QuickStart Introduction
QuickStart Introduction
Graph databases are useful for discovering simple and complex relationships between objects. Relationships are fundamental to how objects interact with one another and their environment. Apache Cassandra can store large distributed datasets, and DataStax Graph (DSG) is Graph for Apache Cassandra. DSG allows Apache Cassandra data to be traversed with complex queries that are not possible with the Cassandra Query Language (CQL) or are the equivalent of multiple SQL JOINS required in a traditional RDBMS.
This QuickStart explores DSG from a data model that leads to schema, inserting data, and simple queries that show off the power of graph databases. Starting with DSG 6.8, the same data can be queried with either Gremlin or CQL, increasing the useability of the same data for different uses. However, for this QuickStart, we’ll use Gremlin as the main language of interaction.We’ll start by discussing what a graph database actually is.
Graph databases consist of three elements:
-
vertex
A vertex is an object, such as a person, location, automobile, recipe, or anything else you can think of as nouns.
-
edge
An edge defines the relationship between two vertices. A person can create software, or an author can write a book. Typically an edge is equivalent to a verb.
-
property
A key-value pair that describes some attribute of either a vertex or an edge. A property key is used to describe the key in the key-value pair.
Vertices, edges, and properties can have properties; for this reason, DataStax Graph is classified as a property graph. The properties for elements are an important element of storing and querying information in a property graph.
Property graphs are typically quite large, although the nature of querying the graph varies depending on whether the graph has large numbers of vertices, edges, or both vertices and edges. To get started with graph database concepts, a toy graph is used for simplicity. The example used here explores the world of food.
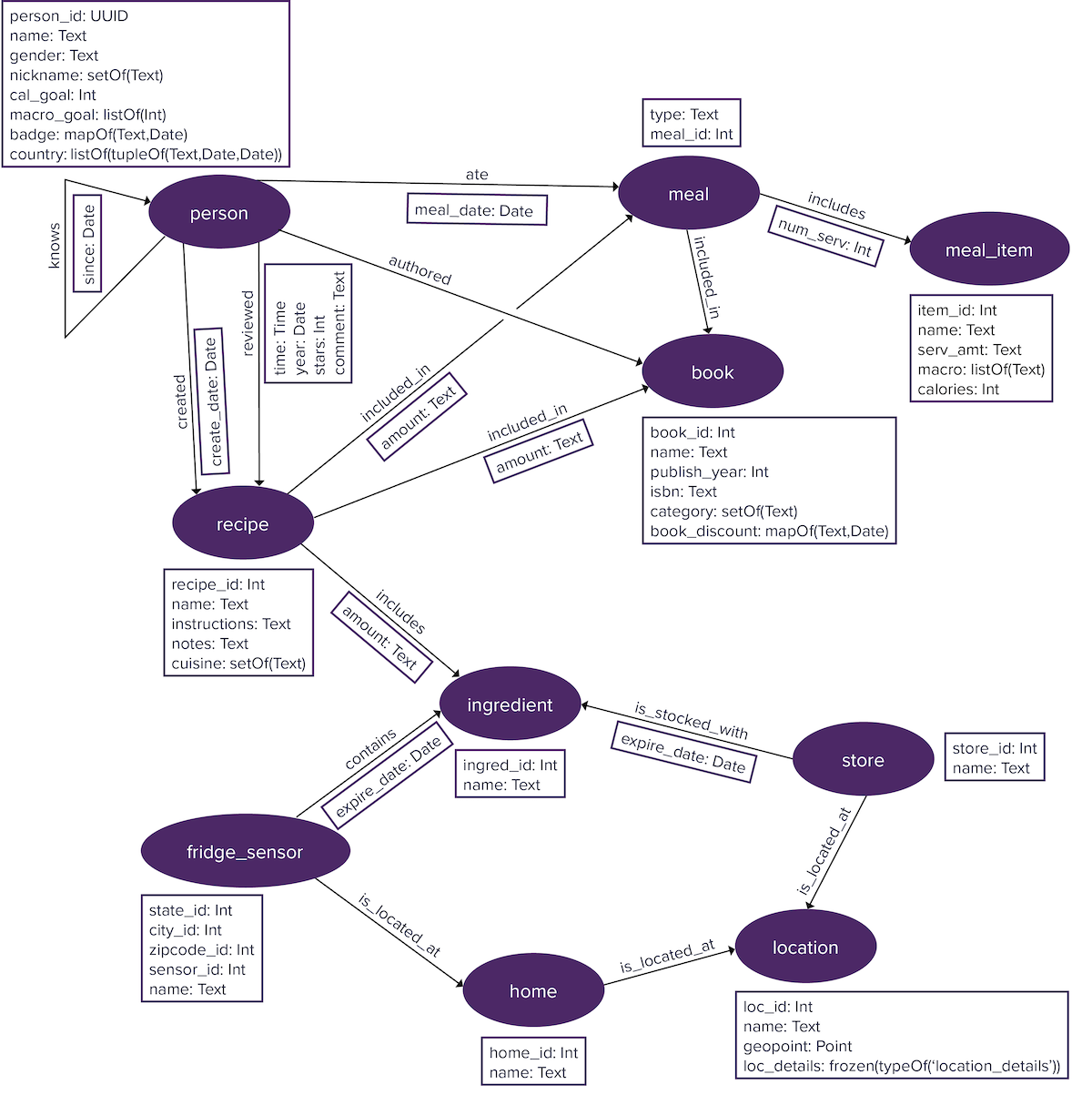
Elements are labeled to distinguish the type of vertices and edges in a graph database using vertex labels and edge labels. A vertex labeled person holds information about an author or reviewer or someone who ate a meal. An edge between an person and a book is labeled authored. Specifying appropriate labels is an important step in graph data modeling.
Vertices and edges generally have properties. For instance, a person vertex can have properties name and gender. Edges can also have properties. A created edge can have a create_date property that identifies when the adjoining recipe vertex was created.
Information in a graph database is retrieved using graph traversals. Graph traversals walk a graph with a single or series of traversal steps from a defined starting point and filter each step until returning a result.
