Studio, the results are easy to visualize and check. In the Gremlin console, ensure that the data inserted for the vertices is correct by checking with a query that gets all vertices. All of the commands can be executed in Studio as well as Gremlin console. In production, DSG prevents expensives queries from processing. In development, include the
with("label-warning", false)so that a query can run without specifying vertex labels.g.with("label-warning", false).V().
The Gremlin console result:
==>v[dseg:/book/1001] ==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd] -
Similarly, the edge data inserted can be checked with a query that gets all edges:
g.with("label-warning", false).E()The Gremlin console result:
==>e[dseg:/person-authored-book/e7cd5752-bc0d-4157-a80f-7523add8dbcd/1001][dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd-authored->dseg:/book/1001] -
A much more useful query would check the data for a vertex using a simple bit of information, like a person’s name. However, without adding an index for
name, this query will fail, because the value for the primary keyperson_idis not supplied. For example:g.V().has('person', 'name', 'Julia CHILD')Two alternatives exist, a development mode for running queries and a modifier mode
with('allow-filtering'). Thedevmode is intended for early exploration, before appropriate indexes have been settled upon:dev.V().hasLabel('person').has('name', 'Julia CHILD')An alternative in development is to use the
with('allow-filtering')step which will do a full scan of all partitions:g.with('allow-filtering').V().has('person', 'name', 'Julia CHILD')Both commands will return the same information, the vertex id for the vertex found with the query. In Studio:
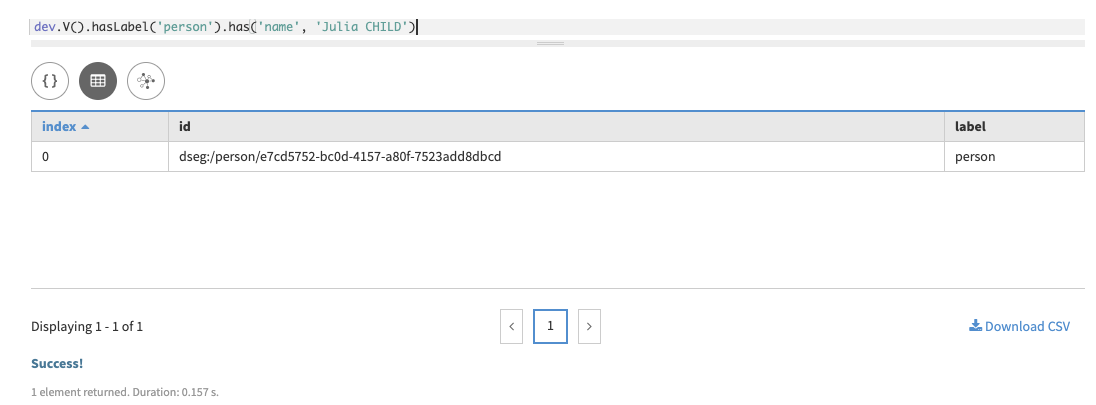
and in Gremlin console:
==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd] -
You’ll notice when you tried the command
g.V().has('person', 'name', 'Julia CHILD'), you got an error message that provides the index required to do the query in a production-safe manner:schema.vertexLabel('person'). materializedView('person_by_name'). ifNotExists(). partitionBy('name'). clusterBy('person_id', Asc). create()Note that while the index has been created successfully, it may not yet be finished building. Alternatively, use '.waitForIndex(<optionalTimeout>).create()' during index creation to wait for the index to be built. OKThe index is created as a materialized view table, with a partition key of the column to index and a clustering column of the original table’s partition key. Once the index exists, the query will run without doing a full scan. Indexing is a large topic that is worth reading about, as efficient queries depend on indexes.
-
Notice that the original query about Julia Child will now run without warnings, after the index is created, and returns the same information as the development queries:
g.V().has('person', 'name', 'Julia CHILD') -
We now have data! Let’s see what kind of graph queries can be executed. First, check the data using the unique partition key:
g.V().has('person', 'person_id', UUID.fromString('e7cd5752-bc0d-4157-a80f-7523add8dbcd'))In Studio:
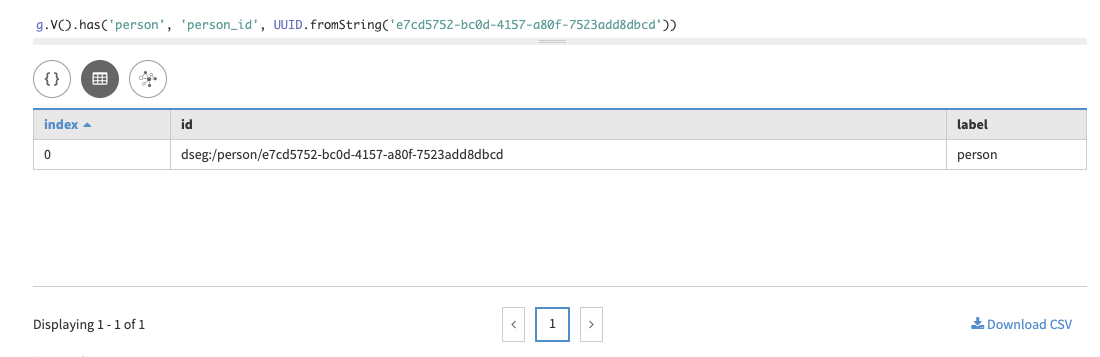
In Gremlin console:
==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd]While the partition key will be useful in some queries, generally queries use more user-friendly data, like
nameorcategory, to find vertices. -
Two other useful traversals are
elementMap()andvalueMap()which print the key-value listing of each property value for specified vertices.g.V().hasLabel('person').elementMap()In Studio:
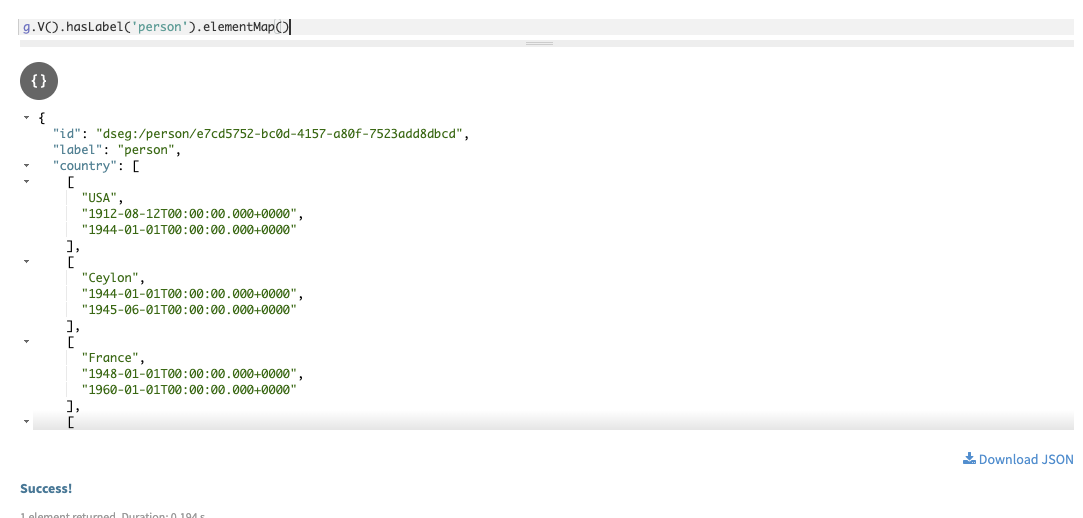
Using
elementMap()orvalueMap()without specifying properties can result in slow query latencies, if a large number of property keys exist for the queried vertex or edge. Specific properties can be specified, such aselementMap('name') or``valueMap('name').In Gremlin console:
gremlin> g.V().hasLabel('person').elementMap() ==>{id=dseg:/person/4ce9caf1-25b8-468e-a983-69bad20c017a, label=person, gender=M, name=James BEARD, nickname=[Jim, Jimmy], person_id=4ce9caf1-25b8-468e-a983-69bad20c017a} ==>{id=dseg:/person/888ad970-0efc-4e2c-b234-b6a71c30efb5, label=person, gender=M, name=Fritz STREIFF, person_id=888ad970-0efc-4e2c-b234-b6a71c30efb5} ==>{id=dseg:/person/4954d71d-f78c-4a6d-9c4a-f40903edbf3c, label=person, cal_goal=1800, gender=M, macro_goal=[30, 20, 50], name=John Smith, nickname=[Johnie], person_id=4954d71d-f78c-4a6d-9c4a-f40903edbf3c} ==>{id=dseg:/person/01e22ca6-da10-4cf7-8903-9b7e30c25805, label=person, gender=F, name=Kelsie KERR, person_id=01e22ca6-da10-4cf7-8903-9b7e30c25805} ==>{id=dseg:/person/6c09f656-5aef-46df-97f9-e7f984c9a3d9, label=person, cal_goal=1500, gender=F, macro_goal=[50, 15, 35], name=Jane DOE, nickname=[Janie], person_id=6c09f656-5aef-46df-97f9-e7f984c9a3d9} ==>{id=dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd, label=person, country=[('USA','1912-08-12','1944-01-01'), ('Ceylon','1944-01-01','1945-06-01'), ('France','1948-01-01','1950-01-01'), ('USA','1960-01-01','2004-08-13')], gender=F, name=Julia CHILD, nickname=[Jay, Julia], person_id=e7cd5752-bc0d-4157-a80f-7523add8dbcd}Using
valueMap()returns similar information in a slightly different container, but doesn’t include the elementidandlabel. Try out the command and compare! In DSG 6.8.0,valueMap()is deprecated, so useelementMap().
QuickStart Vertex and edge counting
Methods for counting vertices and edges in DataStax Graph.
About this task
There are different methods for accomplishing vertex and edge counts in DataStax Graph (DSG). Examples here will show how to use the Gremlin count() command as a transactional query. If large datasets are queried, analytical (OLAP) queries using DSE Analytics should be considered.
A transactional Gremlin query can be used to check the number of vertices that exist in the graph, and is useful for exploring small graphs. However, such a query scans the full graph, traversing every vertex, and should not be run on large graphs! If multiple DSE nodes are configured, this traversal step intensively walks all partitions on all nodes in the cluster that have graph data.
|
Remember, this method is not appropriate for large graphs or production operations. |
An analytical Gremlin query can be used to check the number of vertices that exist in any graph, large or small, and are much safer for production operations. The queries will be written like transactional Gremlin queries, but executed with the analytic Apache Spark™ engine. In Studio, use the execution button to select OLTP or OLAP. In Gremlin console, set the graph traversal source to OLAP before executing the query. DSE Analytics must be enabled on the cluster to use this option.
Vertex and edge counts can also be queried directly from the CQL tables for each vertex label and edge label, once the schema is defined.
|
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with |
Procedure
-
Transactional Gremlin vertex count()
-
Use the traversal step
count(). A graph traversalgis chained withV()to retrieve all vertices andcount()to compute the number of vertices. Chaining executes sequential traversal steps in the most efficient order.g.V().count()In Studio, the result is:
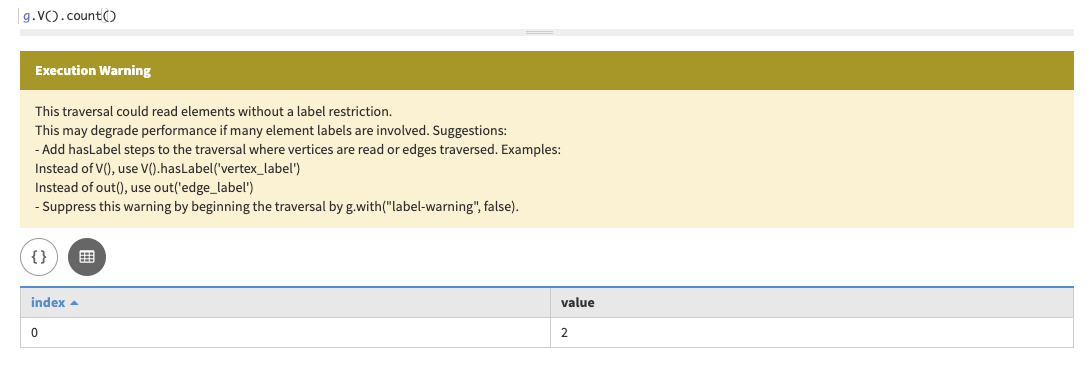
In Gremlin console, the result is:
==>2An instructional warning will be thrown, advising that this command can result in long latency if run without assisting options.
[warn] This traversal could read elements without a label restriction. This may degrade performance if many element labels are involved. Suggestions: - Add hasLabel steps to the traversal where vertices are read or edges traversed. Examples: Instead of V(), use V().hasLabel('vertex_label') Instead of out(), use out('edge_label') - Suppress this warning by beginning the traversal by g.with("label-warning", false). -
Transactional Gremlin edge counts
-
To do an edge count with Gremlin, replace
V()withE():g.E().count()In Studio, the result is:
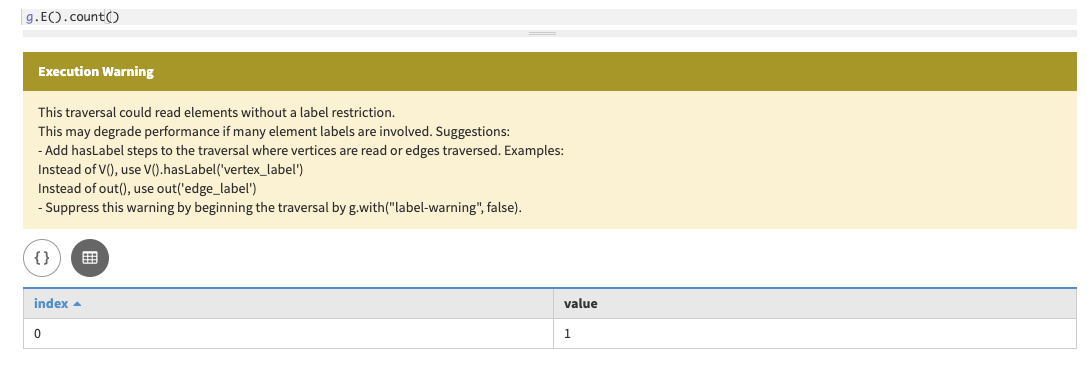
In Gremlin console, the result is:
==>1An instructional warning will be thrown, advising that this command can result in long latency if run without assisting options.
[warn] This traversal could read elements without a label restriction. This may degrade performance if many element labels are involved. Suggestions: - Add hasLabel steps to the traversal where vertices are read or edges traversed. Examples: Instead of V(), use V().hasLabel('vertex_label') Instead of out(), use out('edge_label') - Suppress this warning by beginning the traversal by g.with("label-warning", false). -
Analytical Gremlin vertex count()
Restriction: The following steps will only execute if DSE Analytics is enabled. Do not run if only Graph is enabled on the cluster.
-
To use Studio, configure the Run option to "Execute using analytic engine (Spark)" before running the query. A result similar to the tranactional query will result.
-
To use Gremlin console, first configure the traversal to run an analytical query:
:remote config alias g food_qs.awhere
food_qs.adenotes that the graph will be used for analytic purposes. Then run the command:g.V().count()If DSE Analytics is not enabled, this query will fail.
-
Vertex and edge counts using CQL
-
Use the CQL statement
SELECT count(*)to retrieve the count of either vertices or edges with an appropriate CQL table. For instance, retrieve the count ofpersonvertices:SELECT count(*) FROM food_qs.person;In order to retrieve a count of all vertices, query each vertex label table.
count ------- 1 (1 rows) -
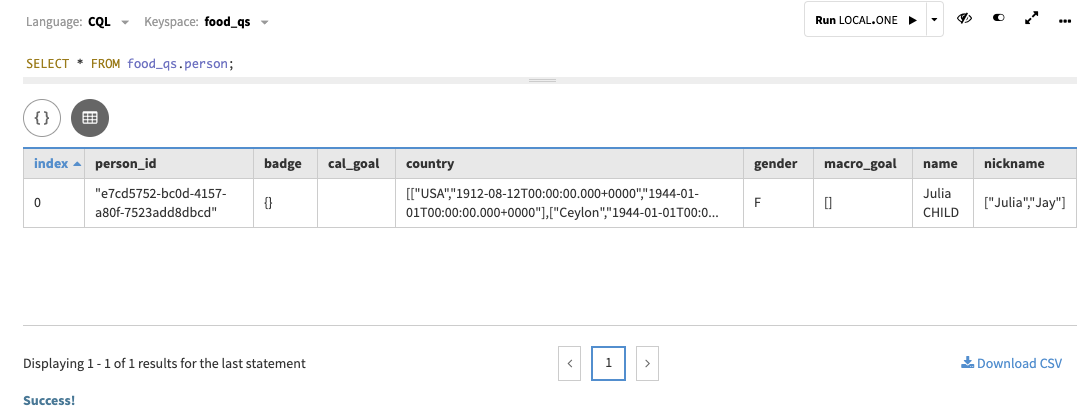
Retrieve the count of
person->authored->bookedges:SELECT count(*) FROM food_qs.person__authored__book;In order to retrieve a count of all vertices, query each vertex label table.
In Studio:
In Gremlin console:
count ------- 1 (1 rows)
QuickStart Graph schema
Working with graph schema.
About this task
Before adding more data to the graph, let’s stop and talk about schemas, which define both vertex labels and edge labels along with their associated properties and data types. User-defined types (UDTs) are a feature of DSG and must be created before use as a data type in schema. Schema creation also includes index creation. Indexes play an important role in making graph traversals efficient and fast. See creating schema and creating indexes for more information.
Schema can also be modified after creation, adding properties to vertex labels or edge labels with addProperty() and alter().
Let’s create additional schema for the food graph. These steps demonstrate dropping and creating schema.
|
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with |
Procedure
-
Drop the previously-created schema. The new schema could be added, but this step ensures that no leftover schema or data corrupts the graph.
schema.drop()Dropping schema will drop all data associated with the schema. Schema can be also be dropped individually for vertex labels, edge labels, properties and indexes.
-
User-defined type (UDT) schema
-
Create some useful UDTs for the vertex labels in the next step:
// Create user-defined types (UDTs) with Gremlin // VERTEX LABELS // ******** // SYNTAX: // schema.type('typename') // [ .ifNotExists() ] // [ .property(property, propertyType) ] // [ .create() | .describe() ] // USER-DEFINED TYPE // START-createUDT_address schema.type('address'). ifNotExists(). property('address1', Text). property('address2', Text). property('city_code', Text). property('state_code', Text). property('zip_code', Text). create() // END-createUDT_address // START-createUDT_fullname schema.type('fullname'). ifNotExists(). property('firstname', Text). property('lastname', Text). create() // END-createUDT_fullname //Using a nested user defined type via typeOf: // START-createUDT_locDet schema.type('location_details'). ifNotExists(). property('loc_address', frozen(typeOf('address'))). property('telephone', listOf(Text)). create() // END-createUDT_locDetNested UDTs are acceptable in DataStax Graph, like the use of
addressinlocation_details.The results of the UDT creation can be examined with:
schema.types().describe()The Gremlin console result:
==>schema.type('address').ifNotExists().property('address1', Varchar).property('address2', Varchar).property('city_code', Varchar).property('state_code', Varchar).property('zip_code', Varchar).create() schema.type('fullname').ifNotExists().property('firstname', Varchar).property('lastname', Varchar).create() schema.type('location_details').ifNotExists().property('loc_address', frozen(typeOf('address'))).property('telephone', listOf(Varchar)).create() -
Vertex label schema
-
Create all the vertex labels for the food graph:
// VERTEX LABELS // ******** // SYNTAX: // schema.vertexLabel('vertexLabel') // [ .ifNotExists() ] // .partitionBy('propertyName', propertyType) [ ... ] // [ .clusterBy('propertyName', propertyType) ... ] // [ .property('propertyName', propertyType) ] // [ .create() | .describe() | .addProperty('propertyName', propertyType).alter() ] // SINGLE PARTITION KEY Vertex Labels // macro_goal is a list of carbohydrate, protein, fat // country is a list of tuple of country, start date, end date; replacement for a meta-property in classic graph // Also, country demonstrates multi-property, being a list of countries and dates lived in // country, start_date, end_date // badge is a replacement for a meta-property in earlier versions // level:year, such as gold:2015, expert:2019, or sous-chef:2009 (mainly expect to use for reviewers) // NEED TO ADD NEW FEATURE DSP_18625 // .tableName('personTable') // START-createVL_person schema.vertexLabel('person'). ifNotExists(). partitionBy('person_id', Uuid). property('name', Text). property('gender', Text). property('nickname', setOf(Text)). property('cal_goal', Int). property('macro_goal', listOf(Int)). property('country', listOf(tupleOf(Text, Date, Date))). property('badge', mapOf(Text, Date)). create() // END-createVL_person // book_discount was a property in the old data model that had a ttl; I'm including here to use the same datasets // Add as an added property //property('book_discount', Text). // START-createVL_book schema.vertexLabel('book'). ifNotExists(). partitionBy('book_id', Int). property('name', Text). property('publish_year', Int). property('isbn', Text). property('category', setOf(Text)). create() // END-createVL_book // Going to create vertexLabel recipe through converting a CQL table to a VL // Although the notebook shows creating a table for recipe with CQL, then converting, // this is the Gremlin schema to make the recipe vertex label // START-createVL_recipe schema.vertexLabel('recipe'). ifNotExists(). partitionBy('recipe_id', Int). property('name', Text). property('cuisine', setOf(Text)). property('instructions', Text). property('notes', Text). create() // END-createVL_recipe // START-createVL_item_meal schema.vertexLabel('meal_item'). ifNotExists(). partitionBy('item_id', Int). property('name', Text). property('serv_amt', Text). property('macro', listOf(Int)). property('calories', Int). create() // END-createVL_item_meal // START-createVL_ingredient schema.vertexLabel('ingredient'). ifNotExists(). partitionBy('ingred_id', Int). property('name', Text). create() // END-createVL_ingredient // START-createVL_home schema.vertexLabel('home'). ifNotExists(). partitionBy('home_id', Int). property('name', Text). create() // END-createVL_home // START-createVL_store schema.vertexLabel('store'). ifNotExists(). partitionBy('store_id', Int). property('name', Text). create() // END-createVL_store // MULTIPLE-KEY VERTEX ID // START-createVL_meal schema.vertexLabel('meal'). ifNotExists(). partitionBy('type', Text). partitionBy( 'meal_id', Int). create() // END-createVL_meal // COMPOSITE KEY VERTEX ID // START-createVL_fridge_sensor schema.vertexLabel('fridge_sensor'). ifNotExists(). partitionBy('state_id', Int). partitionBy('city_id', Int). partitionBy('zipcode_id', Int). clusterBy('sensor_id', Int). property('name', Text). create() // END-createVL_fridge_sensor // GEOSPATIAL // START-createVL_location schema.vertexLabel('location'). ifNotExists(). partitionBy('loc_id', Text). property('name', Text). property('loc_details', frozen(typeOf('location_details'))). property('geo_point', Point). create() // END-createVL_location // STATIC COLUMN // START-createVL_flag schema.vertexLabel('flag'). ifNotExists(). partitionBy('country_id', Int). clusterBy('country', Text). property('flag', Text, Static). create() // END-createVL_flagEach property must be defined with a valid CQL data type. By default, properties have single cardinality, but can be defined with multiple cardinality using collections. Multiple cardinality allows more than one value to be assigned to a property.
In addition, properties can have their own properties using nested collections such as
listOf(tupleOf); in older versions these properties were called meta-properties. Notice that vertex labels can be created withifNotExists(), to prevent overwriting a definition that already exists.DataStax Graph limits the number of vertex and edge labels to 200 per graph.
-
Add property to a vertex label
-
The schema for vertex labels defines the label type, at least one partition key, optional clustering columns, and properties. Additionally, properties can be added later:
// START-addVLProp schema.vertexLabel('book'). addProperty('book_discount', Text). alter() // END-addVLPropNote the use of
alter()to change the vertex label schema. -
Edge label schema
-
Create the food edge labels:
// ******** // EDGE LABELS // ******** // SYNTAX: //schema.edgeLabel('edgeLabel'). // [ materializedView('indexName'). | secondaryIndex('indexName'). | searchIndex('indexName'). | inverse(). ] // [ by('propertyName'). ] // [ tableName('tableName'). ] // [ ifNotExists(). ] // from('vertexLabel'). // to('vertexLabel'). // [ partitionBy('propertyName', propertyType). [ ... ] ] // [ clusterBy('propertyName', propertyType). [ ... ] ] // [ property('propertyName', propertyType). ] // [ create() | describe() | drop() | // addProperty('propertyName', propertyType).alter() | // dropProperty('propertyName', propertyType).alter() ] // [fromExistingTable('tableName') // from('vertexLabel'). [ mappingProperty('CQLPropertyName'). ] // to('vertexLabel'). [ mappingProperty('CQLPropertyName'). ]] // ******** // START-createELs_person_authored_book schema.edgeLabel('authored'). ifNotExists(). from('person').to('book'). create() // END-createELs_person_authored_book // START-createELs_person_ate_meal schema.edgeLabel('ate'). tableName('person_eating'). ifNotExists(). from('person').to('meal'). property('meal_date', Date). create() // END-createELs_person_ate_meal // START-createELs_person_knows_person schema.edgeLabel('knows'). ifNotExists(). from('person').to('person'). property('since', Date). create() // END-createELs_person_knows_person // START-createELs_meal_includes_mealItem schema.edgeLabel('includes'). ifNotExists(). from('meal').to('meal_item'). property('num_serv', Int). create() // END-createELs_meal_includes_mealItem // START-createELs_recipe_includes_ingredient schema.edgeLabel('includes'). ifNotExists(). from('recipe').to('ingredient'). property('amount', Text). create() // END-createELs_recipe_includes_ingredient // START-createELs_recipe_included_in_meal schema.edgeLabel('included_in'). ifNotExists(). from('recipe').to('meal'). property('amount', Text). create() // END-createELs_recipe_included_in_meal // START-createELs_recipe_included_in_book schema.edgeLabel('included_in'). ifNotExists(). from('recipe').to('book'). create() // END-createELs_recipe_included_in_book // START-createELs_person_created_recipe schema.edgeLabel('created'). ifNotExists(). from('person').to('recipe'). property('create_date', Date). create() // END-createELs_person_created_recipe // START-createELs_person_reviewed_recipe schema.edgeLabel('reviewed'). ifNotExists(). from('person').to('recipe'). property('time', Time). property('year', Date). property('stars', Int). property('comment', Text). create() // END-createELs_person_reviewed_recipe // START-createELs_fridge_sensor_contains_ingredient schema.edgeLabel('contains'). ifNotExists(). from('fridge_sensor').to('ingredient'). property('expire_date', Date). create() // END-createELs_fridge_sensor_contains_ingredient // START-createELs_store_is_stocked_with_ingredient schema.edgeLabel('is_stocked_with'). ifNotExists(). from('store').to('ingredient'). property('expire_date', Date). create() // END-createELs_store_is_stocked_with_ingredient // START-createELs_home_is_located_at_location schema.edgeLabel('is_located_at'). ifNotExists(). from('home').to('location'). create() // END-createELs_home_is_located_at_location // START-createELs_store_isLocatedAt_location schema.edgeLabel('is_located_at'). ifNotExists(). from('store').to('location'). create() // END-createELs_store_isLocatedAt_location //START-createELs_fridge_sensor_is_located_at_home schema.edgeLabel('is_located_at'). ifNotExists(). from('fridge_sensor').to('home'). create() //END-createELs_fridge_sensor_is_located_at_homeThe schema for edge labels defines the label type, and defines the two vertex labels that are connected by the edge label with
from()andto(). Thereviewededge label defines edges between adjacent vertices with the outgoing vertex labelpersonand the incoming vertex labelrecipe. By default, edges have single cardinality. To specify multiple edges between two unique vertex labels, a distinguishing edge property must be included in the edge label schema. -
Add properties to vertex labels or edge labels
-
Alter the vertex label
bookby adding the propertybook_discount:schema.vertexLabel('book'). addProperty('book_discount', Text). alter()Properties can also be added to edge labels using the same steps.
-
Add a property to an edge label to demonstrate dropping a property later in the QuickStart with either:
schema.edgeLabel('authored'). addProperty('one', Int). addProperty('two', Int). alter()or with additional information about which particular edge label between two defined vertex labels:
schema.edgeLabel('authored'). from('person'). to('book'). addProperty('one', Int). addProperty('two', Int). alter()
QuickStart Inspecting schema
Inspect graph schema.
About this task
The schema.describe() query displays schema that can be used to recreate the schema entered or verify schema settings.
Additional steps can display the schema of all elements such as vertex labels, or the schema for a particular element.
Procedure
-
Examine all the schema:
schema.describe()In Studio, a portion of the output:

The Gremlin console result:
==>schema.type('address').ifNotExists().property('address1', Varchar).property('address2', Varchar).property('city_code', Varchar).property('state_code', Varchar).property('zip_code', Varchar).create() schema.type('fullname').ifNotExists().property('firstname', Varchar).property('lastname', Varchar).create() schema.type('location_details').ifNotExists().property('loc_address', frozen(typeOf('address'))).property('telephone', listOf(Varchar)).create() schema.vertexLabel('book').ifNotExists().partitionBy('book_id', Int).property('book_discount', Varchar).property('isbn', Varchar).property('name', Varchar).property('publish_year', Int).property('category', setOf(Varchar)).create() schema.vertexLabel('flag').ifNotExists().partitionBy('country_id', Int).clusterBy('country', Varchar, Asc).property('flag', Varchar, Static).create() schema.vertexLabel('fridge_sensor').ifNotExists().partitionBy('state_id', Int).partitionBy('city_id', Int).partitionBy('zipcode_id', Int).clusterBy('sensor_id', Int, Asc).property('name', Varchar).create() schema.vertexLabel('home').ifNotExists().partitionBy('home_id', Int).property('name', Varchar).create() schema.vertexLabel('ingredient').ifNotExists().partitionBy('ingred_id', Int).property('name', Varchar).create() schema.vertexLabel('location').ifNotExists().partitionBy('loc_id', Varchar).property('geo_point', Point).property('loc_details', frozen(typeOf('location_details'))).property('name', Varchar).create() schema.vertexLabel('meal').ifNotExists().partitionBy('type', Varchar).partitionBy('meal_id', Int).create() schema.vertexLabel('meal_item').ifNotExists().partitionBy('item_id', Int).property('calories', Int).property('name', Varchar).property('serv_amt', Varchar).property('macro', listOf(Int)).create() schema.vertexLabel('person').ifNotExists().partitionBy('person_id', Uuid).property('cal_goal', Int).property('gender', Varchar).property('name', Varchar).property('badge', mapOf(Varchar, Date)).property('country', listOf(tupleOf(Varchar, Date, Date))).property('macro_goal', listOf(Int)).property('nickname', setOf(Varchar)).create() schema.vertexLabel('recipe').ifNotExists().partitionBy('recipe_id', Int).property('instructions', Varchar).property('name', Varchar).property('notes', Varchar).property('cuisine', setOf(Varchar)).create() schema.vertexLabel('store').ifNotExists().partitionBy('store_id', Int).property('name', Varchar).create() schema.edgeLabel('contains').ifNotExists().from('fridge_sensor').to('ingredient').partitionBy(OUT, 'state_id', 'fridge_sensor_state_id').partitionBy(OUT, 'city_id', 'fridge_sensor_city_id').partitionBy(OUT, 'zipcode_id', 'fridge_sensor_zipcode_id').clusterBy(OUT, 'sensor_id', 'fridge_sensor_sensor_id', Asc).clusterBy(IN, 'ingred_id', 'ingredient_ingred_id', Asc).property('expire_date', Date).create() schema.edgeLabel('is_located_at').ifNotExists().from('fridge_sensor').to('location').partitionBy(OUT, 'state_id', 'fridge_sensor_state_id').partitionBy(OUT, 'city_id', 'fridge_sensor_city_id').partitionBy(OUT, 'zipcode_id', 'fridge_sensor_zipcode_id').clusterBy(OUT, 'sensor_id', 'fridge_sensor_sensor_id', Asc).clusterBy(IN, 'loc_id', 'location_loc_id', Asc).create() schema.edgeLabel('is_located_at').ifNotExists().from('home').to('location').partitionBy(OUT, 'home_id', 'home_home_id').clusterBy(IN, 'loc_id', 'location_loc_id', Asc).create() schema.edgeLabel('includes').ifNotExists().from('ingredient').to('recipe').partitionBy(OUT, 'ingred_id', 'ingredient_ingred_id').clusterBy(IN, 'recipe_id', 'recipe_recipe_id', Asc).property('amount', Varchar).create() schema.edgeLabel('includes').ifNotExists().from('meal').to('meal_item').partitionBy(OUT, 'type', 'meal_type').partitionBy(OUT, 'meal_id', 'meal_meal_id').clusterBy(IN, 'item_id', 'meal_item_item_id', Asc).property('num_serv', Int).create() schema.edgeLabel('ate').ifNotExists().from('person').to('meal').partitionBy(OUT, 'person_id', 'person_person_id').clusterBy(IN, 'type', 'meal_type', Asc).clusterBy(IN, 'meal_id', 'meal_meal_id', Asc).property('meal_date', Date).create() schema.edgeLabel('authored').ifNotExists().from('person').to('book').partitionBy(OUT, 'person_id', 'person_person_id').clusterBy(IN, 'book_id', 'book_book_id', Asc).create() schema.edgeLabel('created').ifNotExists().from('person').to('recipe').partitionBy(OUT, 'person_id', 'person_person_id').clusterBy(IN, 'recipe_id', 'recipe_recipe_id', Asc).property('create_date', Date).create() schema.edgeLabel('knows').ifNotExists().from('person').to('person').partitionBy(OUT, 'person_id', 'out_person_id').clusterBy(IN, 'person_id', 'in_person_id', Asc).property('since', Date).create() schema.edgeLabel('reviewed').ifNotExists().from('person').to('recipe').partitionBy(OUT, 'person_id', 'person_person_id').clusterBy(IN, 'recipe_id', 'recipe_recipe_id', Asc).property('comment', Varchar).property('stars', Int).property('time', Time).property('year', Date).create() schema.edgeLabel('included_in').ifNotExists().from('recipe').to('book').partitionBy(OUT, 'recipe_id', 'recipe_recipe_id').clusterBy(IN, 'book_id', 'book_book_id', Asc).create() schema.edgeLabel('included_in').ifNotExists().from('recipe').to('meal').partitionBy(OUT, 'recipe_id', 'recipe_recipe_id').clusterBy(IN, 'type', 'meal_type', Asc).clusterBy(IN, 'meal_id', 'meal_meal_id', Asc).property('amount', Varchar).create() schema.edgeLabel('is_located_at').ifNotExists().from('store').to('location').partitionBy(OUT, 'store_id', 'store_store_id').clusterBy(IN, 'loc_id', 'location_loc_id', Asc).create() schema.edgeLabel('is_stocked_with').ifNotExists().from('store').to('ingredient').partitionBy(OUT, 'store_id', 'store_store_id').clusterBy(IN, 'ingred_id', 'ingredient_ingred_id', Asc).property('expire_date', Date).create() schema.vertexLabel('book').searchIndex().ifNotExists().by('book_id').by('name').asString().by('publish_year').create() schema.vertexLabel('ingredient').materializedView('ingredient_by_name').ifNotExists().partitionBy('name').clusterBy('ingred_id', Asc).create() schema.vertexLabel('location').materializedView('location_by_name').ifNotExists().partitionBy('name').clusterBy('loc_id', Asc).create() schema.vertexLabel('location').searchIndex().ifNotExists().by('loc_id').asString().by('geo_point').create() schema.vertexLabel('meal').materializedView('meal_by_type').ifNotExists().partitionBy('type').clusterBy('meal_id', Asc).create() schema.vertexLabel('meal_item').materializedView('meal_item_by_name').ifNotExists().partitionBy('name').clusterBy('item_id', Asc).create() schema.vertexLabel('person').materializedView('person_by_name').ifNotExists().partitionBy('name').clusterBy('person_id', Asc).create() schema.vertexLabel('person').secondaryIndex('person_2i_by_badge').ifNotExists().by('badge').indexKeys().create() schema.vertexLabel('person').secondaryIndex('person_2i_by_country').ifNotExists().by('country').indexValues().create() schema.vertexLabel('person').secondaryIndex('person_2i_by_nickname').ifNotExists().by('nickname').indexValues().create() schema.vertexLabel('person').searchIndex().ifNotExists().by('person_id').by('country').create() schema.vertexLabel('recipe').materializedView('recipe_by_name').ifNotExists().partitionBy('name').clusterBy('recipe_id', Asc).create() schema.vertexLabel('recipe').secondaryIndex('recipe_2i_by_cuisine').ifNotExists().by('cuisine').indexValues().create() schema.vertexLabel('recipe').searchIndex().ifNotExists().by('recipe_id').by('instructions').create() schema.edgeLabel('reviewed').from('person').to('recipe').materializedView('person__reviewed__recipe_by_person_person_id_stars').ifNotExists().partitionBy(OUT, 'person_id').partitionBy('stars').clusterBy(IN, 'recipe_id', Asc).create() schema.edgeLabel('reviewed').from('person').to('recipe').materializedView('person__reviewed__recipe_by_person_person_id_year').ifNotExists().partitionBy(OUT, 'person_id').clusterBy('year', Asc).clusterBy(IN, 'recipe_id', Asc).create() -
Examine all the vertex labels in the schema:
schema.vertexLabels().describe()All edge labels can be examined by replacing
vertexLabels()withedgeLabels().In Studio, a portion of the output:

The Gremlin console result:
==>schema.vertexLabel('person').ifNotExists().partitionBy('person_id', Uuid).property('cal_goal', Int).property('gender', Varchar).property('name', Varchar).property('badge', mapOf(Varchar, Date)).property('country', listOf(tupleOf(Varchar, Date, Date))).property('macro_goal', listOf(Int)).property('nickname', setOf(Varchar)).create() schema.vertexLabel('recipe').ifNotExists().partitionBy('recipe_id', Int).property('instructions', Varchar).property('name', Varchar).property('notes', Varchar).property('cuisine', setOf(Varchar)).create() schema.vertexLabel('meal_item').ifNotExists().partitionBy('item_id', Int).property('calories', Int).property('name', Varchar).property('serv_amt', Varchar).property('macro', listOf(Int)).create() schema.vertexLabel('ingredient').ifNotExists().partitionBy('ingred_id', Int).property('name', Varchar).create() schema.vertexLabel('home').ifNotExists().partitionBy('home_id', Int).property('name', Varchar).create() schema.vertexLabel('store').ifNotExists().partitionBy('store_id', Int).property('name', Varchar).create() schema.vertexLabel('meal').ifNotExists().partitionBy('type', Varchar).partitionBy('meal_id', Int).create() schema.vertexLabel('fridge_sensor').ifNotExists().partitionBy('state_id', Int).partitionBy('city_id', Int).partitionBy('zipcode_id', Int).clusterBy('sensor_id', Int, Asc).property('name', Varchar).create() schema.vertexLabel('location').ifNotExists().partitionBy('loc_id', Varchar).property('geo_point', Point).property('loc_details', frozen(typeOf('location_details'))).property('name', Varchar).create() schema.vertexLabel('flag').ifNotExists().partitionBy('country_id', Int).clusterBy('country', Varchar, Asc).property('flag', Varchar, Static).create() schema.vertexLabel('book').ifNotExists().partitionBy('book_id', Int).property('book_discount', Varchar).property('isbn', Varchar).property('name', Varchar).property('publish_year', Int).property('category', setOf(Varchar)).create() schema.vertexLabel('book').searchIndex().ifNotExists().by('book_id').by('name').asString().by('publish_year').create() schema.vertexLabel('ingredient').materializedView('ingredient_by_name').ifNotExists().partitionBy('name').clusterBy('ingred_id', Asc).create() schema.vertexLabel('location').materializedView('location_by_name').ifNotExists().partitionBy('name').clusterBy('loc_id', Asc).create() schema.vertexLabel('location').searchIndex().ifNotExists().by('loc_id').asString().by('geo_point').create() schema.vertexLabel('meal').materializedView('meal_by_type').ifNotExists().partitionBy('type').clusterBy('meal_id', Asc).create() schema.vertexLabel('meal_item').materializedView('meal_item_by_name').ifNotExists().partitionBy('name').clusterBy('item_id', Asc).create() schema.vertexLabel('person').materializedView('person_by_name').ifNotExists().partitionBy('name').clusterBy('person_id', Asc).create() schema.vertexLabel('person').secondaryIndex('person_2i_by_badge').ifNotExists().by('badge').indexKeys().create() schema.vertexLabel('person').secondaryIndex('person_2i_by_country').ifNotExists().by('country').indexValues().create() schema.vertexLabel('person').secondaryIndex('person_2i_by_nickname').ifNotExists().by('nickname').indexValues().create() schema.vertexLabel('person').searchIndex().ifNotExists().by('person_id').by('country').create() schema.vertexLabel('recipe').materializedView('recipe_by_name').ifNotExists().partitionBy('name').clusterBy('recipe_id', Asc).create() schema.vertexLabel('recipe').secondaryIndex('recipe_2i_by_cuisine').ifNotExists().by('cuisine').indexValues().create() schema.vertexLabel('recipe').searchIndex().ifNotExists().by('recipe_id').by('instructions').create() -
Examine the
personvertex label in the schema:schema.vertexLabel('person').describe()A particular edge label can be examined by replacing
vertexLabel('person')withedgeLabel('authored').In Studio, a portion of the output:

The Gremlin console result:
==>schema.vertexLabel('person').ifNotExists().partitionBy('person_id', Uuid).property('cal_goal', Int).property('gender', Varchar).property('name', Varchar).property('badge', mapOf(Varchar, Date)).property('country', listOf(tupleOf(Varchar, Date, Date))).property('macro_goal', listOf(Int)).property('nickname', setOf(Varchar)).create() schema.vertexLabel('person').materializedView('person_by_name').ifNotExists().partitionBy('name').clusterBy('person_id', Asc).create() schema.vertexLabel('person').secondaryIndex('person_2i_by_badge').ifNotExists().by('badge').indexKeys().create() schema.vertexLabel('person').secondaryIndex('person_2i_by_country').ifNotExists().by('country').indexValues().create() schema.vertexLabel('person').secondaryIndex('person_2i_by_nickname').ifNotExists().by('nickname').indexValues().create() schema.vertexLabel('person').searchIndex().ifNotExists().by('person_id').by('country').create()
QuickStart Indexing
Index graph schema.
About this task
Indexing is an important subject in DSG, because indexes are a necessary component for successful completion of most graph queries in production environments.
The dev mode can be used to bypass the need for indexes during development, but it is important to familiarize yourself with indexes.
Indexes can be created:
-
manually as materialized view indexes, secondary indexes, or search indexes
-
using the index analyzer
indexFor()on desired graph queries -
for the specialized case of bidirectional indexing, using
inverse()
Materialized view and secondary indexes are two types of indexes that use Apache Cassandra built-in indexing.
Materialized views are good for queries that do not require predicate-based searches.
Secondary indexes allow indexing of properties stored in collections.
Search indexes use DSE Search which is Solr-based.
Only one search index per vertex label is allowed, but multiple properties can be included.
Note that indexes are manually added with create() for both vertex labels and edge labels.
See Creating index schema for complete examples of each type of index.
|
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with |
Procedure
-
Materialized view indexes
-
Discover a required materalized view index for the vertex label
personusing the index analyzer stepsindexFor()andanalyze():schema.indexFor(g.V().has('person', 'name', 'Julia CHILD')).analyze()==>Traversal requires that the following indexes are created: schema.vertexLabel('person').materializedView('person_by_name').ifNotExists().partitionBy('name').clusterBy('person_id', Asc).create() -
Create the required materalized view index for the vertex label
personusing the index analyzer stepsindexFor()andapply():schema.indexFor(g.V().has('person', 'name', 'Julia CHILD')).apply()Note that the only change is switching
apply()foranalyze()from the last step.==>Creating the following indexes: schema.vertexLabel('person').materializedView('person_by_name').ifNotExists().partitionBy('name').clusterBy('person_id', Asc).create() OK -
Materialized view indexes for vertex labels can also be made manually:
schema.vertexLabel('meal'). materializedView('meal_by_type'). ifNotExists(). partitionBy('type'). waitForIndex(). create() schema.vertexLabel('ingredient'). materializedView('ingredient_by_name'). ifNotExists(). partitionBy('name'). create() schema.vertexLabel('location'). materializedView('location_by_name'). ifNotExists(). partitionBy('name'). clusterBy('loc_id', Asc). create() schema.vertexLabel('meal_item'). materializedView('meal_item_by_name'). ifNotExists(). partitionBy('name'). clusterBy('item_id', Asc). create() schema.vertexLabel('recipe'). materializedView('recipe_by_name'). ifNotExists(). partitionBy('name'). clusterBy('recipe_id', Asc). create() -
Discover a required materalized view index for the edge label
person->reviewed->recipebased on review star ratingsstarsusing the index analyzer stepsindexFor()andanalyze():schema.indexFor(g.V().hasLabel('person').outE('reviewed').has('stars', 5)).analyze()==>Traversal requires that the following indexes are created: schema.edgeLabel('reviewed'). from('person').to('recipe'). materializedView('person__reviewed__recipe_by_person_person_id_stars'). ifNotExists(). partitionBy(OUT, 'person_id'). partitionBy('stars'). clusterBy(IN, 'recipe_id', Asc). create() -
Create the required materalized view index for the edge label
person->reviewed->recipeby applying the index analyzer:schema.indexFor(g.V().hasLabel('person').outE('reviewed').has('stars', 5)).apply()==>Creating the following indexes: schema.edgeLabel('reviewed').from('person').to('recipe').materializedView('person__reviewed__recipe_by_person_person_id_stars').ifNotExists().partitionBy(OUT, 'person_id').partitionBy('stars').clusterBy(IN, 'recipe_id', Asc).create() OK -
Materialized view indexes for edge labels can be made manually:
schema.edgeLabel('reviewed'). from('person').to('recipe'). materializedView('person__reviewed__recipe_by_person_person_id_year'). ifNotExists(). partitionBy(OUT, 'person_id'). clusterBy('year', Asc). clusterBy(IN, 'recipe_id', Asc). create()In this case, the index is created to discover recipe reviews that occur before or after a particular date.
-
Secondary indexes
-
Discover a required secondary index for the vertex label
recipebased on the cuisines stored in a collection of the recipe using the index analyzer stepsindexFor()andanalyze():schema.indexFor(g.V().has('recipe', 'cuisine', contains('French')).values('name')).analyze()==>Traversal requires that the following indexes are created: schema.vertexLabel('recipe').secondaryIndex('recipe_2i_by_cuisine').ifNotExists().by('cuisine').indexValues().create() -
Create the required secondary index for the vertex label
recipeby applying the index analyzer:schema.indexFor(g.V().has('recipe', 'cuisine', contains('French')).values('name')).apply()==>Creating the following indexes: schema.vertexLabel('recipe').secondaryIndex('recipe_2i_by_cuisine').ifNotExists().by('cuisine').indexValues().create() OK -
Secondary indexes for vertex labels can be made manually:
schema.vertexLabel('person'). secondaryIndex('person_2i_by_nickname'). ifNotExists(). by('nickname'). indexValues(). create() schema.vertexLabel('person'). secondaryIndex('person_2i_by_country'). ifNotExists(). by('country'). indexValues(). create() -
Search indexes
-
Discover a search index for the vertex label
recipethat requires a tokenized search of the propertyinstructionsusing the index analyzer stepsindexFor()andanalyze():schema.indexFor(g.V().has('recipe', 'instructions', token('Saute'))).analyze()==>Traversal requires that the following indexes are created: schema.vertexLabel('recipe').searchIndex().ifNotExists().by('instructions').create() -
Create the required search index for the edge label
recipeby applying the index analyzer:schema.indexFor(g.V().has('recipe', 'instructions', token('Saute'))).apply()==>Creating the following indexes: schema.vertexLabel('recipe').searchIndex().ifNotExists().by('instructions').create() OK -
Search indexes for vertex labels and edge labels can be made manually:
schema.vertexLabel('recipe'). searchIndex(). ifNotExists(). by('instructions').asText(). by('name'). by('cuisine'). waitForIndex(30). create() // schema.indexFor(g.V().has('book', 'publish_year', neq(1960))).analyze() // schema.indexFor(g.V().has('book', 'publish_year', eq(1961))).analyze() schema.vertexLabel('book'). searchIndex(). ifNotExists(). by('name'). by('publish_year'). create() schema.vertexLabel('store'). searchIndex(). ifNotExists(). by('name'). create() schema.vertexLabel('home'). searchIndex(). ifNotExists(). by('name'). create() schema.vertexLabel('fridge_sensor'). searchIndex(). ifNotExists(). by('city_id'). by('sensor_id'). by('name'). create() -
Geospatial search indexes
-
Discover a required secondary index for the edge label
person->reviewed->recipebased on review star ratingsstarsusing the index analyzer stepsindexFor()andanalyze():schema.indexFor(g.V().hasLabel('location').has('geo_point', Geo.inside(Geo.point(-110,30),20, Geo.Unit.DEGREES)).values('name')).analyze()==>Traversal requires that the following indexes are created: schema.vertexLabel('location').searchIndex().ifNotExists().by('geo_point').create() -
Create the required materalized view index for the edge label
person->reviewed->recipeby applying the index analyzer:schema.indexFor(g.V().hasLabel('location').has('geo_point', Geo.inside(Geo.point(-110,30),20, Geo.Unit.DEGREES)).values('name')).apply()==>Creating the following indexes: schema.vertexLabel('location').searchIndex().ifNotExists().by('geo_point').create() OKAs with the other index types, geospatial search indexes can be created manually.
-
inverse() edge indexes
-
Create a required
inverse()edge index for the edge labelperson->created->recipe:schema.edgeLabel('created'). from('person').to('recipe'). materializedView('person_recipe'). ifNotExists(). inverse(). create()==> OK
QuickStart Adding data
Adding data to a graph.
About this task
Now that the schema is created, data may be added using either the traversal method shown in the simple example or DataStax Bulk Loader. The existing data can be dropped from the graph before reloading.
Note the first commands drop all vertex and edge data from the graph, g.V().drop() and g.E().drop(), to clear all previously inserted data.
In Studio, be sure to select the Graph view after running the commands to verify the deletions.
|
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with |
Procedure
-
Adding more data using traversals
-
Drop the data previously loaded:
g.V().drop()g.E().drop() -
Load the vertices:
// START-insertAllPersons // person vertices g.addV('person'). property('person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID). property('name', 'Julia CHILD'). property('gender','F'). property('nickname', ['Jay', 'Julia'] as Set). property('country', [['USA', '1912-08-12' as LocalDate, '1944-01-01' as LocalDate] as Tuple, ['Ceylon', '1944-01-01' as LocalDate, '1945-06-01' as LocalDate] as Tuple, ['France', '1948-01-01' as LocalDate, '1950-01-01' as LocalDate] as Tuple, ['USA', '1960-01-01' as LocalDate, '2004-08-13' as LocalDate] as Tuple]). iterate(); g.addV('person'). property('person_id', 'adb8744c-d015-4d78-918a-d7f062c59e8f' as UUID). property('name', 'Simone BECK'). property('gender','F'). property('nickname', ['Simca', 'Simone'] as Set). property('country', [['France', '1904-07-07' as LocalDate, '1991-12-20' as LocalDate] as Tuple]). iterate(); g.addV('person'). property('person_id', '888ad970-0efc-4e2c-b234-b6a71c30efb5' as UUID). property('name', 'Fritz STREIFF'). property('gender','M'). iterate(); g.addV('person'). property('person_id', 'f092107c-0c5c-47e7-917c-c82c7fc2a2493' as UUID). property('name', 'Louisette BERTHOLIE'). property('gender','F'). iterate(); g.addV('person'). property('person_id', 'ef811281-f954-4fd6-ace0-bf67d057771a' as UUID). property('name', 'Patricia SIMON'). property('gender','F'). property('nickname', ['Pat'] as Set). iterate(); g.addV('person'). property('person_id', 'd45c76bc-6f93-4d0e-9d9f-33298dae0524' as UUID). property('name', 'Alice WATERS'). property('gender','F'). iterate(); g.addV('person'). property('person_id', '7f969e16-b81e-4fcd-87c5-1911abbed132' as UUID). property('name', 'Patricia CURTAN'). property('gender','F'). property('nickname', ['Pattie'] as Set). iterate(); g.addV('person'). property('person_id', '01e22ca6-da10-4cf7-8903-9b7e30c25805' as UUID). property('name', 'Kelsie KERR'). property('gender','F'). iterate(); g.addV('person'). property('person_id', 'ad58b8bd-033f-48ee-8f3b-a84f9c24e7de' as UUID). property('name', 'Emeril LAGASSE'). property('gender','M'). iterate(); g.addV('person'). property('person_id', '4ce9caf1-25b8-468e-a983-69bad20c017a' as UUID). property('name', 'James BEARD'). property('gender','M'). property('nickname', ['Jim', 'Jimmy'] as Set). iterate(); // END-insertAllPersons // START-AllPersonReviewers // reviewer vertices g.addV('person'). property('person_id', '46ad98ac-f5c9-4411-815a-f81b3b667921' as UUID). property('name', 'John DOE'). property('gender','M'). property('cal_goal', 1750). property('macro_goal', [10,30,60]). property('badge', ['silver':'2016-01-01' as LocalDate, 'gold':'2017-01-01' as LocalDate]). iterate(); g.addV('person'). property('person_id', '4954d71d-f78c-4a6d-9c4a-f40903edbf3c' as UUID). property('name', 'John SMITH'). property('gender','M'). property('nickname', ['Johnie'] as Set). property('cal_goal', 1800). property('macro_goal', [30,20,50]). iterate(); g.addV('person'). property('person_id', '6c09f656-5aef-46df-97f9-e7f984c9a3d9' as UUID). property('name', 'Jane DOE'). property('gender','F'). property('nickname', ['Janie'] as Set). property('cal_goal', 1500). property('macro_goal', [50,15,35]). iterate(); g.addV('person'). property('person_id', 'daa02698-df4f-4436-8855-941774f4c3e0' as UUID). property('name', 'Sharon SMITH'). property('gender','F'). property('cal_goal', 1600). property('macro_goal', [30,20,50]). iterate(); g.addV('person'). property('person_id', '6bda1b37-fe96-42bd-a2db-682073d10c37' as UUID). property('name', 'Betsy JONES'). property('gender','F'). property('cal_goal', 1700). property('macro_goal', [10,50,30]). iterate(); // END-AllPersonReviewers // START-insertAllBook // book vertices g.addV('book'). property('book_id',1001). property('name','The Art of French Cooking, Vol. 1'). property('publish_year',1961). property('category', ['French', 'general', 'cooking'] as Set). iterate(); g.addV('book'). property('book_id', 1002). property('name',"Simca's Cuisine: 100 Classic French Recipes for Every Occasion"). property('publish_year', 1972). property('isbn', '0-394-40152-2'). property('category', ['French', 'cooking'] as Set). iterate(); g.addV('book'). property('book_id', 1003). property('name','The French Chef Cookbook'). property('publish_year', 1968). property('isbn', '0-394-40135-2'). property('category', ['French', 'cooking'] as Set). property('book_discount', '10%'). iterate(); g.addV('book'). property('book_id', 1004). property('name', 'The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution'). property('publish_year', 2007). property('isbn', '0-307-33679-4'). property('category', ['American', 'cooking', 'simple'] as Set). iterate(); // END-insertAllBook //START-insertAllRecipe // recipe vertices g.addV('recipe'). property('recipe_id', 2001). property('name', 'Beef Bourguignon'). property('cuisine', ['French', 'entree', 'beef'] as Set). property('instructions', 'Braise the beef. Saute the onions and carrots. Add wine and cook in a dutch oven at 425 degrees for 1 hour.'). property('notes', 'Takes a long time to make.'). iterate(); g.addV('recipe'). property('recipe_id', 2002). property('name', 'Rataouille'). property('instructions', 'Peel and cut the egglant. Make sure you cut eggplant into lengthwise slices that are about 1-inch wmyIde, 3-inches long, and 3/8-inch thick'). property('notes', "I've made this 13 times."). iterate(); g.addV('recipe'). property('recipe_id', 2003). property('name', 'Salade Nicoise'). property('instructions', 'Take a salad bowl or platter and line it with lettuce leaves, shortly before serving. Drizzle some olive oil on the leaves and dust them with salt.'). property('notes', ''). iterate(); g.addV('recipe'). property('recipe_id', 2004). property('name', 'Wild Mushroom Stroganoff'). property('instructions', 'Cook the egg noodles according to the package directions and keep warm. Heat 1 1/2 tablespoons of the oliveoil in a large saute pan over medium-high heat.'). property('notes', 'Good for Jan and Bill.'). iterate(); g.addV('recipe'). property('recipe_id', 2005). property('name', 'Spicy Meatloaf'). property('instructions', 'Preheat the oven to 375 degrees F. Cook bacon in a large skillet over medium heat until very crisp and fat has rendered, 8-10 minutes.'). property('notes', ' '). iterate(); g.addV('recipe'). property('recipe_id', 2006) . property('name', 'Oysters Rockefeller'). property('instructions', 'Saute the shallots, celery, herbs, and seasonings in 3 tablespoons of the butter for 3 minutes. Add the watercress and let it wilt.'). property('notes', ' '). iterate(); g.addV('recipe'). property('recipe_id', 2007). property('name', 'Carrot Soup') . property('instructions', 'In a heavy-bottomed pot, melt the butter. When it starts to foam, add the onions and thyme and cook over medium-low heat until tender, about 10 minutes.'). property('notes', 'Quick and easy.'). iterate(); g.addV('recipe'). property('recipe_id', 2008). property('name', 'Roast Pork Loin'). property('instructions', 'The day before, separate the meat from the ribs, stopping about 1 inch before the end of the bones. Season the pork liberally inside and out with salt and pepper and refrigerate overnight.'). property('notes', 'Love this one!'). iterate(); //END-insertAllRecipe // START-insertAllIngred // ingredients vertices g.addV('ingredient'). property('ingred_id', 3001). property('name', 'beef'). iterate(); g.addV('ingredient'). property('ingred_id', 3002). property('name', 'onion'). iterate(); g.addV('ingredient'). property('ingred_id', 3003). property('name', 'mashed garlic'). iterate(); g.addV('ingredient'). property('ingred_id', 3004). property('name', 'butter'). iterate(); g.addV('ingredient'). property('ingred_id', 3005). property('name', 'tomato paste'). iterate(); g.addV('ingredient'). property('ingred_id', 3006). property('name', 'eggplant'). iterate(); g.addV('ingredient'). property('ingred_id', 3007). property('name', 'zucchini'). iterate(); g.addV('ingredient'). property('ingred_id', 3008). property('name', 'olive oil'). iterate(); g.addV('ingredient'). property('ingred_id', 3009). property('name', 'yellow onion'). iterate(); g.addV('ingredient'). property('ingred_id', 3010). property('name', 'green beans'). iterate(); g.addV('ingredient'). property('ingred_id', 3011). property('name', 'tuna'). iterate(); g.addV('ingredient'). property('ingred_id', 3012). property('name', 'tomato'). iterate(); g.addV('ingredient'). property('ingred_id', 3013). property('name', 'hard-boiled egg'). iterate(); g.addV('ingredient'). property('ingred_id', 3014). property('name', 'egg noodles'). iterate(); g.addV('ingredient'). property('ingred_id', 3015). property('name', 'mushrooms'). iterate(); g.addV('ingredient'). property('ingred_id', 3016). property('name', 'bacon'). iterate(); g.addV('ingredient'). property('ingred_id', 3017). property('name', 'celery'). iterate(); g.addV('ingredient'). property('ingred_id', 3018). property('name', 'green bell pepper'). iterate(); g.addV('ingredient'). property('ingred_id', 3019). property('name', 'ground beef'). iterate(); g.addV('ingredient'). property('ingred_id', 3020). property('name', 'pork sausage'). iterate(); g.addV('ingredient'). property('ingred_id', 3021). property('name', 'shallots'). iterate(); g.addV('ingredient'). property('ingred_id', 3022). property('name', 'chervil'). iterate(); g.addV('ingredient'). property('ingred_id', 3023). property('name', 'fennel'). iterate(); g.addV('ingredient'). property('ingred_id', 3024). property('name', 'parsley'). iterate(); g.addV('ingredient'). property('ingred_id', 3025). property('name', 'oyster'). iterate(); g.addV('ingredient'). property('ingred_id', 3026). property('name', 'Pernod'). iterate(); g.addV('ingredient'). property('ingred_id', 3027). property('name', 'thyme'). iterate(); g.addV('ingredient'). property('ingred_id', 3028). property('name', 'carrots'). iterate(); g.addV('ingredient'). property('ingred_id', 3029). property('name', 'chicken broth'). iterate(); g.addV('ingredient'). property('ingred_id', 3030). property('name', 'pork loin'). iterate(); g.addV('ingredient'). property('ingred_id', 3031). property('name', 'red wine'). iterate(); // END-insertAllIngred // START-insertAllMeals // Insert meal vertices g.addV('meal'). property('meal_id', 4001). property('type', 'lunch'). iterate(); g.addV('meal'). property('meal_id', 4002). property('type', 'lunch'). iterate(); g.addV('meal'). property('meal_id', 4003). property('type', 'lunch'). iterate(); g.addV('meal'). property('meal_id', 4004). property('type', 'lunch'). iterate(); g.addV('meal'). property('meal_id', 4005). property('type', 'breakfast'). iterate(); g.addV('meal'). property('meal_id', 4006). property('type', 'snack'). iterate(); g.addV('meal'). property('meal_id', 4007). property('type', 'dinner'). iterate(); g.addV('meal'). property('meal_id', 4008). property('type', 'dinner'). iterate(); // END-insertAllMeals // START-insertAllMealitems // meal_items g.addV('meal_item'). property('item_id',5001). property('name','taco'). property('serv_amt', '1'). property('macro',[15,65,65]). property('calories',650). iterate(); g.addV('meal_item'). property('item_id',5002). property('name','burrito'). property('serv_amt', '1'). property('macro',[15,65,65]). property('calories',1230). iterate(); g.addV('meal_item'). property('item_id',5003). property('name','iced tea'). property('serv_amt', '2 cups'). property('macro',[0,0,0]). property('calories',0). iterate(); // END-insertAllMealitems // START-insertAllFridge_sensor // fridge_sensor vertices g.addV('fridge_sensor'). property('state_id', 31). property('city_id', 100). property('zipcode_id', 55555). property('sensor_id', 001). iterate(); g.addV('fridge_sensor'). property('state_id', 31). property('city_id', 100). property('zipcode_id', 55555). property('sensor_id', 002). iterate(); g.addV('fridge_sensor'). property('state_id', 31). property('city_id', 100). property('zipcode_id', 55555). property('sensor_id', 003). iterate(); g.addV('fridge_sensor'). property('state_id', 31). property('city_id', 200). property('zipcode_id', 55556). property('sensor_id', 001). iterate(); g.addV('fridge_sensor'). property('state_id', 31). property('city_id', 200). property('zipcode_id', 55556). property('sensor_id', 002). iterate(); g.addV('fridge_sensor'). property('state_id', 31). property('city_id', 200). property('zipcode_id', 55556). property('sensor_id', 003). iterate(); g.addV('fridge_sensor'). property('state_id', 45). property('city_id', 300). property('zipcode_id', 66665). property('sensor_id', 001). iterate(); g.addV('fridge_sensor'). property('state_id', 45). property('city_id', 300). property('zipcode_id', 66665). property('sensor_id', 002). iterate(); g.addV('fridge_sensor'). property('state_id', 45). property('city_id', 300). property('zipcode_id', 66665). property('sensor_id', 003). iterate(); // END-insertAllFridge_sensor // START-insertAllLocation // Insert location data g.addV('location'). property('loc_id', 'g1'). property('name', 'Paris'). property('geo_point', 'POINT (2.352222 48.856614)' as Point). iterate(); g.addV('location'). property('loc_id', 'g2'). property('name', 'London'). property('geo_point', 'POINT (-0.127758 51.507351)' as Point). iterate(); g.addV('location'). property('loc_id', 'g3'). property('name', 'Dublin'). property('geo_point', 'POINT (-6.26031 53.349805)' as Point). iterate(); g.addV('location'). property('loc_id', 'g4'). property('name', 'Aachen'). property('geo_point', 'POINT (6.083887 50.775346)' as Point). iterate(); g.addV('location'). property('loc_id', 'g5'). property('name', 'Tokyo'). property('geo_point', 'POINT (139.691706 35.689487)' as Point). iterate(); g.addV('location'). property('loc_id', 'g5'). property('name', 'Tokyo'). property('geo_point', 'POINT (139.691706 35.689487)' as Point). iterate(); g.addV('location'). property('loc_id', 'g6'). property('name', 'New York'). property('geo_point', 'POINT (74.0059 40.7128)' as Point). iterate(); g.addV('location'). property('loc_id', 'g7'). property('name', 'New Orleans'). property('geo_point', 'POINT (90.0715 29.9511)' as Point). iterate(); g.addV('location'). property('loc_id', 'g8'). property('name', 'Los Angeles'). property('geo_point', 'POINT (118.2437 34.0522)' as Point). iterate(); g.addV('location'). property('loc_id', 'g9'). property('name', 'Chicago'). property('geo_point', 'POINT (-87.6298 41.8781136)' as Point). iterate(); g.addV('location'). property('loc_id', 'g10'). property('name', "Jane's house"). property('geo_point', 'POINT (118.5 34.0000)' as Point). iterate(); g.addV('location'). property('loc_id', 'g11'). property('name', "John Smith's place"). property('geo_point', 'POINT (90.0000 30.000)' as Point). iterate(); g.addV('location'). property('loc_id', 'g12'). property('name', "Mary's house"). property('loc_details', [ loc_address: [address1:'215 1st St', city_code:'Winston', state_code:'CA', zip_code:'93002'] as address, telephone: ['530-555-1255', '916-442-2211'] ] as location_details). property('geo_point', 'POINT(-106.372802 35.107546)' as Point). iterate(); g.addV('location'). property('loc_id', 'g13'). property('name', 'Zippy Mart'). property('loc_details', [ loc_address: [address1:'213 F St', city_code:'Winston', state_code:'CA', zip_code:'93001'] as address, telephone: ['530-555-3455', '916-446-2211'] ] as location_details). property('geo_point', 'POINT(-112.347309 34.622238)' as Point). iterate(); g.addV('location'). property('loc_id', 'g14'). property('name', 'Quik Station'). property('loc_details', [ loc_address: [address1:'500 C St', city_code:'Winston', state_code:'CA', zip_code:'93001'] as address, telephone: ['530-555-3454', '916-446-1111'] ] as location_details). property('geo_point', 'POINT(-74.575156 39.339838)' as Point). iterate(); g.addV('location'). property('loc_id', 'g15'). property('name', "Mamma's Grocery"). property('loc_details', [ loc_address: [address1:'1000 A St', city_code:'Winston', state_code:'CA', zip_code:'93001'] as address, telephone: ['530-555-1212', '916-444-3454'] ] as location_details). property('geo_point', 'POINT(-74.423251 42.323255)' as Point). iterate(); g.addV('location'). property('loc_id', 'g100'). property('name', 'test location'). property('loc_details', [ loc_address: [address1:'757 Jay St', city_code:'Arbuckle', state_code:'CA', zip_code:'95691'] as address, telephone: ['530-555-1212', '916-4444-3454'] ] as location_details). property('geo_point', 'POINT (1.352222 48.856614)' as Point). iterate(); // END-insertAllLocation // START-insertAllHome // Insert home data g.addV('home'). property('home_id', 9000). property('name', "Jane's house"). iterate(); g.addV('home'). property('home_id', 9001). property('name', "John Smith's place"). iterate(); g.addV('home'). property('home_id', 9002). property('name', "Mary's house"). iterate(); // END-insertAllHome //START-insertAllStore // Insert all store vertices g.addV('store'). property('store_id', 8001). property('name', 'Zippy Mart'). iterate(); g.addV('store'). property('store_id', 8002). property('name', 'Quik Station'). iterate(); g.addV('store'). property('store_id', 8003). property('name', "Mamma's Grocery"). iterate(); //END-insertAllStore -
Load the edges. Studio does have a limitation on the number of commands executed in each cell due to serialization to bytecode. To accommodate that limitation, load the following edges in batches in separate cells. Gremlin console does not have the same limitation, so load all edges as shown.
// START-AllFridgeSensorContainsIngred // fridge_sensor contains ingredient edges g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 001).as('a'). V().has('ingredient', 'ingred_id', 3016).as('b'). addE('contains'). property('expire_date', '2017-10-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 001).as('a'). V().has('ingredient', 'ingred_id', 3001).as('b'). addE('contains'). property('expire_date', '2017-10-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 001).as('a'). V().has('ingredient', 'ingred_id', 3020).as('b'). addE('contains'). property('expire_date', '2017-08-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 001).as('a'). V().has('ingredient', 'ingred_id', 3015).as('b'). addE('contains'). property('expire_date', '2017-09-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 001).as('a'). V().has('ingredient', 'ingred_id', 3007).as('b'). addE('contains'). property('expire_date', '2017-07-20' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('ingredient', 'ingred_id', 3016).as('b'). addE('contains'). property('expire_date', '2017-11-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('ingredient', 'ingred_id', 3005).as('b'). addE('contains'). property('expire_date', '2017-08-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('ingredient', 'ingred_id', 3015).as('b'). addE('contains'). property('expire_date', '2017-09-03' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 001).as('a'). V().has('ingredient', 'ingred_id', 3005).as('b'). addE('contains'). property('expire_date', '2017-09-03' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('ingredient', 'ingred_id', 3010).as('b'). addE('contains'). property('expire_date', '2017-07-15' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('ingredient', 'ingred_id', 3015).as('b'). addE('contains'). property('expire_date', '2018-01-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('ingredient', 'ingred_id', 3008).as('b'). addE('contains'). property('expire_date', '2017-07-12' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('ingredient', 'ingred_id', 3015).as('b'). addE('contains'). property('expire_date', '2017-09-03' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 002).as('a'). V().has('ingredient', 'ingred_id', 3016).as('b'). addE('contains'). property('expire_date', '2017-09-09' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 002).as('a'). V().has('ingredient', 'ingred_id', 3001).as('b'). addE('contains'). property('expire_date', '2017-07-17' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 002).as('a'). V().has('ingredient', 'ingred_id', 3002).as('b'). addE('contains'). property('expire_date', '2017-07-18' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 002).as('a'). V().has('ingredient', 'ingred_id', 3003).as('b'). addE('contains'). property('expire_date', '2017-11-11' as LocalDate). from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 002).as('a'). V().has('ingredient', 'ingred_id', 3004).as('b'). addE('contains'). property('expire_date', '2017-09-08' as LocalDate). from('a').to('b'). iterate(); // END-AllFridgeSensorContainsIngred // START-AllFridgeSensorLocatedAtHome // home is_located_at fridge_sensor edges g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 001).as('a'). V().has('home', 'home_id', 9001).as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 004).as('a'). V().has('home', 'home_id', 9001).as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 002).as('a'). V().has('home', 'home_id', 9002).as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 100). has('fridge_sensor', 'zipcode_id', 55555). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('home', 'home_id', 9003).as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55556). has('fridge_sensor', 'sensor_id', 001).as('a'). V().has('home', 'home_id', 9002).as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55556). has('fridge_sensor', 'sensor_id', 002).as('a'). V().has('home', 'home_id', 9003).as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('fridge_sensor', 'state_id', 31). has('fridge_sensor', 'city_id', 200). has('fridge_sensor', 'zipcode_id', 55556). has('fridge_sensor', 'sensor_id', 003).as('a'). V().has('home', 'home_id', 9001).as('b'). addE('is_located_at').from('a').to('b'). iterate(); // END-AllFridgeSensorLocatedAtHome // START-AllHomeLocatedAtLocation // home located_at location edges g.V().has('home', 'home_id', 9001).as('a'). V().has('location', 'loc_id', 'g10').as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('home', 'home_id', 9002).as('a'). V().has('location', 'loc_id', 'g11').as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('home', 'home_id', 9003).as('a'). V().has('location', 'loc_id', 'g12').as('b'). addE('is_located_at').from('a').to('b'). iterate(); // END-AllHomeLocatedAtLocation // START-AllMealIncludesMealItem // meal includes meal_item edges g.V().has('meal', 'meal_id', 4001). has('meal', 'type', 'lunch').as('a'). V().has('meal_item', 'meal_item_id', 5001).as('b'). addE('includes').property('num_serv', 1).from('a').to('b'). iterate(); g.V().has('meal', 'meal_id', 4001).has('meal', 'type', 'lunch').as('a'). V().has('meal_item', 'meal_item_id', 5002).as('b'). addE('includes').property('num_serv', 1).from('a').to('b'). iterate(); g.V().has('meal', 'meal_id', 4001).has('meal', 'type', 'lunch').as('a'). V().has('meal_item', 'meal_item_id', 5003).as('b'). addE('includes').property('num_serv', 2).from('a').to('b'). iterate(); g.V().has('meal', 'meal_id', 4002).has('meal', 'type', 'lunch').as('a'). V().has('meal_item', 'meal_item_id', 5001).as('b'). addE('includes').property('num_serv', 2).from('a').to('b'). iterate(); // END-AllMealIncludesMealItem // START-AllPersonAteMeal // person ate meal edges g.V().has('person', 'person_id', '46ad98ac-f5c9-4411-815a-f81b3b667921' as UUID).as('a'). V().has('type', 'lunch').has('meal', 'meal_id', 4001).as('b'). addE('ate').property('meal_date', '2019-08-20' as LocalDate).from('a').to('b') g.V().has('person', 'person_id', '46ad98ac-f5c9-4411-815a-f81b3b667921' as UUID).as('a'). V().has('type', 'lunch').has('meal', 'meal_id', 4002).as('b'). addE('ate').property('meal_date', '2019-08-20' as LocalDate).from('a').to('b') g.V().has('person', 'person_id', '6c09f656-5aef-46df-97f9-e7f984c9a3d9' as UUID).as('a'). V().has('type', 'lunch').has('meal', 'meal_id', 4003).as('b'). addE('ate').property('meal_date', '2019-08-20' as LocalDate).from('a').to('b') g.V().has('person', 'person_id', '6c09f656-5aef-46df-97f9-e7f984c9a3d9' as UUID).as('a'). V().has('type', 'lunch').has('meal', 'meal_id', 4004).as('b'). addE('ate').property('meal_date', '2019-08-21' as LocalDate).from('a').to('b') // END-AllPersonAteMeal // START-eatOneMeal g.V().has('person', 'person_id', '6c09f656-5aef-46df-97f9-e7f984c9a3d9' as UUID).as('a'). V().has('type', 'lunch').has('meal', 'meal_id', 4004).as('b'). addE('ate').property('meal_date', '2019-08-21' as LocalDate).from('a').to('b') // END-eatOneMeal // START-AllPersonAuthoredBook // person to book edges g.V().has('person', 'person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID).as('a'). V().has('book', 'book_id', 1001).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', 'adb8744c-d015-4d78-918a-d7f062c59e8f' as UUID).as('a'). V().has('book', 'book_id', 1001).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', 'f092107c-0c5c-47e7-917c-c82c7fc2a249' as UUID).as('a'). V().has('book', 'book_id', 1001).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', 'adb8744c-d015-4d78-918a-d7f062c59e8f' as UUID).as('a'). V().has('book', 'book_id', 1002).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', 'ef811281-f954-4fd6-ace0-bf67d057771a' as UUID).as('a'). V().has('book', 'book_id', 1002).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID).as('a'). V().has('book', 'book_id', 1003).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', 'd45c76bc-6f93-4d0e-9d9f-33298dae0524' as UUID).as('a'). V().has('book', 'book_id', 1004).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', '7f969e16-b81e-4fcd-87c5-1911abbed132' as UUID).as('a'). V().has('book', 'book_id', 1004).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', '01e22ca6-da10-4cf7-8903-9b7e30c25805' as UUID).as('a'). V().has('book', 'book_id', 1004).as('b'). addE('authored').from('a').to('b'). iterate(); g.V().has('person', 'person_id', '888ad970-0efc-4e2c-b234-b6a71c30efb5' as UUID).as('a'). V().has('book', 'book_id', 1004).as('b'). addE('authored').from('a').to('b'). iterate(); // END-AllPersonAuthoredBook // START-AllPersonCreatedRecipe // person to recipe edges g.V().has('person', 'person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID).as('a'). V().has('recipe', 'recipe_id', 2001).as('b'). addE('created').property('create_date', '1961-01-01' as LocalDate).from('a').to('b'). iterate() g.V().has('person', 'person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID).as('a'). V().has('recipe', 'recipe_id', 2001).as('b'). addE('created').property('create_date', '1961-01-01' as LocalDate).from('a').to('b'). iterate() g.V().has('person', 'person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID).as('a'). V().has('recipe', 'recipe_id', 2002).as('b'). addE('created').property('create_date', '1965-02-02' as LocalDate).from('a').to('b'). iterate() g.V().has('person', 'person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID).as('a'). V().has('recipe', 'recipe_id', 2003).as('b'). addE('created').property('create_date', '1962-03-03' as LocalDate).from('a').to('b'). iterate() g.V().has('person', 'person_id', 'ad58b8bd-033f-48ee-8f3b-a84f9c24e7de' as UUID).as('a'). V().has('recipe', 'recipe_id', 2004).as('b'). addE('created').property('create_date', '2003-04-04' as LocalDate).from('a').to('b'). iterate() g.V().has('person', 'person_id', 'ad58b8bd-033f-48ee-8f3b-a84f9c24e7de' as UUID).as('a'). V().has('recipe', 'recipe_id', 2005).as('b'). addE('created').property('create_date', '2000-05-05' as LocalDate).from('a').to('b'). iterate() g.V().has('person', 'person_id', 'd45c76bc-6f93-4d0e-9d9f-33298dae0524' as UUID).as('a'). V().has('recipe', 'recipe_id', 2007).as('b'). addE('created').property('create_date', '1995-06-06' as LocalDate).from('a').to('b'). iterate() g.V().has('person', 'person_id', 'd45c76bc-6f93-4d0e-9d9f-33298dae0524' as UUID).as('a'). V().has('recipe', 'recipe_id', 2008).as('b'). addE('created').property('create_date', '1996-07-07' as LocalDate).from('a').to('b'). iterate() g.V().has('person', 'person_id', '4ce9caf1-25b8-468e-a983-69bad20c017a' as UUID).as('a'). V().has('recipe', 'recipe_id', 2006).as('b'). addE('created').property('create_date', '1970-01-01' as LocalDate).from('a').to('b'). iterate() // START-AllPersonCreatedRecipe // START-AllPersonKnowsPerson // person knows person edges g.V().has('person', 'person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID).as('a'). V().has('person', 'person_id', 'adb8744c-d015-4d78-918a-d7f062c59e8f' as UUID).as('b'). addE('knows').from('a').to('b'). iterate(); g.V().has('person', 'person_id', 'adb8744c-d015-4d78-918a-d7f062c59e8f' as UUID).as('a') V().has('person', 'person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID).as('b') addE('knows').from('a').to('b'). iterate(); // END-AllPersonKnowsPerson // START-AllPersonReviewedRecipe // person_reviewed_recipe g.V().has('person', 'person_id', '46ad98ac-f5c9-4411-815a-f81b3b667921' as UUID).as('a'). V().has('recipe', 'recipe_id', 2001).as('b'). addE('reviewed'). property('time', '12:00:00' as LocalTime). property('year', '2014-01-01' as LocalDate). property('stars', 5). property('comment', 'Pretty tasty!'). from('a').to('b'). iterate() g.V().has('person', 'person_id', '4954d71d-f78c-4a6d-9c4a-f40903edbf3c' as UUID).as('a'). V().has('recipe', 'recipe_id', 2001).as('b'). addE('reviewed'). property('time', '12:00:00' as LocalTime). property('year', '2014-01-23' as LocalDate). property('stars', 4). from('a').to('b'). iterate() g.V().has('person', 'person_id', '6c09f656-5aef-46df-97f9-e7f984c9a3d9' as UUID).as('a'). V().has('recipe', 'recipe_id', 2001).as('b'). addE('reviewed'). property('time', '12:00:00' as LocalTime). property('year', '2014-02-01' as LocalDate). property('stars', 5). property('comment', 'Yummy!'). from('a').to('b'). iterate() g.V().has('person', 'person_id', 'daa02698-df4f-4436-8855-941774f4c3e0' as UUID).as('a'). V().has('recipe', 'recipe_id', 2001).as('b'). addE('reviewed'). property('time', '12:00:00' as LocalTime). property('year', '2015-12-31' as LocalDate). property('stars', 3). property('comment', 'It was okay.'). from('a').to('b'). iterate() g.V().has('person', 'person_id', '46ad98ac-f5c9-4411-815a-f81b3b667921' as UUID).as('a'). V().has('recipe', 'recipe_id', 2005).as('b'). addE('reviewed'). property('time', '12:00:00' as LocalTime). property('year', '2015-12-31' as LocalDate). property('stars', 4). property('comment', 'Really spicy - be careful!'). from('a').to('b'). iterate() g.V().has('person', 'person_id', 'daa02698-df4f-4436-8855-941774f4c3e0' as UUID).as('a'). V().has('recipe', 'recipe_id', 2005).as('b'). addE('reviewed'). property('time', '12:00:00' as LocalTime). property('year', '2014-07-23' as LocalDate). property('stars', 3). property('comment', 'Too spicy for me. Use less garlic.'). from('a').to('b'). iterate() g.V().has('person', 'person_id', '6c09f656-5aef-46df-97f9-e7f984c9a3d9' as UUID).as('a'). V().has('recipe', 'recipe_id', 2007).as('b'). addE('reviewed'). property('time', '12:00:00' as LocalTime). property('year', '2015-12-30' as LocalDate). property('stars', 5). property('comment', 'Loved this soup! Yummy vegetarian!'). from('a').to('b'). iterate() // END-AllPersonReviewedRecipe // START-insertAllRecipeIncludedInBook // book to recipe edges g.V().has('recipe', 'recipe_id', 2001).as('a'). V().has('book', 'book_id', 1001).as('b'). addE('included_in').from('a').to('b'). iterate() g.V().has('recipe', 'recipe_id', 2003).as('a'). V().has('book', 'book_id', 1001).as('b'). addE('included_in').from('a').to('b'). iterate() g.V().has('recipe', 'recipe_id', 2007).as('a'). V().has('book', 'book_id', 1004).as('b'). addE('included_in').from('a').to('b'). iterate() // END-insertAllRecipeIncludedInBook // meal to recipe edges // The with('allow-filtering') is a shortcut to add the data without an index, but to make queries on these edges, and index will be required. // START-insertAllRecipeIncludedInMeal g.with('allow-filtering').V().has('recipe', 'recipe_id', 2001).as('a'). V().has('meal', 'meal_id', 4001).as('b'). addE('included_in').from('a').to('b'). iterate() g.with('allow-filtering').V().has('recipe', 'recipe_id', 2003).as('a'). V().has('meal', 'meal_id', 4001).as('b'). addE('included_in').from('a').to('b'). iterate() g.with('allow-filtering').V().has('recipe', 'recipe_id', 2007).as('a'). V().has('meal', 'meal_id', 4004).as('b'). addE('included_in').from('a').to('b'). iterate() g.with('allow-filtering').V().has('recipe', 'recipe_id', 2008).as('a'). V().has('meal', 'meal_id', 4004).as('b'). addE('included_in').from('a').to('b'). iterate() // END-insertAllRecipeIncludedInMeal // START-insertAllRecipeIncludesIngred // recipe to ingredient edges g.V().has('recipe', 'recipe_id', 2001).as('a'). V().has('ingredient', 'ingred_id', 3001).as('b'). addE('includes').property('amount', '2 lbs').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2001).as('a'). V().has('ingredient', 'ingred_id', 3002).as('b'). addE('includes').property('amount', '1 sliced').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2001).as('a'). V().has('ingredient', 'ingred_id', 3003).as('b'). addE('includes').property('amount', '2 cloves').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2001).as('a'). V().has('ingredient', 'ingred_id', 3004).as('b'). addE('includes').property('amount', '3.5 Tbsp').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2001).as('a'). V().has('ingredient', 'ingred_id', 3005).as('b'). addE('includes').property('amount', '1 Tbsp').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2002).as('a'). V().has('ingredient', 'ingred_id', 3006).as('b'). addE('includes').property('amount', '1 lb').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2002).as('a'). V().has('ingredient', 'ingred_id', 3007).as('b'). addE('includes').property('amount', '1 lb').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2002).as('a'). V().has('ingredient', 'ingred_id', 3003).as('b'). addE('includes').property('amount', '2 cloves').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2002).as('a'). V().has('ingredient', 'ingred_id', 3008).as('b'). addE('includes').property('amount', '4-6 Tbsp').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2002).as('a'). V().has('ingredient', 'ingred_id', 3009).as('b'). addE('includes').property('amount', '1 1/2 cups or 1/2 lb thinly sliced').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2003).as('a'). V().has('ingredient', 'ingred_id', 3008).as('b'). addE('includes').property('amount', '2-3 Tbsp').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2003).as('a'). V().has('ingredient', 'ingred_id', 3010).as('b'). addE('includes').property('amount', '1 1/2 lbs blanched, trimmed').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2003).as('a'). V().has('ingredient', 'ingred_id', 3011).as('b'). addE('includes').property('amount', '8-10 ozs oil-packed, drained and flaked').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2003).as('a'). V().has('ingredient', 'ingred_id', 3012).as('b'). addE('includes').property('amount', '3 or 4 red, peeled, quartered, cored, and seasoned').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2003).as('a'). V().has('ingredient', 'ingred_id', 3013).as('b'). addE('includes').property('amount', '8 halved lengthwise').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2004).as('a'). V().has('ingredient', 'ingred_id', 3014).as('b'). addE('includes').property('amount', '16 ozs wide').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2004).as('a'). V().has('ingredient', 'ingred_id', 3015).as('b'). addE('includes').property('amount', '2 lbs wild or exotic, cleaned, stemmed, and sliced').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2004).as('a'). V().has('ingredient', 'ingred_id', 3009).as('b'). addE('includes').property('amount', '1 cup thinly sliced').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2005).as('a'). V().has('ingredient', 'ingred_id', 3016).as('b'). addE('includes').property('amount', '3 ozs diced').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2005).as('a'). V().has('ingredient', 'ingred_id', 3002).as('b'). addE('includes').property('amount', '2 cups finely chopped').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2005).as('a'). V().has('ingredient', 'ingred_id', 3017).as('b'). addE('includes').property('amount', '2 cups finely chopped').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2005).as('a'). V().has('ingredient', 'ingred_id', 3018).as('b'). addE('includes').property('amount', '1/4 cup finely chopped').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2005).as('a'). V().has('ingredient', 'ingred_id', 3020).as('b'). addE('includes').property('amount', '3/4 lbs hot').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2005).as('a'). V().has('ingredient', 'ingred_id', 3019).as('b'). addE('includes').property('amount', '1 1/2 lbs chuck').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2006).as('a'). V().has('ingredient', 'ingred_id', 3021).as('b'). addE('includes').property('amount', '1/4 cup chopped').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2006).as('a'). V().has('ingredient', 'ingred_id', 3017).as('b'). addE('includes').property('amount', '1/4 cup chopped').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2006).as('a'). V().has('ingredient', 'ingred_id', 3022).as('b'). addE('includes').property('amount', '1 tsp').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2006).as('a'). V().has('ingredient', 'ingred_id', 3023).as('b'). addE('includes').property('amount', '1/3 cup chopped').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2006).as('a'). V().has('ingredient', 'ingred_id', 3024).as('b'). addE('includes').property('amount', '1/3 cup chopped').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2006).as('a'). V().has('ingredient', 'ingred_id', 3025).as('b'). addE('includes').property('amount', '1 dozen on the half shell').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2006).as('a'). V().has('ingredient', 'ingred_id', 3026).as('b'). addE('includes').property('amount', '1/3 cup').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2007).as('a'). V().has('ingredient', 'ingred_id', 3004).as('b'). addE('includes').property('amount', '4 Tbsp').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2007).as('a'). V().has('ingredient', 'ingred_id', 3002).as('b'). addE('includes').property('amount', '2 medium sliced').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2007).as('a'). V().has('ingredient', 'ingred_id', 3027).as('b'). addE('includes').property('amount', '1 sprig').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2007).as('a'). V().has('ingredient', 'ingred_id', 3028).as('b'). addE('includes').property('amount', '2 1/2 lbs, peeled and sliced').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2007).as('a'). V().has('ingredient', 'ingred_id', 3029).as('b'). addE('includes').property('amount', '6 cups').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2008).as('a'). V().has('ingredient', 'ingred_id', 3030).as('b'). addE('includes').property('amount', '1 bone-in, 4-rib').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2008).as('a'). V().has('ingredient', 'ingred_id', 3031).as('b'). addE('includes').property('amount', '1/2 cup').from('a').to('b'). iterate(); g.V().has('recipe', 'recipe_id', 2008).as('a'). V().has('ingredient', 'ingred_id', 3029).as('b'). addE('includes').property('amount', '1 cup').from('a').to('b'). iterate(); // END-insertAllRecipeIncludesIngred // START-AllStoreStockedWithIngred // store is_stocked_with ingredient edges g.V().has('store', 'store_id', 8001).as('a'). V().has('ingredient', 'ingred_id', 3001).as('b'). addE('is_stocked_with'). property('expire_date', '2017-01-10' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8001).as('a'). V().has('ingredient', 'ingred_id', 3002).as('b'). addE('is_stocked_with'). property('expire_date', '2017-01-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8001).as('a'). V().has('ingredient', 'ingred_id', 3004).as('b'). addE('is_stocked_with'). property('expire_date', '2017-06-23' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8001).as('a'). V().has('ingredient', 'ingred_id', 3001).as('b'). addE('is_stocked_with'). property('expire_date', '2017-06-09' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8001).as('a'). V().has('ingredient', 'ingred_id', 3015).as('b'). addE('is_stocked_with'). property('expire_date', '2017-11-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8001).as('a'). V().has('ingredient', 'ingred_id', 3016).as('b'). addE('is_stocked_with'). property('expire_date', '2017-11-11' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8001).as('a'). V().has('ingredient', 'ingred_id', 3020).as('b'). addE('is_stocked_with'). property('expire_date', '2017-12-12' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('ingredient', 'ingred_id', 3003).as('b'). addE('is_stocked_with'). property('expire_date', '2017-12-12' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('ingredient', 'ingred_id', 3005).as('b'). addE('is_stocked_with'). property('expire_date', '2017-01-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('ingredient', 'ingred_id', 3007).as('b'). addE('is_stocked_with'). property('expire_date', '2017-05-03' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('ingredient', 'ingred_id', 3009).as('b'). addE('is_stocked_with'). property('expire_date', '2017-05-02' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('ingredient', 'ingred_id', 3011).as('b'). addE('is_stocked_with'). property('expire_date', '2017-02-03' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('ingredient', 'ingred_id', 3015).as('b'). addE('is_stocked_with'). property('expire_date', '2017-02-02' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('ingredient', 'ingred_id', 3016).as('b'). addE('is_stocked_with'). property('expire_date', '2017-10-17' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('ingredient', 'ingred_id', 3019).as('b'). addE('is_stocked_with'). property('expire_date', '2017-10-10' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8003).as('a'). V().has('ingredient', 'ingred_id', 3002).as('b'). addE('is_stocked_with'). property('expire_date', '2017-04-03' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8003).as('a'). V().has('ingredient', 'ingred_id', 3007).as('b'). addE('is_stocked_with'). property('expire_date', '2017-03-04' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8003).as('a'). V().has('ingredient', 'ingred_id', 3008).as('b'). addE('is_stocked_with'). property('expire_date', '2017-07-30' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8003).as('a'). V().has('ingredient', 'ingred_id', 3012).as('b'). addE('is_stocked_with'). property('expire_date', '2017-09-30' as LocalDate). from('a').to('b'). iterate(); // duplication?? g.V().has('store', 'store_id', 8003).as('a'). V().has('ingredient', 'ingred_id', 3008).as('b'). addE('is_stocked_with'). property('expire_date', '2017-02-02' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8003).as('a'). V().has('ingredient', 'ingred_id', 3006).as('b'). addE('is_stocked_with'). property('expire_date', '2017-01-01' as LocalDate). from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8003).as('a'). V().has('ingredient', 'ingred_id', 3004).as('b'). addE('is_stocked_with'). property('expire_date', '2017-04-25' as LocalDate). from('a').to('b'). iterate(); // END-AllStoreStockedWithIngred // START-AllStoreLocatedAtLocation // store is_located_at location edges g.V().has('store', 'store_id', 8001).as('a'). V().has('location', 'loc_id', 'g13').as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8002).as('a'). V().has('location', 'loc_id', 'g14').as('b'). addE('is_located_at').from('a').to('b'). iterate(); g.V().has('store', 'store_id', 8003).as('a'). V().has('location', 'loc_id', 'g15').as('b'). addE('is_located_at').from('a').to('b'). iterate(); // END-AllStoreLocatedAtLocation -
In Studio, run the following command to display all the data:
dev.with('label-warning', false).V()and additionally, if using Gremlin console, run the following command to see the edges:
dev.with('label-warning', false).E()Studio will display both vertices and edges when the vertices are queried.
In Gremlin console, run the following commands to view the results, similar to the sample shown here:
// A series of returns for vertices and edges will mark the successful completion gremlin> dev.V() ==>v[dseg:/person/4ce9caf1-25b8-468e-a983-69bad20c017a] ==>v[dseg:/person/888ad970-0efc-4e2c-b234-b6a71c30efb5] ==>v[dseg:/person/4954d71d-f78c-4a6d-9c4a-f40903edbf3c] ==>v[dseg:/person/01e22ca6-da10-4cf7-8903-9b7e30c25805] ==>v[dseg:/person/6c09f656-5aef-46df-97f9-e7f984c9a3d9] ==>v[dseg:/person/daa02698-df4f-4436-8855-941774f4c3e0] ==>v[dseg:/person/d45c76bc-6f93-4d0e-9d9f-33298dae0524] ==>v[dseg:/person/adb8744c-d015-4d78-918a-d7f062c59e8f] ==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd] ==>v[dseg:/person/f092107c-0c5c-47e7-917c-82c7fc2a2493] ==>v[dseg:/person/ad58b8bd-033f-48ee-8f3b-a84f9c24e7de] ==>v[dseg:/person/6bda1b37-fe96-42bd-a2db-682073d10c37] ==>v[dseg:/person/7f969e16-b81e-4fcd-87c5-1911abbed132] ==>v[dseg:/person/ef811281-f954-4fd6-ace0-bf67d057771a] ==>v[dseg:/person/46ad98ac-f5c9-4411-815a-f81b3b667921] ==>v[dseg:/book/1001] ==>v[dseg:/book/1002] gremlin> dev.E() ==>e[dseg:/person-authored-book/adb8744c-d015-4d78-918a-d7f062c59e8f/1001][dseg:/person/adb8744c-d015-4d78-918a-d7f062c59e8f-authored->dseg:/book/1001] ==>e[dseg:/person-authored-book/adb8744c-d015-4d78-918a-d7f062c59e8f/1002][dseg:/person/adb8744c-d015-4d78-918a-d7f062c59e8f-authored->dseg:/book/1002] ==>e[dseg:/person-authored-book/e7cd5752-bc0d-4157-a80f-7523add8dbcd/1001][dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd-authored->dseg:/book/1001] ==>e[dseg:/person-authored-book/ef811281-f954-4fd6-ace0-bf67d057771a/1002][dseg:/person/ef811281-f954-4fd6-ace0-bf67d057771a-authored->dseg:/book/1002] ==>e[dseg:/person-knows-person/e7cd5752-bc0d-4157-a80f-7523add8dbcd/adb8744c-d015-4d78-918a-d7f062c59e8f][dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd-knows->dseg:/person/adb8744c-d015-4d78-918a-d7f062c59e8f] -
If a vertex count is run, there is now a higher count of 100 vertices. Run the vertex count again:
g.V().count()
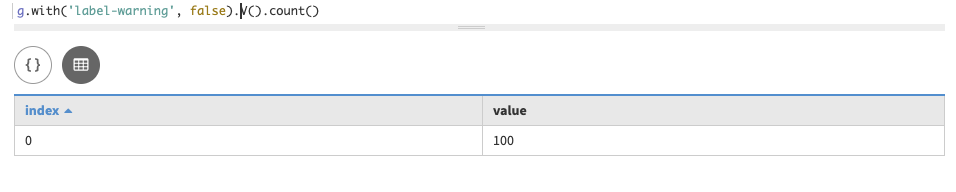
-
Similarly, the edge count can be run, to discover the higher edge count of 112:
g.E().count()
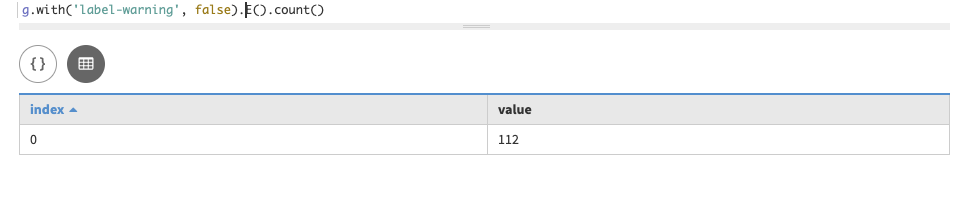
-
Adding more data using the DataStax Bulk Loader (optional)
-
You can load data with DataStax Bulk Loader, a standalone command-line tool, using CSV or JSON input files (see the next cell for CSV files that will be loaded). The following commands should be run from a terminal on a cluster node that has
dsbulkinstalled. -
Load data to
persontable from a CSV file with a pipe delimiter and allow missing field values:CSV data file located in data/vertices/person.csv containing:
person_id|name|gender|nickname|cal_goal|macro_goal|badge|country e7cd5752-bc0d-4157-a80f-7523add8dbcd|Julia CHILD|F|'Jay','Julia'||||[['USA', '1912-08-12', '1944-01-01'], ['Ceylon', '1944-01-01', '1945-06-01'], ['France', '1948-01-01', '1960-01-01'], ['USA','1960-01-01', '2004-08-13']] adb8744c-d015-4d78-918a-d7f062c59e8f|Simone BECK|F|'Simca','Simone'||||[['France', '1904-07-07', '1991-12-20']] 888ad970-0efc-4e2c-b234-b6a71c30efb5|Fritz STREIFF|M||||| f092107c-0c5c-47e7-917c-c82c7fc2a249|Louisette BERTHOLIE|F||||| ef811281-f954-4fd6-ace0-bf67d057771a|Patricia SIMON|F|'Pat'|||| d45c76bc-6f93-4d0e-9d9f-33298dae0524|Alice WATERS|F||||| 7f969e16-b81e-4fcd-87c5-1911abbed132|Patricia CURTAN|F|'Pattie'|||| 01e22ca6-da10-4cf7-8903-9b7e30c25805|Kelsie KERR|F||||| ad58b8bd-033f-48ee-8f3b-a84f9c24e7de|Emeril LAGASSE|M||||| 4ce9caf1-25b8-468e-a983-69bad20c017a|James BEARD|M|'Jim', 'Jimmy'|||| 65fd73f7-0e06-49af-abd6-0725dc64737d|John DOE|M|'Johnny'|1750|10,30,60|'silver':'2016-01-01', 'gold':'2017-02-01'| 3b3e89f4-5ca2-437e-b8e8-fe7c5e580068|John SMITH|M|'Johnnie'|1800|30,20,50|| 9b564212-9544-4f85-af36-57615e927f89|Jane DOE|F|'Janie'|1500|50,15,35|| ba6a6766-beae-4a35-965b-6f3878581702|Sharon SMITH|F||1600|30,20,50|| a3e7ab29-2ac9-4abf-9d4a-285bf2714a9f|Betsy JONES|F||1700|10,50,30||and run the dsbulk command:
dsbulk load --schema.keyspace food_qs --schema.table person -url data/vertices/person.csv -delim '|' --schema.allowMissingFields true -
Load data to
booktable from a CSV file with a pipe delimiter, allow missing field values, and identifying thefield->columnswith schema mapping:CSV data file located in data/vertices/book.csv containing:
book_id|name|publish_year|isbn 1001|The Art of French Cooking, Vol. 1|1961| 1002|Simca's Cuisine: 100 Classic French Recipes for Every Occasion|1972|0-394-40152-2 1003|The French Chef Cookbook|1968|0-394-40135-2 1004|The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution|2007|0-307-33679-4and run the dsbulk command:
dsbulk load -k food_qs -t book \ -url data/vertices/book.csv \ --schema.mapping '0=book_id, 1=name, 2=publish_year 3=isbn' \ -delim '|' \ --schema.allowMissingFields true -
Load data to
person_authored_booktable from a CSV file with a pipe delimiter, allow missing field values, and map CSV file positions to named columns in the table:CSV data file located in data/edges/person_authored_book.csv containing:
person_id|book_id bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca|1001 adb8744c-d015-4d78-918a-d7f062c59e8f|1001 f092107c-0c5c-47e7-917c-c82c7fc2a249|1001 adb8744c-d015-4d78-918a-d7f062c59e8f|1002 ef811281-f954-4fd6-ace0-bf67d057771a|1002 bb6d7af7-f674-4de7-8b4c-c0fdcdaa5cca|1003 d45c76bc-6f93-4d0e-9d9f-33298dae0524|1004 7f969e16-b81e-4fcd-87c5-1911abbed132|1004 01e22ca6-da10-4cf7-8903-9b7e30c25805|1004 888ad970-0efc-4e2c-b234-b6a71c30efb5|1004and run the dsbulk command:
dsbulk load -k food_qs -t person_authored_book \ -url data/edges/person\_authored\_book.csv \ -m '0=lastname, 1=person_id, 2=person_name, 3=book_id 4=book_name' \ -delim '|' \ --schema.allowMissingFields trueDataStax Bulk Loader is very versatile, and should be explored in its entirety.
QuickStart Exploring traversals
Explore graph data with query traversals.
About this task
Exploring the graph with graph traversals can lead to interesting conclusions. Here we’ll explore a number of traversals, to show off the power of Gremlin in creating simple queries.
|
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with |
Procedure
-
All queries can be profiled to see what the query path is and how the query performs. The
profile()step will display information abut the length of time each portion of the command takes to run, as well as the underlying CQL command that is run to complete the Gremlin command.g.V().has('person', 'name', 'Julia CHILD').profile()In Studio:
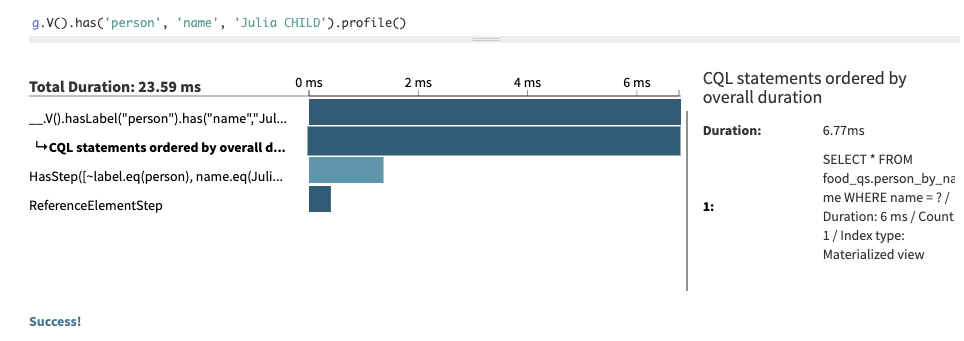
Clicking on the bars in the graph in Studio will show more detail about underlying CQL commands that Graph uses to execute a query.
In Gremlin console:
==>Traversal Metrics Step Count Traversers Time (ms) % Dur ============================================================================================================= __.V().has("name","Julia CHILD") 52.140 96.02 HasStep([name.eq(Julia CHILD)]) 1.987 3.66 ReferenceElementStep 0.174 0.32 >TOTAL - - 54.302 -In all the following queries, to investigate what happens, and why some queries are more efficient than others, try adding .profile() to any query will show you information similar to the information above.
-
Graph queries will have lower latency if the query is more specific, and uses the
has()step is for narrowing the search. Compare the following queries and their profiles (by adding.profile()to the end:dev.V().hasLabel('person')dev.V().hasLabel('person').has('name', 'Julia CHILD')dev.V().has('person','name', 'Julia CHILD')Running any of these queries in Studio will display the vertex id, label and all property values. In Gremlin console, these queries will only display the vertex id; the
elementMap()step must be appended to get the property values. -
In this next traversal,
has()filters vertex properties byname = Julia Childas seen above. The traversal stepoutE()discovers the outgoing edges from that vertex with theauthoredlabel.g.V().has('person','name','Julia CHILD').outE('authored')In Studio, either the listing of the Raw JSON view edge information:
In Gremlin console:
==>e[dseg:/person-authored-book/e7cd5752-bc0d-4157-a80f-7523add8dbcd/1001][dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd-authored->dseg:/book/1001] ==>e[dseg:/person-authored-book/e7cd5752-bc0d-4157-a80f-7523add8dbcd/1003][dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd-authored->dseg:/book/1003] -
If instead, you want to query for the books that all people have written, the query must be modified. The previous example retrieved edges, but not the adjacent book vertices. Add a traversal step
inV()to find all the vertices that connect to the outgoing edges, then print the book titles of those vertices. Notice how the chained traversal steps go from the vertices along outgoing edges to the adjacent vertices withV().outE().inV(). The outgoing edges are given a particular filter value, authored.g.V().outE('authored').inV().values('name')In Studio:
 and in Gremlin console:
and in Gremlin console:==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of French Cooking, Vol. 1 ==>The Art of French Cooking, Vol. 1 ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The French Chef Cookbook -
Notice that the book titles are duplicated in the resulting list, because a listing is returned for each author. If a book has three authors, three listings are returned. The traversal step
dedup()can eliminate the duplication.g.V().outE('authored').inV().values('name').dedup()In Studio:
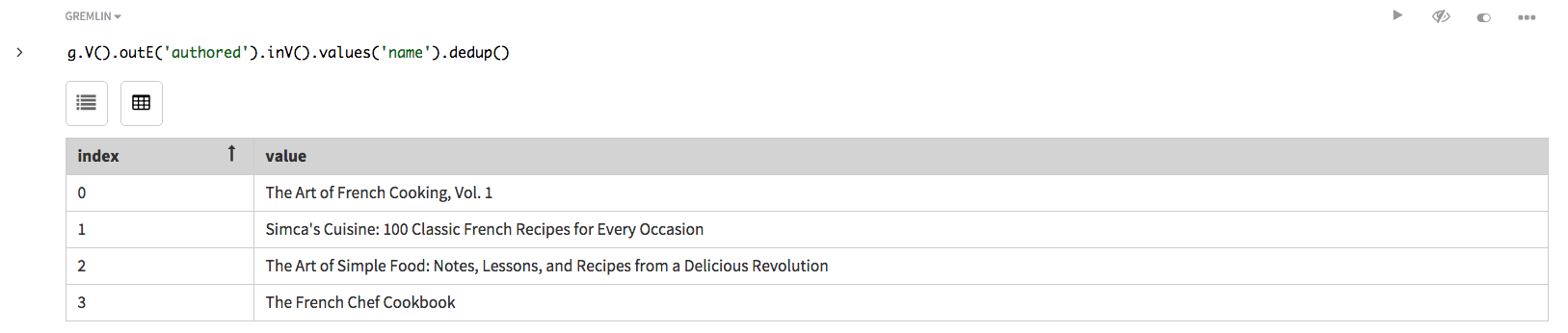 and in Gremlin console:
and in Gremlin console:==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of French Cooking, Vol. 1 ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The French Chef Cookbook -
Refine the traversal by reinserting the
has()step for a particular author. Find all the books authored by Julia Child.g.V().has('name','Julia CHILD').outE('authored').inV().values('name')In Studio:
 and in Gremlin console:
and in Gremlin console:==>The Art of French Cooking, Vol. 1 ==>The French Chef Cookbook -
The previous example and this example accomplish the same result. However, the number of traversal steps and the type of traversal steps can affect performance. The traversal step
outE()should be only used if the edges are explicitly required. In this example, the edges are traversed to get information about connected vertices, but the edge information is not important to the query.g.V().has('person', 'name','Julia CHILD').out('authored').values('name')In Studio:
 and in Gremlin console:
and in Gremlin console:==>The Art of French Cooking, Vol. 1 ==>The French Chef CookbookThe traversal step
out()retrieves the connected book vertices based on the edge labelauthoredwithout retrieving the edge information. In a larger graph traversal, this subtle difference in the traversal can become a latency issue. -
Additional traversal steps continue to fine-tune the results. Adding another chained
hastraversal step finds only books authored by Julia Child published after 1967. This example also displays the use of thegt, or greater than function.g.V().has('person', 'name','Julia CHILD').out('authored').has('publish_year', gt(1967)).values('name', 'publish_year')In Studio:
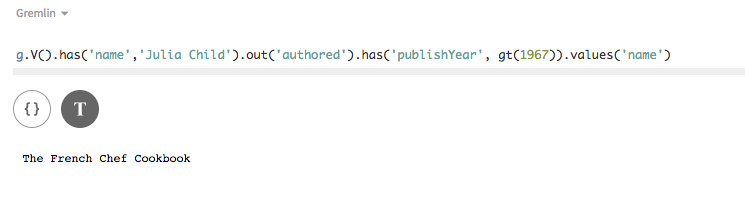 and in Gremlin console:
and in Gremlin console:==>The French Chef Cookbook ==>1968 -
When developing or testing, oftentimes checking the number of vertices with each vertex label can confirm that data was read. To find the number of vertices by vertex label, use the traversal step
label()followed by the traversal stepgroupCount(). The stepgroupCount()is useful for aggregating results from a previous step. Suppress the warning by prependingg.with("label-warning", false).instead ofg.:g.V().label().groupCount()In Studio:
and in Gremlin console:
==>{meal=8, meal_item=3, ingredient=31, person=15, book=4, recipe=8, fridge_sensor=9, location=16, store=3, home=3}
QuickStart Writing and reading data
Writing and reading graph data.
About this task
Writing data from DataStax Graph to a file is most easily accomplished with the g.io() command.
Procedure
-
Write your data to an output file to save or exchange information using the GraphSON format, a variation of JSON:
g.io("/tmp/food_qs.json").write()g.io()is disabled in sandbox mode.In Studio:

-
Read your data from an output file to exchange information using the GraphSON format:
g.io("/tmp/food_qs.json").read()In Studio:

QuickStart Listing graphs
How to list graphs.
About this task
Discover information about all the graphs on a cluster with the system commands.
|
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with |
Procedure
-
To discover all graphs that exist, use a system command:
system.graphs()
In Studio:

In Gremlin console:
==>food_qs -
To discover information about all the graphs that exist:
system.list()In Studio:

In Gremlin console:
==>Name: food_qs | Engine: Core | Replication: {SearchGraph=1, class=org.apache.cassandra.locator.NetworkTopologyStrategy}
QuickStart Modifying schema
Modify graph schema.
About this task
Schema can be modified after creation, adding properties with addProperty() and alter() and dropping any element, property, vertex label, edge label, or index with drop().
Edge label alterations can additionally specify the pair of vertex labels on which the modification is accomplished.
The data type of a property, however, cannot be changed, without removing and recreating the property.
In addition, metadata about the vertex labels and edge labels can be dropped. If a vertex label’s metadata is dropped, the underlying table remains, but the label is removed along with any associated edge tables. Similarly, if an edge label’s metadata is dropped, the underlying edge label tables remain, but the connections to any vertex labels are dropped. Dropping all metadata removes all vertex labels and edge labels, but the underlying CQL tables remain, but are not associated with the graph.
Procedure
-
Drop properties
-
Drop the edge property:
schema.edgeLabel('authored'). dropProperty('one'). dropProperty('two'). alter()or if you want to drop a property on an edge label for a specific connection between two vertex labels:
schema.edgeLabel('authored'). from('person'). to('book'). dropProperty('one'). dropProperty('two'). alter()The latter variation is useful when an edge label is defined between more than one set of vertex labels. For instance, if both
person->authored->bookandperson->authored->blogexisted, then the expanded command would only drop the properties fromperson->authored->book. -
Drop vertex labels, edge labels, or indexes
-
Drop a particular index:
schema.vertexLabel('person'). materializedView('person_by_gender'). ifExists(). drop()See Dropping graph schema for complete information.
-
Drop a property from a search index:
schema.vertexLabel('store'). searchIndex(). dropProperty('name'). alter() -
Drop a particular vertex label:
schema.vertexLabel('person'). ifExists(). drop()Edge labels can be dropped similarly. See Dropping graph schema for complete information.
-
Drop metadata
-
Drop all metadata for all vertex labels and edge labels:
schema.dropMetadata()
Increase your knowledge
For more information about traversing, see Creating queries using traversals. Also study Indexing carefully. If you want to explore various loading options, check out DataStax Bulk Loader.
DataStax also hosts a DataStax Graph self-paced course on DataStax Academy; register for a free account to access the course.
